Параллельные генетические алгоритмы
4.2. Параллельный генетический алгоритм на основе модели "рабочий-хозяин"
В данном разделе для распараллеливания ГА используется модель "с" (иногда она называется "клиент-сервер"), поскольку она требует наименьших изменений в существующей версии программного обеспечения, реализующего последовательный ГА и дает неплохие результаты. Ниже представлен укрупненный алгоритм параллельного ГА на основе модели "рабочий - хозяин".
Параллельный ГА "Рабочий - хозяин"
{
Генерация популяции P хромосом случайным образом;
выполнение параллельно для всех особей
{
Оценка значения фитнесс-функции для каждой особи;
}
While(критерий останова не выполнен)
{
отбор лучших особей;
выполнение генетических операторов кроссиговера и мутации;
формирование промежуточной популяции;
выполнение параллельно для всех особей
{
Оценка значения фитнесс-функции для каждой особи;
}
внесение лучших новых особей;
удаление худших старых особей;
формирование новой популяции ;
}
}
При этом затраты по вычислению значений фитнесс-функций равномерно распределяются по всем процессорам, для которых используется одна и та же фитнесс-функция. Поэтому для  особей и
особей и 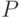 (одинаковых) процессоров мы каждому процессору относим
(одинаковых) процессоров мы каждому процессору относим 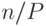 особей. Значения фитнесс-функции вычисляются соответствующими (рабочими) процессорами и посылаются в один процессор (хозяин), который собирает всю информацию, обрабатывает и передает ее снова рабочим процессорам. Процессор "хозяин" имеет информацию о значениях фитнесс-функции для всех особей и может генерировать следующее поколение на этой основе.
особей. Значения фитнесс-функции вычисляются соответствующими (рабочими) процессорами и посылаются в один процессор (хозяин), который собирает всю информацию, обрабатывает и передает ее снова рабочим процессорам. Процессор "хозяин" имеет информацию о значениях фитнесс-функции для всех особей и может генерировать следующее поколение на этой основе.
Итак, процессор–хозяин выполняет центральную часть (ядро) алгоритма, в то время как "черновая работа" - вычисление значений фитнесс-функции для всех особей реализуется на процессорах–рабочих. Для баланса множество обрабатываемых особей популяции разбивается на примерно одинаковые подмножества.
В конце каждого из этапов помещаются точки синхронизации. Когда процессор-хозяин достигает эти точки, он переходит в режим ожидания, пока все рабочие процессоры не закончат свои задания, что гарантирует глобальную корректность алгоритма. При этом работа между процессором-хозяином и рабочими распределяется следующим образом.
- выполняет все вход-выходные операции с пользователем и файловой системой, читает задание и записывает результаты;
- первоначально запускает "рабочие" процессы на доступных ресурсах;
- распределяет задания каждому рабочему процессору;
- организует управление процессом поиска решения и по мере необходимости посылает соответствующие сообщения активации рабочих процессоров; по окончании задания рабочим процессором процессор-хозяин принимает полученные результаты и соответственно изменяет глобальные структуры данных (общий список заданий, значения фитнесс-функции для особей и т.п.).
Каждый "рабочий" принимает задание от "хозяина" и определяет значение фитнесс-функции для особей, полученный результат посылает хозяину и ожидает следующего задания. Поскольку размер популяции много больше числа процессоров, достигается хороший баланс в загрузке процессоров. Диаграмма потоков данных в данном алгоритме приведена на рис.4.2 (на примере распределенного логического моделирования).
При использовании модели "рабочий - хозяин" окончательные результаты (поиска решения данной задачи) близки к тем, что получены на однопроцессорной компьютерной системе с использованием аналогичного алгоритма. Качество решения при этом не теряется и в большинстве случаев несколько улучшается, а время его поиска существенно сокращается. В целом данная модель позволяет быстро (с минимальными модификацями) выполнить параллелизацию ГА и дает, прежде всего, ускорение процесса поиска решения. Данную модель не сложно реализовать в локальной сети с использованием технологии сокетов.
Типичный график увеличения быстродействия (для задачи построения проверяющих тестов) представлен на рис.4.3. [5]. Здесь вверху для сравнения представлен "идеальный" линейный график роста ускорения в зависимости от увеличения числа процессоров. Реальное ускорение (особенно для большого числа процессоров) естественно несколько меньше.

Следует отметить, что для задач большей размерности выигрыш в увеличении быстродействия обычно больше, так как "накладные расходы" на пересылки по сравнению с основными затратами на поиск решения составляют меньшую долю. На рис.4.4 для примера представлен график увеличения быстродействия с ростом размерности задачи (сложности обрабатываемой схемы) [5].
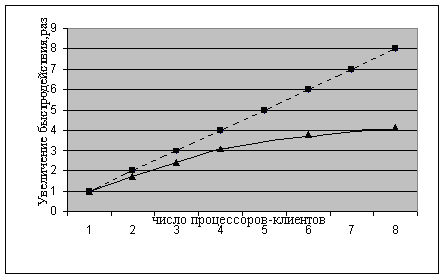
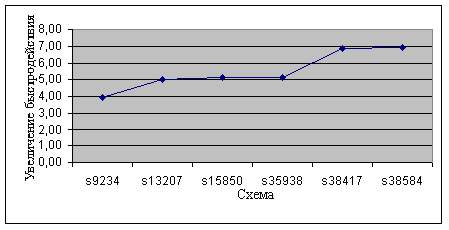
Эксперименты показывают, что при грамотной реализации этой модели даже в локальной сети можно выиграть порядок в увеличении быстродействия (при относительно небольших модификациях исходного программного обеспечения).