Опубликован: 28.07.2007 | Доступ: свободный | Студентов: 2055 / 520 | Оценка: 4.53 / 4.26 | Длительность: 25:10:00
ISBN: 978-5-9556-0096-3
Специальности: Программист
Лекция 6:
Параллельные методы умножения матрицы на вектор
6.5.5. Результаты вычислительных экспериментов
Рассмотрим результаты вычислительных экспериментов, выполненных для оценки эффективности приведенного выше параллельного алгоритма умножения матрицы на вектор. Кроме того, используем полученные результаты для сравнения теоретических оценок и экспериментальных показателей времени вычислений и проверим тем самым точность полученных аналитических соотношений. Эксперименты проводились на вычислительном кластере Нижегородского университета на базе процессоров Intel Xeon 4 EM64T, 3000 МГц и сети Gigabit Ethernet под управлением операционной системы Microsoft Windows Server 2003 Standard x64 Edition и системы управления кластером Microsoft Compute Cluster Server (см. п. 1.2.3).
Определение параметров теоретических зависимостей (величин 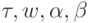 ) осуществлялось следующим
образом. Для оценки длительности
) осуществлялось следующим
образом. Для оценки длительности 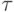 базовой скалярной операции
проводилось решение задачи умножения матрицы на вектор при помощи
последовательного алгоритма и полученное таким образом время
вычислений делилось на общее количество выполненных операций – в
результате подобных экспериментов для величины было
получено значение 1,93 нсек. Эксперименты, выполненные для
определения параметров сети передачи данных, показали значения
латентности
базовой скалярной операции
проводилось решение задачи умножения матрицы на вектор при помощи
последовательного алгоритма и полученное таким образом время
вычислений делилось на общее количество выполненных операций – в
результате подобных экспериментов для величины было
получено значение 1,93 нсек. Эксперименты, выполненные для
определения параметров сети передачи данных, показали значения
латентности  и пропускной способности
и пропускной способности  соответственно 47 мкс и 53,29 Мбайт/с. Все вычисления
производились над числовыми значениями типа double,
т.е. величина w равна 8 байт.
соответственно 47 мкс и 53,29 Мбайт/с. Все вычисления
производились над числовыми значениями типа double,
т.е. величина w равна 8 байт.
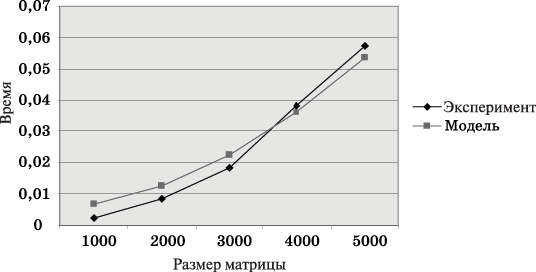
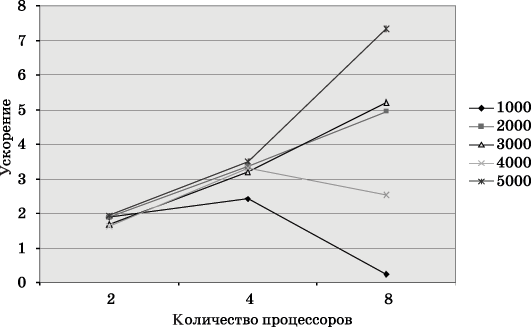
Результаты вычислительных экспериментов приведены в таблице 6.1. Эксперименты проводились с использованием двух, четырех и восьми процессоров. Времена выполнения алгоритмов указаны в секундах.
Сравнение экспериментального времени 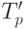 выполнения параллельного алгоритма и теоретического времени Tp, вычисленного в соответствии с
выражением (6.8), представлено в
таблице 6.2 и в графическом
виде на рис. 6.3 и
6.4.
выполнения параллельного алгоритма и теоретического времени Tp, вычисленного в соответствии с
выражением (6.8), представлено в
таблице 6.2 и в графическом
виде на рис. 6.3 и
6.4.
| Размер объектов | 2 процессора | 4 процессора | 8 процессоров | |||
|---|---|---|---|---|---|---|
| Tp | T'p | Tp | T'p | Tp | T'p | |
| 1000 | 0,0069 | 0,0021 | 0,0108 | 0,0017 | 0,0152 | 0,0175 |
| 2000 | 0,0132 | 0,0084 | 0,0140 | 0,0047 | 0,0169 | 0,0032 |
| 3000 | 0,0235 | 0,0185 | 0,0193 | 0,0097 | 0,0196 | 0,0059 |
| 4000 | 0,0379 | 0,0381 | 0,0265 | 0,0188 | 0,0233 | 0,0244 |
| 5000 | 0,0565 | 0,0574 | 0,0359 | 0,0314 | 0,0280 | 0,0150 |