Опубликован: 28.07.2007 | Доступ: свободный | Студентов: 2062 / 523 | Оценка: 4.53 / 4.26 | Длительность: 25:10:00
ISBN: 978-5-9556-0096-3
Специальности: Программист
Лекция 10:
Параллельные методы на графах
Аннотация: В лекции рассматриваются различные типовые
задачи, возникающие при обработке графов. Приводятся алгоритмы,
применяемые для решения этих задач, и обсуждаются пути их
распараллеливания. Дается теоретическая оценка эффективности
рассматриваемых алгоритмов. Анализируются результаты
вычислительных экспериментов
Ключевые слова: граф, множества, список, представление, матрица, алгоритм Флойда, операции передачи данных, EM64T, computer cluster, алгоритм Прима, каскадная схема, задача оптимального разделения графов, система с распределенной памятью, ускорение и эффективность параллельных вычислений, задача поиска всех кратчайших путей, задача нахождения минимального охватывающего дерева, геометрические и комбинаорные алгоритмы разделения графов
Математические модели в виде графов широко используются при моделировании разнообразных явлений, процессов и систем. Как результат, многие теоретические и реальные прикладные задачи могут быть решены при помощи тех или иных процедур анализа графовых моделей. Среди множества этих процедур может быть выделен некоторый определенный набор типовых алгоритмов обработки графов. Рассмотрению вопросов теории графов, алгоритмов моделирования, анализу и решению задач на графах посвящено достаточно много различных изданий, в качестве возможного руководства по данной тематике может быть рекомендована работа [ [ 26 ] ].
G=(V,R),
для которого набор вершин Vi, 0<=i<=n, задается множеством V, а список дуг графа
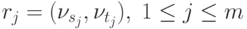
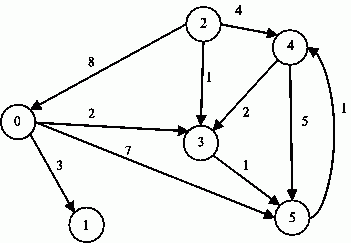
Известны различные способы задания графов. При малом количестве дуг в графе (т. е. m<<n2 ) целесообразно использовать для определения графов списки, перечисляющие имеющиеся в графах дуги. Представление достаточно плотных графов, для которых почти все вершины соединены между собой дугами (т. е. m~n2 ), может быть эффективно обеспечено при помощи матрицы смежности:
A=(aij), 1<=i, j<=n,
ненулевые значения элементов которой соответствуют дугам графа:
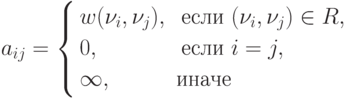
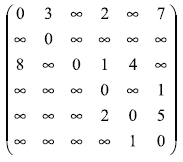
Как положительный момент такого способа представления графов можно отметить, что использование матрицы смежности позволяет применять при реализации вычислительных процедур анализа графов матричные алгоритмы обработки данных.
Далее мы рассмотрим способы параллельной реализации алгоритмов на графах на примере задачи поиска кратчайших путей между всеми парами пунктов назначения и задачи выделения минимального охватывающего дерева ( остова ) графа. Кроме того, мы рассмотрим задачу оптимального разделения графов, широко используемую для организации параллельных вычислений. Для представления графов при рассмотрении всех перечисленных задач будут применяться матрицы смежности.
10.1. Задача поиска всех кратчайших путей
Исходной информацией для задачи является взвешенный граф G=(V,R), содержащий n вершин (|V|=n), в котором каждому ребру графа приписан неотрицательный вес. Граф будем полагать ориентированным, т.е. если из вершины i есть ребро в вершину j, то из этого не следует наличие ребра из j в i. В случае если вершины все же соединены взаимообратными ребрами, веса, приписанные им, могут не совпадать. Рассмотрим задачу, в которой для имеющегося графа G требуется найти минимальные длины путей между каждой парой вершин графа. В качестве практического примера можно привести задачу составления маршрута движения транспорта между различными городами при заданном расстоянии между населенными пунктами и другие подобные задачи.
В качестве метода, решающего задачу поиска кратчайших путей между всеми парами пунктов назначения, далее используется алгоритм Флойда ( the Floyd algorithm ) (см, например, [ [ 26 ] ]).
10.1.1. Последовательный алгоритм Флойда
Для поиска минимальных расстояний между всеми парами пунктов назначения Флойд предложил алгоритм, сложность которого имеет порядок n3. В общем виде данный алгоритм может быть представлен следующим образом:
Алгоритм 10.1. Общая схема алгоритма Флойда
// Алгоритм 10.1
// Последовательный алгоритм Флойда
for (k = 0; k < n; k++)
for (i = 0; i < n; i++)
for (j = 0; j < n; j++)
A[i, j] = min(A[i, j], A[i, k] + A[k, j]);(реализация операции выбора минимального значения min должна учитывать способ указания в матрице смежности несуществующих дуг графа ). Как можно заметить, в ходе выполнения алгоритма матрица смежности A изменяется, после завершения вычислений в матрице A будет храниться требуемый результат – длины минимальных путей для каждой пары вершин исходного графа.
Дополнительная информация и доказательство правильности алгоритма Флойда могут быть получены, например, в работе [ [ 26 ] ].
10.1.2. Разделение вычислений на независимые части
Как следует из общей схемы алгоритма Флойда, основная вычислительная нагрузка при решении задачи поиска кратчайших путей состоит в выполнении операции выбора минимальных значений (см. Алгоритм 10.1). Данная операция является достаточно простой, и ее распараллеливание не приведет к заметному ускорению вычислений. Более эффективный способ организации параллельных вычислений может состоять в одновременном выполнении нескольких операций обновления значений матрицы A.
