Московский государственный университет имени М.В.Ломоносова
Опубликован: 15.03.2007 | Доступ: свободный | Студентов: 618 / 29 | Оценка: 5.00 / 4.50 | Длительность: 19:30:00
Специальности: Программист
Лекция 12:
Быстрые квантовые алгоритмы
Аннотация: В лекции приводится "задача о скрытой подгруппе", дается ее решение, рассмотрен квантовый алгоритм для решения задачи о нахождении периода числа, описан процесс построения измеряющего оператора.
Ключевые слова: алгоритм, черный ящик, вычислительная задача, подгруппа, группа, представление, линейная комбинация, скалярное произведение, дискретный логарифм, NP, делитель, вычет, факторизация числа, четность, алгоритм Евклида, базисными векторами, собственное число, собственный вектор, условная вероятность, рациональное число, числитель, формула полной вероятности, испытание Бернулли, первообразный корень, свертка
Единственное нетривиальное использование квантовых свойств для вычислений, которое мы уже рассмотрели, — это решение универсальной переборной задачи алгоритмом Гровера, изложенным в
"Определение квантового вычисления. Примеры"
. К сожалению, при этом достигается лишь полиномиальное ускорение. Поэтому никаких серьезных следствий для теории сложности вычислений (типа 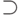 ) алгоритм Гровера не дает. В настоящее время нет доказательства того, что квантовые вычисления превосходят по скорости классические вероятностные. Но есть косвенные свидетельства в пользу такого утверждения. Первое из них — пример задачи с оракулом (т.е. процедурой типа "черного ящика"), для которой существует полиномиальный квантовый алгоритм, в то время как любой классический вероятностный алгоритм экспоненциален1Следует иметь в виду, что сложность задач с оракулом часто отличается от сложности обычных вычислительных задач. Классический пример — теорема о том, что
) алгоритм Гровера не дает. В настоящее время нет доказательства того, что квантовые вычисления превосходят по скорости классические вероятностные. Но есть косвенные свидетельства в пользу такого утверждения. Первое из них — пример задачи с оракулом (т.е. процедурой типа "черного ящика"), для которой существует полиномиальный квантовый алгоритм, в то время как любой классический вероятностный алгоритм экспоненциален1Следует иметь в виду, что сложность задач с оракулом часто отличается от сложности обычных вычислительных задач. Классический пример — теорема о том, что  [36, 37]. Оракульный аналог этого утверждения неверен [30]!
. Этот пример, построенный Д. Саймоном [42], называется задачей о скрытой подгруппе в
[36, 37]. Оракульный аналог этого утверждения неверен [30]!
. Этот пример, построенный Д. Саймоном [42], называется задачей о скрытой подгруппе в 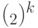 . В дальнейшем мы решим также задачу о скрытой подгруппе в
. В дальнейшем мы решим также задачу о скрытой подгруппе в  , обобщающую все результаты из этого раздела.
, обобщающую все результаты из этого раздела.
Задача о скрытой подгруппе. Пусть 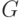 — конечная группа, причем задано некоторое представление элементов двоичными словами. Имеется устройство ( оракул ), вычисляющее функцию
— конечная группа, причем задано некоторое представление элементов двоичными словами. Имеется устройство ( оракул ), вычисляющее функцию 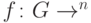 со следующим свойством:
со следующим свойством:
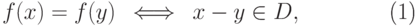 |
( 12.1) |
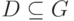 — некоторая заранее неизвестная подгруппа. Нужно найти эту подгруппу.
— некоторая заранее неизвестная подгруппа. Нужно найти эту подгруппу.Задача о скрытой подгруппе в .
Мы рассмотрим сформулированную выше задачу в случае  . Элементы этой группы
. Элементы этой группы
можно представлять строками длины 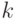 из нулей и единиц; групповая операция — побитовое сложение по модулю 2.
