![Схема автоматической разметки данных. Источник: [115]](/EDI/18_12_24_2/1734474022-28631/tutorial/963/objects/3/files/03-05.jpg)
|
Не удается заказать доставку сертификата ни в pdf - ни в бумажном виде, сайт выдает окно с сообщением "Ошибка" и сразу его закрывает. |
Опубликован: 30.05.2023 | Доступ: свободный | Студентов: 1888 / 990 | Длительность: 16:08:00
Лекция 4:
ИИ как экосистема, бизнес и рынок
< Лекция 3 || Лекция 4: 1234567891011121314151617181920212223242526272829303132333435363738394041424344454647 || Лекция 5 >
Развертывание и мониторинг
Модели ИИ должны быть развернуты на оборудовании, оптимизированном под ИИ-нагрузку. Это могут быть внутренние ресурсы предприятия, периферийные узлы или облачная инфраструктура. При этом следует отметить, что обычно специальное аппаратное обеспечение требуется только для обучения, но не для применения. Бывают, конечно, требовательные к ресурсам модели, но это скорее редкость. Особенно в промышленности.
После развертывания модели требуется ее поддержка в условиях производства, где модель взаимодействует с реальными наборами данных. Часть проблем выявляется именно на стадии использования модели. Часто обученные модели деградируют во времени, поскольку найденные в исторических данных закономерности устаревают. Здесь нужно упомянуть такое понятие как Data Drift - ситуация, при которой из-за каких то внешних причин постепенно меняется характер входных данных модели, из-за чего снижаютсяее эффективность и точность прогнозирования. Соответственно, отдельное внимание требуется для обнаружения подобных проблем и их устранения на основе периодического дообучения модели на более свежих наборах данных.
Распределение ресурсов и времени в типовом ИИ-проекте
Для того чтобы представить трудоемкость отдельных этапов типового ИИ-проекта, полезно обратиться к статистическим данным. Подобную статистику можно найти в публикациях аналитической компании Cognilytica, специализирующейся в области изучения ИИ-рынка (см. рис. 3.4).
Как видно из сравнения рисунков (рис. 3.1 - рис. 3.4), пока не существует общепринятой таксономии в описании этапов ИИ-проектов, разные аналитики используют свое деление и наименования, при этом нетрудно наложить одну терминологию на другую.
В отличие от схемы Labelyourdata (рис. 3.1), Cognilytica не рассматривает этап "формулирования проблемы" и "бизнес-анализа проекта", а начинает цикл типового проекта непосредственно со стадии анализа и сбора данных (рис. 3.4).
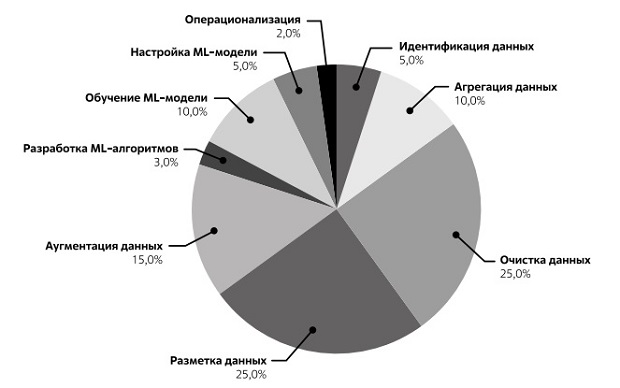
Рис. 3.4. Соотношение временных затрат на выполнение ключевых этапов типового ИИ-ML-проекта. Источник: Cognilytica
Первым шагом (согласно рис. 3.4) рассматривается процесс идентификации данных, который, как показано на рисунке, занимает около 5%. На данном этапе идет определение источников данных, которые будут использоваться для обучения разрабатываемой модели.
Говоря о задачах, связанных с распознаванием изображений, можно использовать разные источники. Если область распознавания не является узкоспециализированной, то можно воспользоваться свободно распространяемыми общедоступными датасетами, что позволяет экономить деньги и время.