Покажем корректность такого способа организации параллелизма. Для этого нужно доказать, что операции обновления значений матрицы A на одной и той же итерации внешнего цикла k могут выполняться независимо. Иными словами, следует показать, что на итерации k не происходит изменения элементов Aik и Akj ни для одной пары индексов (i, j). Рассмотрим выражение, по которому происходит изменение элементов матрицы A:
Aij <- min (Aij, Aik + Akj).
Для i=k получим
Akj <- min (Akj, Akk + Akj),
но тогда значение Akj не изменится, т.к. Akk=0.
Для j=k выражение преобразуется к виду
Aik <- min (Aik, Aik + Akk),
что также показывает неизменность значений Aik. Как результат, необходимые условия для организации параллельных вычислений обеспечены, и, тем самым, в качестве базовой подзадачи может быть использована операция обновления элементов матрицы A (для указания подзадач будем применять индексы обновляемых в подзадачах элементов).
10.1.3. Выделение информационных зависимостей
Выполнение вычислений в подзадачах становится возможным только тогда, когда каждая подзадача (i, j) содержит необходимые для расчетов элементы Aij, Aik, Akj матрицы A. Для исключения дублирования данных разместим в подзадаче (i, j) единственный элемент Aij, тогда получение всех остальных необходимых значений может быть обеспечено только при помощи передачи данных. Таким образом, каждый элемент Akj строки k матрицы A должен быть передан всем подзадачам (k, j), 1<=j<=n, а каждый элемент Aik столбца k матрицы A должен быть передан всем подзадачам (i, k), 1<=i<=n,– см. рис. 10.3.
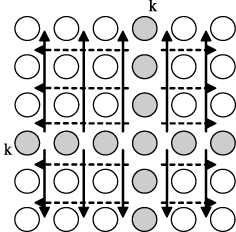
Рис. 10.3. Информационная зависимость базовых подзадач (стрелками показаны направления обмена значениями на итерации k)
10.1.4. Масштабирование и распределение подзадач по процессорам
Как правило, число доступных процессоров p существенно меньше, чем число базовых задач n2 (p<<n2). Возможный способ укрупнения вычислений состоит в использовании ленточной схемы разбиения матрицы A – такой подход соответствует объединению в рамках одной базовой подзадачи вычислений, связанных с обновлением элементов одной или нескольких строк ( горизонтальное разбиение) или столбцов ( вертикальное разбиение) матрицы A. Эти два типа разбиения практически равноправны – учитывая дополнительный момент, что для алгоритмического языка C массивы располагаются по строкам, будем рассматривать далее только разбиение матрицы A на горизонтальные полосы.
Следует отметить, что при таком способе разбиения данных на каждой итерации алгоритма Флойда потребуется передавать между подзадачами только элементы одной из строк матрицы A. Для оптимального выполнения подобной коммуникационной операции топология сети должна обеспечивать эффективное представление структуры сети передачи данных в виде гиперкуба или полного графа.
10.1.5. Анализ эффективности параллельных вычислений
Выполним анализ эффективности параллельного алгоритма Флойда, обеспечивающего поиск всех кратчайших путей. Как и ранее, проведем этот анализ в два этапа. На первом оценим порядок вычислительной сложности алгоритма, затем на втором этапе уточним полученные оценки и учтем трудоемкость выполнения коммуникационных операций.
Общая трудоемкость последовательного алгоритма, как уже отмечалось ранее, имеет порядок сложности n3. Для параллельного алгоритма на отдельной итерации каждый процессор выполняет обновление элементов матрицы А. Всего в подзадачах n2/p таких элементов, число итераций алгоритма равно n – таким образом, показатели ускорения и эффективности параллельного алгоритма Флойда имеют вид:
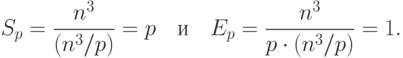 |
( 10.1) |
Следовательно, общий анализ сложности дает идеальные показатели эффективности параллельных вычислений. Для уточнения полученных соотношений введем в полученные выражения время выполнения базовой операции выбора минимального значения и учтем затраты на выполнение операций передачи данных между процессорами.
Коммуникационная операция, выполняемая на каждой итерации алгоритма Флойда, состоит в передаче одной из строк матрицы А
всем процессорам вычислительной системы. Как уже показывалось
ранее, такая операция может быть выполнена за 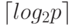 шагов. С
учетом количества итераций алгоритма Флойда при использовании
модели Хокни общая длительность выполнения коммуникационных
операций может быть определена при помощи следующего выражения
шагов. С
учетом количества итераций алгоритма Флойда при использовании
модели Хокни общая длительность выполнения коммуникационных
операций может быть определена при помощи следующего выражения
 |
( 10.2) |
 – латентность сети передачи данных,
– латентность сети передачи данных,  –
пропускная способность сети, а w есть размер элемента матрицы в
байтах.
–
пропускная способность сети, а w есть размер элемента матрицы в
байтах.С учетом полученных соотношений общее время выполнения параллельного алгоритма Флойда может быть определено следующим образом:
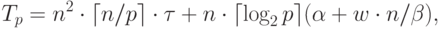 |
( 10.3) |
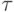 есть время выполнения операции выбора минимального
значения.
есть время выполнения операции выбора минимального
значения.