из нулей и единиц; групповая операция — побитовое сложение по модулю 2.
Легко доказать, что нельзя быстро найти "скрытую подгруппу" на классической вероятностной машине. (Классическая машина посылает на вход "черного ящика" строки 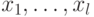 и получает ответы
и получает ответы 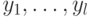 . Каждый следующий вопрос
. Каждый следующий вопрос 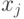 зависит от предыдущих ответов
зависит от предыдущих ответов 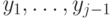 и некоторого случайного числа
и некоторого случайного числа 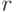 .)
.)
Утверждение 12.1. Пусть  . Для любого классического вероятностного алгоритма, делающего не более
. Для любого классического вероятностного алгоритма, делающего не более 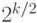 обращений к оракулу, существует подгруппа
обращений к оракулу, существует подгруппа  и соответствующая функция
и соответствующая функция 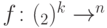 , для которой алгоритм ошибается с вероятностью
, для которой алгоритм ошибается с вероятностью 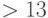 .
.
Доказательство. Для одной и той же подгруппы 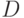 существует несколько различных оракулов
существует несколько различных оракулов  . Мы будем считать, что один из них выбирается случайно и равновероятно. (Если алгоритм ошибается с вероятностью при случайном оракуле, то он также будет ошибаться с вероятностью при каком-нибудь конкретном оракуле.) Случайный оракул обладает следующим свойством: если очередной ответ
. Мы будем считать, что один из них выбирается случайно и равновероятно. (Если алгоритм ошибается с вероятностью при случайном оракуле, то он также будет ошибаться с вероятностью при каком-нибудь конкретном оракуле.) Случайный оракул обладает следующим свойством: если очередной ответ  не совпадает ни с одним из предыдущих ответов , то он равномерно распределен на множестве
не совпадает ни с одним из предыдущих ответов , то он равномерно распределен на множестве 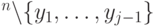 . Таким образом, случайный оракул эквивалентен устройству с памятью, которое на вопрос выдает наименьшее число
. Таким образом, случайный оракул эквивалентен устройству с памятью, которое на вопрос выдает наименьшее число  , такое что
, такое что 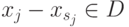 . Классическую машину можно изменить таким образом, что она сама будет производить случайный выбор
. Классическую машину можно изменить таким образом, что она сама будет производить случайный выбор 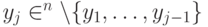 , когда
, когда  .
.
Пусть число вопросов к оракулу равно 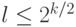 . Без уменьшения общности все вопросы различны. В случае
. Без уменьшения общности все вопросы различны. В случае 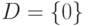 все ответы также различны, то есть для всех
все ответы также различны, то есть для всех 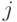 . Теперь рассмотрим случай
. Теперь рассмотрим случай 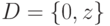 , где
, где 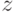 выбирается случайно с равномерным распределением на множестве всех ненулевых элементов группы . Тогда, независимо от используемого алгоритма, c вероятностью
выбирается случайно с равномерным распределением на множестве всех ненулевых элементов группы . Тогда, независимо от используемого алгоритма, c вероятностью 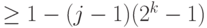 . С вероятностью
. С вероятностью  это имеет место для всех
это имеет место для всех 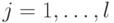 . Напомним, что у нас есть два случайных параметра: и . Мы можем зафиксировать таким образом, чтобы вероятность получения ответов (для всех ) по-прежнему была больше
. Напомним, что у нас есть два случайных параметра: и . Мы можем зафиксировать таким образом, чтобы вероятность получения ответов (для всех ) по-прежнему была больше 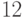 . Посмотрим, что будет делать классическая машина в этом случае. Если она выдает ответ " " с вероятностью
. Посмотрим, что будет делать классическая машина в этом случае. Если она выдает ответ " " с вероятностью 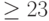 , положим
, положим 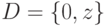 — тогда выдаваемый ответ будет неверным с вероятностью
— тогда выдаваемый ответ будет неверным с вероятностью 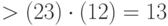 . Если же вероятность ответа " " меньше
. Если же вероятность ответа " " меньше 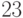 , положим .
