| Азербайджан |
Инспектор
Вы можете этот курс.
Опубликован: 30.04.2008 | Уровень: специалист | Доступ: платный | ВУЗ: Московский государственный университет имени М.В.Ломоносова
Лекция 2:
Классификация на основе байесовской теории решений
2.3. Минимизация среднего риска
Вероятность ошибки классификации – не всегда лучший критерий проверки классификатора. В том случае, когда цена ошибок различного типа существенно различается, лучше использовать другой критерий качества классификации – минимум среднего риска.
Рассмотрим задачу классификации по 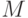 классам.
классам. 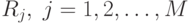 – области
предпочтения классов
– области
предпочтения классов 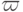 . Предположим, что вектор
. Предположим, что вектор  из класса
из класса 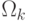 лежит в
лежит в 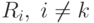 , т.е. классификация происходит с ошибкой. Свяжем с этой ошибкой
штраф
, т.е. классификация происходит с ошибкой. Свяжем с этой ошибкой
штраф 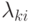 называемый потерями в результате того, что объект из класса
был принят за объект из класса
называемый потерями в результате того, что объект из класса
был принят за объект из класса 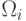 . Обозначим через
. Обозначим через 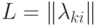 матрицу
потерь.
матрицу
потерь.
Определение. Выражение 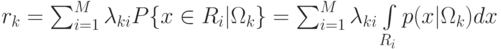 называется риском при классификации объекта класса .
называется риском при классификации объекта класса .
Определение. Выражение 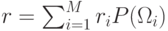 называется общим средним риском.
называется общим средним риском.
Теперь мы можем поставить задачу о выборе классификатора, минимизирующего этот риск. Преобразуем выражение общего среднего риска:
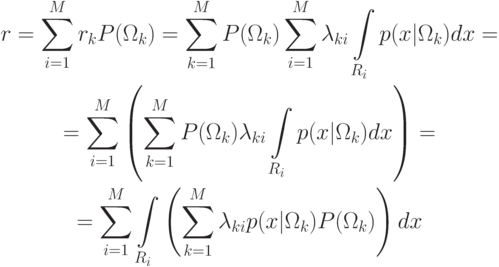
Из этого выражения видно, что риск минимален, когда каждый из
интегралов в данной сумме минимален, т.е. 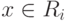 , если
, если 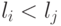 , при
, при 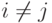 ,
где
,
где 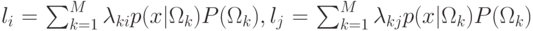 .
.
Пример. Рассмотрим ситуацию радиолокационной разведки. На экране радара отражаются не только цели, но и помехи. Такой помехой может служить стая птиц, которую можно принять за небольшой самолет. В данном случае это двухклассовая задача.
Рассмотрим матрицу штрафов: 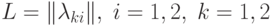 . – это штраф за принятие
объекта из класса
. – это штраф за принятие
объекта из класса 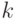 за объект класса
за объект класса  . Тогда
. Тогда
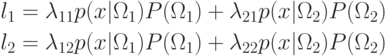 относится у классу
относится у классу 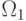 , если
, если 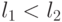 , т.е.
, т.е.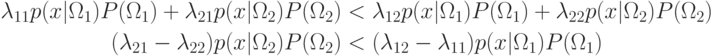
 и
и  , то
, то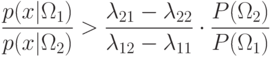
Стоящее в левой части неравенства отношение 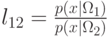 называется отношением
правдоподобия. Неравенство описывает условие предпочтения класса
классу
называется отношением
правдоподобия. Неравенство описывает условие предпочтения класса
классу  .
.
Пример. Рассмотрим двухклассовую задачу, в которой для
единственного признака известна плотность распределения:
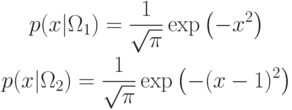
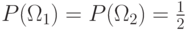 .
.Задача – вычислить пороги для
a) минимальной вероятности ошибки
b) минимального риска при матрице риска
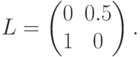
Решение задачи a):
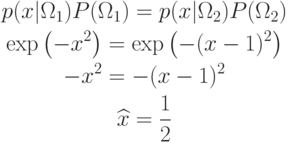
Решение задачи b):
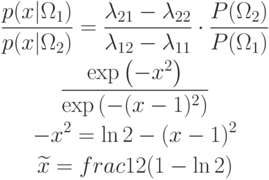
Пример. Рассмотрим двухклассовую задачу с Гауссовскими
плотностями распределения 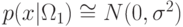 и
и 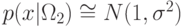 и матрицей потерь
и матрицей потерь 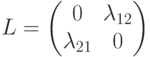 .
.
Задача – вычислить порог для проверки отношения правдоподобия.
Решение. С учетом матрицы потерь отношение правдоподобия
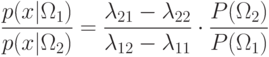
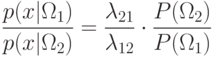
Запишем плотности распределения
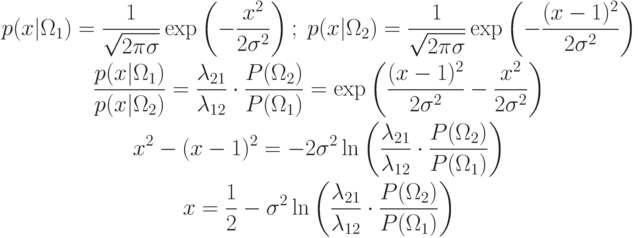
Пример. Рассмотрим двухклассовую задачу с матрицей потерь 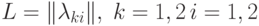 .
Пусть
.
Пусть 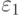 – вероятность ошибки, соответствующая вектору из класса
и
– вероятность ошибки, соответствующая вектору из класса
и 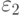 – вероятность ошибки, соответствующая вектору из класса .
Задача – найти средний риск.
– вероятность ошибки, соответствующая вектору из класса .
Задача – найти средний риск.
Решение.
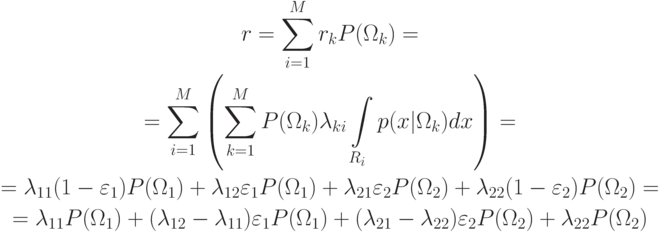
Пример. Доказать, что в задаче классификации по классам,
вероятность ошибки классификации ограничена: 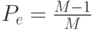 .
.
Указание: показать, что 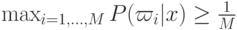 .
.