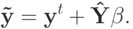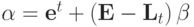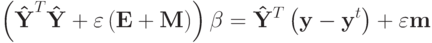Скрытые параметры и транспонированная регрессия
Если в качестве искомой формулы рассматривать линейную комбинацию векторов опорной группы, то требуемой инвариантности можно достичь, наложив некоторое условие на коэффициенты разложения. Таковым условием является равенство суммы коэффициентов единице:
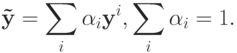
Для нелинейной регрессии естественно использовать однородные рациональные функции [7.2].
Рассматривались два вида решения. Первый:
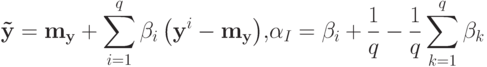 |
( 2) |
где  - восстановленный вектор свойств, yi - вектор свойств i -го объекта опорной группы, q - мощность опорной группы,
- восстановленный вектор свойств, yi - вектор свойств i -го объекта опорной группы, q - мощность опорной группы,
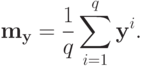
Во втором случае в качестве 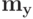 , выбирался один из векторов опорной группы.
, выбирался один из векторов опорной группы.
 |
( 3) |
Заметим, что легко построить нейронную сеть, вычисляющую такие формулы [7.5, 7.6].
Из-за предположения о малости опорной группы объектов в качестве одного из путей решения предлагается перебор всех наборов заданного размера. Было предложено искать минимум одного из двух критериев:
-
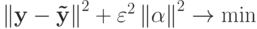 .
. -
 .
.
В случае а) точное решение находится из системы линейных уравнений. Введем обозначения:
- Y - матрица векторов опорной группы, n строк, q столбцов. n - число известных компонент восстанавливаемого вектора y.
-
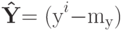 - матрица Y в которой из каждого столбца вычтен вектор my ( yt в случае 2).
- матрица Y в которой из каждого столбца вычтен вектор my ( yt в случае 2). - M - матрица, все элементы которой равны 1,
- m - вектор, все компоненты которого равны 1,
- E - единичная матрица,
-
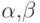 - вектора размерностью q.
- вектора размерностью q.
Для выражения (2)

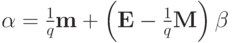 .
.Дифференцируя выражение а) и приравнивая нулю, получаем:

Для выражения (3),
et - вектор, t -ая компонента которого равна 1, остальные 0.
Lt = (et) - матрица, столбцы которой равны вектору et.
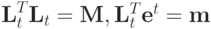
Имеем