Опубликован: 28.07.2007 | Доступ: свободный | Студентов: 2051 / 518 | Оценка: 4.53 / 4.26 | Длительность: 25:10:00
ISBN: 978-5-9556-0096-3
Специальности: Программист
Лекция 4:
Принципы разработки параллельных методов
4.2. Этапы разработки параллельных алгоритмов
Рассмотрим более подробно изложенную выше методику разработки параллельных алгоритмов. В значительной степени данная методика опирается на подход, впервые разработанный в [ [ 32 ] ], и, как отмечалось ранее, включает этапы выделения подзадач, определения информационных зависимостей, масштабирования и распределения подзадач по процессорам вычислительной системы (см. рис. 4.1). Для демонстрации приводимых рекомендаций далее будет использоваться учебная задача поиска максимального значения среди элементов матрицы A (такая задача возникает, например, при численном решении систем линейных уравнений для определения ведущего элемента метода Гаусса):
 |
( 4.1) |
Данная задача носит полностью иллюстративный характер, и после рассмотрения этапов разработки в оставшейся части лекции будет приведен более полный пример использования данной методики для разработки параллельных алгоритмов. Кроме того, данная схема разработки будет применена и при изложении всех рассматриваемых далее методов параллельных вычислений.
4.2.1. Разделение вычислений на независимые части
Выбор способа разделения вычислений на независимые части основывается на анализе вычислительной схемы решения исходной задачи. Требования, которым должен удовлетворять выбираемый подход, обычно состоят в обеспечении равного объема вычислений в выделяемых подзадачах и минимума информационных зависимостей между этими подзадачами (при прочих равных условиях нужно отдавать предпочтение редким операциям передачи сообщений большего размера по сравнению с частыми пересылками данных небольшого объема). В общем случае, проведение анализа и выделение задач представляет собой достаточно сложную проблему – ситуацию помогает разрешить существование двух часто встречающихся типов вычислительных схем (см. рис. 4.3).
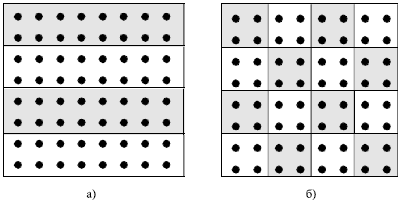
Для большого класса задач вычисления сводятся к выполнению однотипной обработки большого набора данных – к такому классу задач относятся, например, матричные вычисления, численные методы решения уравнений в частных производных и др. В этом случае говорят, что существует параллелизм по данным, и выделение подзадач сводится к разделению имеющихся данных. Так, например, для рассматриваемой учебной задачи поиска максимального значения при формировании подзадач исходная матрица может быть разделена на отдельные строки (или последовательные группы строк) – так называемая ленточная схема разделения данных (см. рис. 4.3) – либо на прямоугольные наборы элементов – блочная схема разделения данных. Для большого количества решаемых задач разделение вычислений по данным приводит к порождению одно-, дву- и трехмерных наборов подзадач, в которых информационные связи существуют только между ближайшими соседями (такие схемы обычно именуются сетками или решетками).
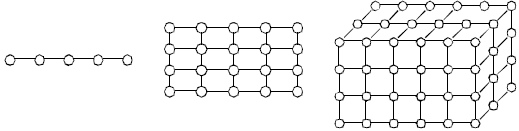
Для другой части задач вычисления могут состоять в выполнении разных операций над одним и тем же набором данных – в этом случае говорят о существовании функционального параллелизма (в качестве примеров можно привести задачи обработки последовательности запросов к информационным базам данных, вычисления с одновременным применением разных алгоритмов расчета и т.п.). Очень часто функциональная декомпозиция может быть использована для организации конвейерной обработки данных (так, например, при выполнении каких-либо преобразований данных вычисления могут быть сведены к функциональной последовательности ввода, обработки и сохранения данных).
Важный вопрос при выделении подзадач состоит в выборе нужного уровня декомпозиции вычислений. Формирование максимально возможного количества подзадач обеспечивает использование предельно достижимого уровня параллелизма решаемой задачи, однако затрудняет анализ параллельных вычислений. Применение при декомпозиции вычислений только достаточно "крупных" подзадач приводит к ясной схеме параллельных вычислений, однако может затруднить эффективное использование достаточно большого количества процессоров. Возможное разумное сочетание этих двух подходов может состоять в применении в качестве конструктивных элементов декомпозиции только тех подзадач, для которых методы параллельных вычислений являются известными. Так, например, при анализе задачи матричного умножения в качестве подзадач можно использовать методы скалярного произведения векторов или алгоритмы матрично-векторного произведения. Подобный промежуточный способ декомпозиции вычислений позволит обеспечить и простоту представления вычислительных схем, и эффективность параллельных расчетов. Выбираемые подзадачи при таком подходе будем именовать далее базовыми, которые могут быть элементарными (неделимыми), если не допускают дальнейшего разделения, или составными - в противном случае.
