Быстрое дифференцирование, двойственность и обратное распространение ошибки
Двойственность по Лежандру и смысл двойственных переменных
Просматривая текст предыдущих разделов, я убедился, что подробное изложение и элементы стиля математической логики могут даже очевидное сделать сложным. В данном разделе описывается связь двойственного функционирования сетей автоматов с преобразованием Лежандра и неопределенными множителями Лагранжа. Это изложение ориентировано на читателя, знакомившегося с лагранжевым и гамильтоновым формализмами и их связью (в классической механике или вариационном исчислении). Фактически на двух страницах будет заново изложен весь предыдущий материал лекции.
Переменные обратного функционирования  появляются как вспомогательные при вычислении производных сложной функции. Переменные такого типа появляются не случайно. Они постоянно возникают в задачах оптимизации и являются множителями Лагранжа.
появляются как вспомогательные при вычислении производных сложной функции. Переменные такого типа появляются не случайно. Они постоянно возникают в задачах оптимизации и являются множителями Лагранжа.
Мы вводим 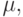 исходя из правил дифференцирования сложной функции. Возможен другой путь, связанный с переходом от функции Лагранжа к функции Гамильтона. Изложим его и параллельно получим ряд дальнейших обобщений. Для всех сетей автоматов, встречавшихся нам в предыдущих разделах и лекциях, можно выделить три группы переменных:
исходя из правил дифференцирования сложной функции. Возможен другой путь, связанный с переходом от функции Лагранжа к функции Гамильтона. Изложим его и параллельно получим ряд дальнейших обобщений. Для всех сетей автоматов, встречавшихся нам в предыдущих разделах и лекциях, можно выделить три группы переменных:
- внешние входные сигналы x...,
- переменные функционирования - значения на выходах всех элементов сети f...,
- переменные обучения a...
(многоточиями заменяются различные наборы индексов).
Объединим их в две группы - вычисляемые величины y... - значения f... и задаваемые - b... (включая a... и x...). Упростим индексацию, перенумеровав f и b натуральными числами: f1,...,fN; b1,...,bM.
Пусть функционирование системы задается набором из N уравнений
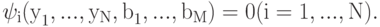 |
( 13) |
Для послойного вычисления сложных функций вычисляемые переменные - это значения вершин для всех слоев, кроме нулевого, задаваемые переменные - это значения вершин первого слоя (константы и значения переменных), а уравнения функционирования имеют простейший вид (4), для которого
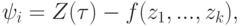
где 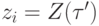 при
при 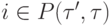 .
.
Предполагается, что система уравнений (13) задает способ вычисления yi.
Пусть имеется функция (лагранжиан) H(y1,...,yN,b1,...,bM). Эта функция зависит от b и явно, и неявно - через переменные функционирования y. Если представить, что уравнения (13) разрешены относительно всех y ( y=y(b) ), то H можно представить как функцию от b:
H=H1 (b)=H(y1 (b),...,yN (b),b). (14)
где b - вектор с компонентами bi.
Для задачи обучения требуется найти производные 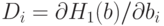 . Непосредственно и явно это сделать трудно.
. Непосредственно и явно это сделать трудно.
Поступим по-другому. Введем новые переменные 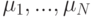 (множители Лагранжа) и производящую функцию W:
(множители Лагранжа) и производящую функцию W:

В функции W аргументы y, b и - независимые переменные.
Уравнения (13) можно записать как
 |
( 15) |
Заметим, что для тех y, b, которые удовлетворяют уравнениям (13), при любых
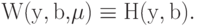 |
( 16) |
Это означает, что для истинных значений переменных функционирования y при данных b функция 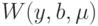 совпадает с исследуемой функцией H.
совпадает с исследуемой функцией H.
Попытаемся подобрать такую зависимость 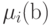 , чтобы, используя (16), получить для наиболее простые выражения. На многообразии решений (15)
, чтобы, используя (16), получить для наиболее простые выражения. На многообразии решений (15)
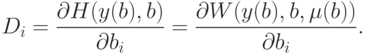
Поэтому
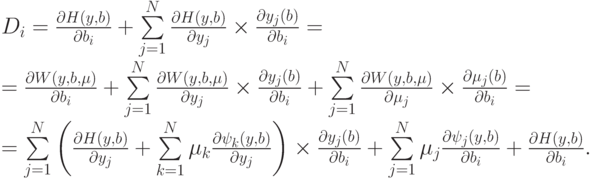 |
( 17) |
Мы всюду различаем функцию H(y,b), где y и b - независимые переменные, и функцию только от переменных b H(y(b),b), где y(b) определены из уравнений (13). Аналогичное различение принимается для функций  и
и 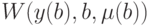 .
.
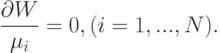
Произвол в определении 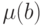 надо использовать наилучшим образом - все равно от него придется избавляться, доопределяя зависимости. Если выбрать такие что слагаемые в первой сумме последней строки выражения (17) обратятся в нуль, то формула для Di резко упростится. Положим поэтому
надо использовать наилучшим образом - все равно от него придется избавляться, доопределяя зависимости. Если выбрать такие что слагаемые в первой сумме последней строки выражения (17) обратятся в нуль, то формула для Di резко упростится. Положим поэтому
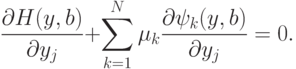 |
( 18) |
Это - система уравнений для определения 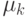 ( k=1,...,N ). Если определены согласно (18), то
( k=1,...,N ). Если определены согласно (18), то
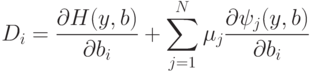
это - в точности те выражения, которые использовались при поиске производных сложных функций. В наших вычислениях мы пользовались явным описанием функционирования. Метод множителей Лагранжа допускает и менее явные описания сетей.
В математическом фольклоре бытует такой тезис: сложная задача оптимизации может быть решена только при эффективном использовании двойственности. Методы быстрого дифференцирования являются яркой иллюстрацией этого тезиса.