, положим .
Теперь определим квантовый аналог описанного выше устройства. Соответствующий квантовый оракул — это унитарный оператор
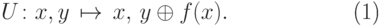 |
( 12.2) |
 обозначает побитовое сложение). Заметим, что квантовый оракул допускает линейные комбинации разных вопросов, поэтому его можно использовать более эффективно, чем классический оракул.
обозначает побитовое сложение). Заметим, что квантовый оракул допускает линейные комбинации разных вопросов, поэтому его можно использовать более эффективно, чем классический оракул.Пусть  , а
, а 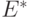 — группа характеров на
— группа характеров на 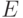 , т.е. гомоморфизмов
, т.е. гомоморфизмов 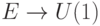 . В случае группу можно охарактеризовать следующим образом:
. В случае группу можно охарактеризовать следующим образом:
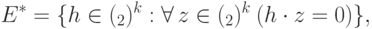
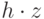 обозначает скалярное произведение по модулю 2. (Соответствующий
обозначает скалярное произведение по модулю 2. (Соответствующий 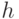 характер имеет вид
характер имеет вид  .) Покажем, как можно породить случайный элемент
.) Покажем, как можно породить случайный элемент 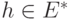 , используя оператор
, используя оператор 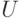 . Породив достаточно много случайных элементов, мы найдем группу , и, тем самым, исходную подгруппу D.
. Породив достаточно много случайных элементов, мы найдем группу , и, тем самым, исходную подгруппу D.Начнем с того, что приготовим состояние  в одном квантовом регистре. Во второй регистр поместим состояние
в одном квантовом регистре. Во второй регистр поместим состояние 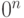 и применим оператор . Затем выбросим второй регистр, т.е. не будем его больше использовать. Получится смешанное состояние
и применим оператор . Затем выбросим второй регистр, т.е. не будем его больше использовать. Получится смешанное состояние
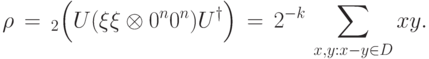
 :
: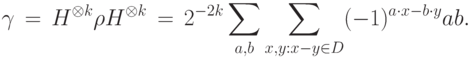
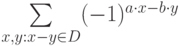 отлична от нуля только в том случае, когда
отлична от нуля только в том случае, когда 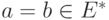 . Таким образом,
. Таким образом, . Теперь осталось воспользоваться следующей леммой, которую мы сформулируем в виде задачи.
. Теперь осталось воспользоваться следующей леммой, которую мы сформулируем в виде задачи.Задача 12.1. Пусть 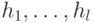 — независимые случайные равномерно распределенные элементы абелевой группы
— независимые случайные равномерно распределенные элементы абелевой группы 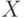 . Докажите, что они порождают всю группу c
вероятностью
. Докажите, что они порождают всю группу c
вероятностью  .
.
Таким образом, достаточно 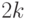 случайных элементов, чтобы породить всю группу с вероятностью ошибки
случайных элементов, чтобы породить всю группу с вероятностью ошибки 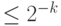 . (Такая маленькая вероятность ошибки получается без особых затрат по сравнению с
. (Такая маленькая вероятность ошибки получается без особых затрат по сравнению с 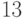 . Чтобы сделать ее еще меньше, эффективнее всего воспользоваться стандартной процедурой: повторить все вычисление несколько раз и выбрать наиболее часто встречающийся ответ).
. Чтобы сделать ее еще меньше, эффективнее всего воспользоваться стандартной процедурой: повторить все вычисление несколько раз и выбрать наиболее часто встречающийся ответ).
Подведем итог: для нахождения "скрытой подгруппы" требуется 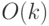 обращений к квантовому оракулу. В целом алгоритм имеет сложность
обращений к квантовому оракулу. В целом алгоритм имеет сложность 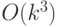 .
.