Если готовых датасетов для рассматриваемой задачи нет - создаются собственные, которые (в случае если речь идет о распознавании изображений) могут быть получены с помощью веб-скреппинга 3Веб-скрепинг (от англ. web scraping) - технология получения веб-данных путем извлечения их со страниц веб-ресурсов вручную или автоматически. Чаще термин относится к автоматизированным процессам, реализованным с помощью кода, который выполняет запросы на целевой сайт, с помощью фотоаппаратов, мобильных телефонов, камеры видео-наблюдения и т. д. Существуют специализированные компании, которые профессионально выполняют подобные работы на коммерческой основе.
Следующий этап, который занимает около 10%, - это агрегация данных. Поскольку данные поступают из разных источников или находятся в разных местах хранения, то на этапе агрегации, перед тем как с данными можно будет производить какие-то действия, они должны быть объединены в одной базе данных. При этом производится необходимое переформатирование данных, приведение их к единому виду. Работа достаточно рутинная, но необходимая, поскольку требуется разобраться, где какие данные находятся, в каком формате и что необходимо выбрать.
Этап очистки - один из наиболее длительных - 25%. Важность данного этапа характеризует популярная фраза "garbage in, garbage out" (мусор на входе - мусор на выходе). В данных могут содержаться ошибки. Например, пропуски значений, ошибочные записи, выбросы, несогласованные данные. Очистка данных подразумевает выявление и удаление ошибок и несоответствий в данных с целью улучшения качества датасета.
Разметка данных - это процесс идентификации необработанных данных (изображений, текстовых файлов, видео и т. д.) и добавления меток, на основе которых модель могла бы обучаться в терминах задачи обучения с учителем. Данный этап также длительный и требует порядка 25% времени. В рассмотренных нами в первой лекции примерах речь шла про метки, указывающие, изображена ли на фотографии кошка или собака, метки могут указывать, есть ли на рентгеновском снимке опухоль и где она расположена, есть ли на фотографии шлифа трещина, присутствует ли в аудиозаписи определенное слово и так далее. Разметка данных - это трудоемкий процесс. Массив данных может содержать десятки тысяч сэмплов, и вручную произвести процедуру разметки порой просто невозможно.
Проекты, связанные с распознаванием объектов или изображений, в том числе в приложениях для беспилотного транспорта, становятся все более распространенными рабочими нагрузками и требуют все больше усилий по разметке данных. Для выполнения этой работы все чаще используется автоматизация, опять-таки основанная на машинном обучении. По данным компании Cognilytica, к 2024 году более 30% текущих задач по разметке данных будут автоматизированы или выполняться системами искусственного интеллекта. На рынке существуют специализированные программы для разметки данных, позволяющие осуществлять детекцию и сегментацию объектов, классифицировать документы.
Во многих проектах процесс создания обучающих данных - это длительная и затратная процедура. Часто для решения задач подготовки данных имеет смысл обратиться к профильным компаниям, имеющим средства автоматизации, играющие решающее значение для соблюдения сроков проекта 4Следует отметить, что существуют также работы по интеграции модели в информационную систему. Эти работы могут занимать не меньше времени, чем подготовка данных. - Примечание научного редактора .
Для того чтобы сделать разметку более эффективной, используют модели машинного обучения для автоматической маркировки данных, которые сначала обучаются на подмножестве исходных данных, размеченных человеком, а потом автоматически предсказывают метки для новых данных (рис. 3.5).
В тех случаях, когда модель разметки менее уверена в своих результатах, она передает данные человеку. Созданные человеком метки затем возвращаются обратно в модель разметки, чтобы она могла учиться и улучшать свои возможности по автоматической разметке следующего набора исходных данных. Со временем модель позволяет автоматически размечать все больше и больше данных.
< Лекция 3 || Лекция 4: 1234567891011121314151617181920212223242526272829303132333435363738394041424344454647 || Лекция 5 >