Опубликован: 28.07.2007 | Доступ: свободный | Студентов: 2062 / 523 | Оценка: 4.53 / 4.26 | Длительность: 25:10:00
ISBN: 978-5-9556-0096-3
Специальности: Программист
Лекция 9:
Параллельные методы сортировки
Аннотация: В лекции рассматриваются различные алгоритмы
сортировки данных. Излагаются как общие принципы, применяемые при
распараллеливании, так и конкретные алгоритмы. Теоретически
оценивается эффективность рассматриваемых алгоритмов. Приводятся
и анализируются результаты вычислительных
экспериментов
Ключевые слова: сортировка, упорядочивание данных, пузырьковая сортировка, быстрая сортировка, выражение, ускорение, анализ, операция "сравнить и переставить", эффективность, EM64T, computer cluster, вычислительный эксперимент, операции передачи данных, алгоритм Шелла, топология сети передачи данных, обобщенная быстрая сортировка, сортировка с использованием регулярного набора образцов
Сортировка является одной из типовых проблем обработки данных и обычно понимается как задача размещения элементов неупорядоченного набора значений
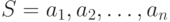
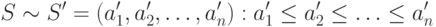
Возможные способы решения этой задачи широко обсуждаются в литературе; один из наиболее полных обзоров алгоритмов сортировки содержится в работе [ [ 50 ] ], среди последних изданий может быть рекомендована работа [ [ 26 ] ].
Вычислительная трудоемкость процедуры упорядочивания является достаточно высокой. Так, для ряда известных простых методов ( пузырьковая сортировка, сортировка включением и др.) количество необходимых операций определяется квадратичной зависимостью от числа упорядочиваемых данных
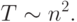
Для более эффективных алгоритмов ( сортировка слиянием, сортировка Шелла, быстрая сортировка ) трудоемкость определяется
величиной 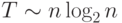 .
.
Данное выражение дает также нижнюю оценку необходимого количества операций для упорядочивания набора из n значений; алгоритмы с меньшей трудоемкостью могут быть получены только для частных вариантов задачи.
Ускорение сортировки может быть обеспечено при использовании нескольких (p>1) процессоров. Исходный упорядочиваемый набор в этом случае разделяется между процессорами; в ходе сортировки данные пересылаются между процессорами и сравниваются между собой. Результирующий (упорядоченный) набор, как правило, также разделен между процессорами; при этом для систематизации такого разделения для процессоров вводится та или иная система последовательной нумерации и обычно требуется, чтобы при завершении сортировки значения, располагаемые на процессорах с меньшими номерами, не превышали значений процессоров с большими номерами.
Оставляя подробный анализ проблемы сортировки для отдельного рассмотрения, здесь основное внимание мы уделим изучению параллельных способов выполнения для ряда широко известных методов внутренней сортировки, когда все упорядочиваемые данные могут быть размещены полностью в оперативной памяти ЭВМ.
9.1. Принципы распараллеливания
При внимательном рассмотрении способов упорядочивания данных, применяемых в алгоритмах сортировки, можно заметить, что многие методы основаны на применении одной и той же базовой операции "сравнить и переставить" ( compare-exchange ), состоящей в сравнении той или иной пары значений из сортируемого набора данных и перестановке этих значений, если их порядок не соответствует условиям сортировки.
Пример 9.1. Операция "сравнить и переставить"
// Базовая операция "сравнить и переставить"
if ( A[i] > A[j] ) {
temp = A[i];
A[i] = A[j];
A[j] = temp;
}Целенаправленное применение данной операции позволяет упорядочить данные; в способах выбора пар значений для сравнения, собственно, и проявляется различие алгоритмов сортировки.
Для параллельного обобщения выделенной базовой операции сортировки рассмотрим первоначально ситуацию, когда количество процессоров совпадает с числом сортируемых значений (т. е. p=n ) и на каждом из процессоров содержится только по одному значению исходного набора данных. Тогда сравнение значений ai и aj, располагаемых соответственно на процессорах Pi и Pj, можно организовать следующим образом (параллельное обобщение базовой операции сортировки ):
- выполнить взаимообмен имеющихся на процессорах Pi и Pj значений (с сохранением на этих процессорах исходных элементов);
- сравнить на каждом процессоре Pi и Pj получившиеся одинаковые
пары значений ( ai, aj ); результаты сравнения используются для
разделения данных между процессорами – на одном процессоре
(например, Pi ) остается меньший элемент, другой процессор (т. е. Pj ) запоминает для дальнейшей обработки большее значение
пары
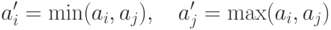
9.2. Масштабирование параллельных вычислений
Рассмотренное параллельное обобщение базовой операции сортировки может быть надлежащим образом адаптировано и для случая p<n, когда количество процессоров меньше числа упорядочиваемых значений. В данной ситуации каждый процессор будет содержать уже не единственное значение, а часть (блок размера n/p ) сортируемого набора данных.
Определим в качестве результата выполнения параллельного алгоритма сортировки такое состояние упорядочиваемого набора данных, при котором имеющиеся на процессорах данные упорядочены, а порядок распределения блоков по процессорам соответствует линейному порядку нумерации (т. е. значение последнего элемента на процессоре Pi меньше значения первого элемента на процессоре Pi+1, где 0<=i<p-1 или равно ему).
Блоки обычно упорядочиваются в самом начале сортировки на каждом процессоре в отдельности при помощи какого-либо быстрого алгоритма (начальная стадия параллельной сортировки ). Далее, следуя схеме одноэлементного сравнения, взаимодействие пары процессоров Pi и Pi+1 для совместного упорядочения содержимого блоков Ai и Ai+1 может быть осуществлено следующим образом:
- выполнить взаимообмен блоков между процессорами Pi и Pi+1 ;
- объединить блоки Ai и Ai+1 на каждом процессоре в один отсортированный блок двойного размера (при исходной упорядоченности блоков Ai и Ai+1 процедура их объединения сводится к быстрой операции слияния упорядоченных наборов данных);
- разделить полученный двойной блок на две равные части и
оставить одну из этих частей (например, с меньшими значениями
данных) на процессоре Pi, а другую часть (с большими значениями,
соответственно) – на процессоре Pi+1
![[A_i \cup A_{i+1}]_{\textit{сорт}}=A'_i \cup a'_{i+1}:
\forall a'_i, \in A'_i, \; \forall a'_j \in A'_{i+1} \Rightarrow a'_i \le a'_j .](/sites/default/files/tex_cache/d180f1643d38fb5262fba13f680a2d55.png)
Рассмотренная процедура обычно именуется в литературе операцией "сравнить и разделить" ( compare-split ). Следует отметить, что сформированные в результате такой процедуры блоки на процессорах Pi и Pi+1 совпадают по размеру с исходными блоками Ai и Ai+1 и все значения, расположенные на процессоре Pi, не превышают значений на процессоре Pi+1.
Определенная выше операция "сравнить и разделить" может быть использована в качестве базовой подзадачи для организации параллельных вычислений. Как следует из построения, количество таких подзадач параметрически зависит от числа имеющихся процессоров, и, таким образом, проблема масштабирования вычислений для параллельных алгоритмов сортировки практически отсутствует. Вместе с тем следует отметить, что относящиеся к подзадачам блоки данных изменяются в ходе выполнения сортировки. В простых случаях размер блоков данных в подзадачах остается неизмененным. В более сложных ситуациях (как, например, в алгоритме быстрой сортировки – см. подраздел 9.5) объем располагаемых на процессорах данных может различаться, что может приводить к нарушению равномерной вычислительной загрузки процессоров.