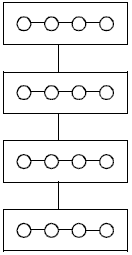
Для рассматриваемой учебной задачи достаточный уровень декомпозиции может состоять, например, в разделении матрицы на множество отдельных строк и получении на этой основе набора подзадач поиска максимальных значений в отдельных строках; порождаемая при этом структура информационных связей соответствует линейному графу (см. рис. 4.5).
Для оценки корректности этапа разделения вычислений на независимые части можно воспользоваться контрольным списком вопросов, предложенных в [ [ 32 ] ]:
- выполненная декомпозиция не увеличивает объем вычислений и необходимый объем памяти?
- возможна ли при выбранном способе декомпозиции равномерная загрузка всех имеющихся процессоров?
- достаточно ли выделенных частей процесса вычислений для эффективной загрузки имеющихся процессоров (с учетом возможности увеличения их количества)?
4.2.2. Выделение информационных зависимостей
При наличии вычислительной схемы решения задачи после выделения базовых подзадач определение информационных зависимостей между ними обычно не вызывает больших затруднений. При этом, однако, следует отметить, что на самом деле этапы выделения подзадач и информационных зависимостей достаточно сложно поддаются разделению. Выделение подзадач должно происходить с учетом возникающих информационных связей, после анализа объема и частоты необходимых информационных обменов между подзадачами может потребоваться повторение этапа разделения вычислений.
При проведении анализа информационных зависимостей между подзадачами следует различать (предпочтительные формы информационного взаимодействия выделены подчеркиванием):
- локальные и глобальные схемы передачи данных – для локальных схем передачи данных в каждый момент времени выполняются только между небольшим числом подзадач (располагаемых, как правило, на соседних процессорах), для глобальных операций передачи данных в процессе коммуникации принимают участие все подзадачи;
- структурные и произвольные способы взаимодействия – для структурных способов организация взаимодействий приводит к формированию некоторых стандартных схем коммуникации (например, в виде кольца, прямоугольной решетки и т. д.), для произвольных структур взаимодействия схема выполняемых операций передач данных не носит характера однородности;
- статические или динамические схемы передачи данных – для статических схем моменты и участники информационного взаимодействия фиксируются на этапах проектирования и разработки параллельных программ, для динамического варианта взаимодействия структура операции передачи данных определяется в ходе выполняемых вычислений;
- синхронные и асинхронные способы взаимодействия – для синхронных способов операции передачи данных выполняются только при готовности всех участников взаимодействия и завершаются только после полного окончания всех коммуникационных действий, при асинхронном выполнении операций участники взаимодействия могут не дожидаться полного завершения действий по передаче данных. Для представленных способов взаимодействия достаточно сложно выделить предпочтительные формы организации передачи данных: синхронный вариант, как правило, более прост для применения, в то время как асинхронный способ часто позволяет существенно снизить временные задержки, вызванные операциями информационного взаимодействия.
Как уже отмечалось в предыдущем пункте, для учебной задачи поиска максимального значения при использовании в качестве базовых элементов подзадач поиска максимальных значений в отдельных строках исходной матрицы структура информационных связей имеет вид, представленный на рис. 4.5.
Для оценки правильности этапа выделения информационных зависимостей можно воспользоваться контрольным списком вопросов, предложенным в [ [ 32 ] ]:
- соответствует ли вычислительная сложность подзадач интенсивности их информационных взаимодействий?
- является ли одинаковой интенсивность информационных взаимодействий для разных подзадач?
- является ли схема информационного взаимодействия локальной?
- не препятствует ли выявленная информационная зависимость параллельному решению подзадач?
4.2.3. Масштабирование набора подзадач
Масштабирование разработанной вычислительной схемы параллельных вычислений проводится в случае, если количество имеющихся подзадач отличается от числа планируемых к использованию процессоров. Для сокращения количества подзадач необходимо выполнить укрупнение ( агрегацию ) вычислений. Применяемые здесь правила совпадают с рекомендациями начального этапа выделения подзадач: определяемые подзадачи, как и ранее, должны иметь одинаковую вычислительную сложность, а объем и интенсивность информационных взаимодействий между подзадачами должны оставаться на минимально возможном уровне. Как результат, первыми претендентами на объединение являются подзадачи с высокой степенью информационной взаимозависимости.
При недостаточном количестве имеющихся подзадач для загрузки всех доступных к использованию процессоров необходимо выполнить детализацию ( декомпозицию ) вычислений. Как правило, проведение подобной декомпозиции не вызывает каких-либо затруднений, если для базовых задач методы параллельных вычислений являются известными.
Выполнение этапа масштабирования вычислений должно свестись, в конечном итоге, к разработке правил агрегации и декомпозиции подзадач, которые должны параметрически зависеть от числа процессоров, применяемых для вычислений.
Для рассматриваемой учебной задачи поиска максимального значения агрегация вычислений может состоять в объединении отдельных строк в группы (ленточная схема разделения матрицы – см. рис. 4.3а), при декомпозиции подзадач строки исходной матрицы могут разбиваться на несколько частей (блоков).
Список контрольных вопросов, предложенный в [ [ 32 ] ] для оценки правильности этапа масштабирования, выглядит следующим образом:
- не ухудшится ли локальность вычислений после масштабирования имеющегося набора подзадач?
- имеют ли подзадачи после масштабирования одинаковую вычислительную и коммуникационную сложность?
- соответствует ли количество задач числу имеющихся процессоров?
- зависят ли параметрически правила масштабирования от количества процессоров?
4.2.4. Распределение подзадач между процессорами
Распределение подзадач между процессорами является завершающим этапом разработки параллельного метода. Надо отметить, что управление распределением нагрузки для процессоров возможно только для вычислительных систем с распределенной памятью, для мультипроцессоров (систем с общей памятью) распределение нагрузки обычно выполняется операционной системой автоматически. Кроме того, данный этап распределения подзадач между процессорами является избыточным, если количество подзадач совпадает с числом имеющихся процессоров, а топология сети передачи данных вычислительной системы представляет собой полный граф (т. е. все процессоры связаны между собой прямыми линиями связи).
Основной показатель успешности выполнения данного этапа – эффективность использования процессоров, определяемая как относительная доля времени, в течение которого процессоры использовались для вычислений, связанных с решением исходной задачи. Пути достижения хороших результатов в этом направлении остаются прежними: как и ранее, необходимо обеспечить равномерное распределение вычислительной нагрузки между процессорами и минимизировать количество сообщений, передаваемых между ними. Точно так же как и на предшествующих этапах проектирования, оптимальное решение проблемы распределения подзадач между процессорами основывается на анализе информационной связности графа "подзадачи – сообщения". Так, в частности, подзадачи, имеющие информационные взаимодействия, целесообразно размещать на процессорах, между которыми существуют прямые линии передачи данных.
Следует отметить, что требование минимизации информационных обменов между процессорами может противоречить условию равномерной загрузки. Мы можем разместить все подзадачи на одном процессоре и полностью устранить межпроцессорную передачу сообщений, однако понятно, что загрузка большинства процессоров в этом случае будет минимальной.
Для учебной задачи поиска максимального значения распределение подзадач между процессорами не вызывает каких-либо затруднений – достаточно лишь обеспечить размещение подзадач, между которыми имеются информационные связи, на процессорах, для которых существуют прямые каналы передачи данных. Поскольку структура информационной связей учебной задачи имеет вид линейного графа, выполнение данного требования может быть обеспечено практически при любой топологии сети вычислительной системы.
Решение вопросов балансировки вычислительной нагрузки значительно усложняется, если схема вычислений может изменяться в ходе решения задачи. Причиной этого могут быть, например, неоднородные сетки при решении уравнений в частных производных, разреженность матриц и т.п. 3Можно отметить, что даже для нашей простой учебной задачи может наблюдаться различная вычислительная сложность сформированных базовых задач. Так, например, количество операций при поиске максимального значания для строки, в которой максимальное значение имеет первый элемент, и строки, в которой значения являются упорядоченными по возрастанию, будет различаться в два раза.. Кроме того, используемые на этапах проектирования оценки вычислительной сложности решения подзадач могут иметь приближенный характер, и, наконец, количество подзадач может изменяться в ходе вычислений. В таких ситуациях может потребоваться перераспределение базовых подзадач между процессорами уже непосредственно в ходе выполнения параллельной программы (или, как обычно говорят, придется выполнить динамическую балансировку вычислительной нагрузки). Данные вопросы являются одними из наиболее сложных (и наиболее интересных) в области параллельных вычислений – к сожалению, их рассмотрение выходит за рамки нашего учебного материала (дополнительная информация может быть получена, например, в [ [ 24 ] , [ 75 ] ]).
В качестве примера дадим краткую характеристику широко используемого способа динамического управления распределением вычислительной нагрузки, обычно именуемого схемой "менеджер – исполнитель" ( the manager-worker scheme ). При использовании данного подхода предполагается, что подзадачи могут возникать и завершаться в ходе вычислений, при этом информационные взаимодействия между подзадачами либо полностью отсутствуют, либо минимальны. В соответствии с рассматриваемой схемой для управления распределением нагрузки в системе выделяется отдельный процессор-менеджер, которому доступна информация обо всех имеющихся подзадачах. Остальные процессоры системы являются исполнителями, которые для получения вычислительной нагрузки обращаются к процессору-менеджеру. Порождаемые в ходе вычислений новые подзадачи передаются обратно процессору-менеджеру и могут быть получены для решения при последующих обращениях процессоров- исполнителей. Завершение вычислений происходит в момент, когда процессоры-исполнители завершили решение всех переданных им подзадач, а процессор-менеджер не имеет каких-либо вычислительных работ для выполнения.
Предложенный в [ [ 32 ] ] перечень контрольных вопросов для проверки этапа распределения подзадач состоит в следующем:
- не приводит ли распределение нескольких задач на один процессор к росту дополнительных вычислительных затрат?
- существует ли необходимость динамической балансировки вычислений?
- не является ли процессор-менеджер "узким" местом при использовании схемы "менеджер – исполнитель"?