Опубликован: 28.07.2007 | Доступ: свободный | Студентов: 2051 / 518 | Оценка: 4.53 / 4.26 | Длительность: 25:10:00
ISBN: 978-5-9556-0096-3
Специальности: Программист
Лекция 4:
Принципы разработки параллельных методов
4.3. Параллельное решение гравитационной задачи N тел
Многие задачи в области физики сводятся к операциям обработки данных для каждой пары объектов имеющейся физической системы. Такой задачей является, в частности, проблема, широко известная в литературе как гравитационная задача N тел (или просто задача N тел ) – см., например, [ [ 5 ] ]. В самом общем виде задача может быть описана следующим образом.
Пусть дано большое количество тел (планет, звезд и т. д.), для каждого из которых известна масса, начальное положение и скорость. Под действием гравитации положение тел меняется, и требуемое решение задачи состоит в моделировании динамики изменения системы N тел на протяжении некоторого задаваемого интервала времени. Для проведения такого моделирования заданный интервал времени обычно разбивается на временные отрезки небольшой длительности и далее на каждом шаге моделирования вычисляются силы, действующие на каждое тело, а затем обновляются скорости и положения тел.
Очевидный алгоритм решения задачи N тел состоит в рассмотрении на каждом шаге моделирования всех пар объектов физической системы и выполнении для каждой получаемой пары всех необходимых расчетов. Как результат, при таком подходе время выполнения одной итерации моделирования будет составлять4Следует отметить, что для решения задачи N тел существуют и более эффективные последовательные алгоритмы, однако их изучение может потребовать достаточно больших усилий. С учетом данного обстоятельства для дальнейшего рассмотрения выбирается именно данный "очевидный" (но не самый быстрый) метод.
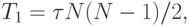 |
( 4.2) |
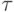 есть время перевычисления параметров одной пары тел.
есть время перевычисления параметров одной пары тел.Как следует из приведенного описания, вычислительная схема рассмотренного алгоритма является сравнительно простой, что позволяет использовать задачу N тел в качестве еще одной наглядной демонстрации применения методики разработки параллельных алгоритмов.
4.3.1. Разделение вычислений на независимые части
Выбор способа разделения вычислений не вызывает каких-либо затруднений – очевидный подход состоит в выборе в качестве базовой подзадачи всего набора вычислений, связанных с обработкой данных какого-либо одного тела физической системы.
4.3.2. Выделение информационных зависимостей
Выполнение вычислений, связанных с каждой подзадачей, становится возможным только в случае, когда в подзадачах имеются данные (положение и скорости передвижения) обо всех телах физической системы. Как результат, перед началом каждой итерации моделирования каждая подзадача должна получить все необходимые сведения от всех других подзадач системы. Такая процедура передачи данных, как отмечалось в "Оценка коммуникационной трудоемкости параллельных алгоритмов" , именуется операцией сбора данных ( single-node gather ). В рассматриваемом алгоритме данная операция должна быть выполнена для каждой подзадачи – такой вариант передачи данных обычно именуется операцией обобщенного сбора данных ( multi-node gather или all gather ).
Определение требований к необходимым результатам информационного обмена не приводит к однозначному установлению нужного информационного обмена между подзадачами – достижение требуемых результатов может быть обеспечено при помощи разных алгоритмов выполнения операции обобщенного сбора данных.
Наиболее простой способ выполнения необходимого информационного обмена состоит в реализации последовательности шагов, на каждом из которых все имеющиеся подзадачи разбиваются попарно и обмен данными осуществляется между подзадачами образовавшихся пар. При надлежащей организации попарного разделения подзадач ( N-1 )-кратное повторение описанных действий приведет к полной реализации требуемой операции сбора данных.
Рассмотренный выше метод организации информационного обмена является достаточно трудоемким – для сбора всех необходимых данных требуется провести N-1 итерацию, на каждой из которых выполняется одновременно N/2 операций передачи данных. Для сокращения требуемого количества итераций можно обратить внимание на факт, что после выполнения первого шага операции сбора данных подзадачи будут уже содержать не только свои данные, но и данные подзадач, с которыми они образовывали пары. Как результат, на второй итерации сбора данных можно будет образовывать пары подзадач для обмена данными сразу о двух телах физической системы – тем самым, после завершения второй итерации каждая подзадача будет содержать сведения о четырех телах системы и т. д. Как можно заметить, данный способ реализации обменов позволяет завершить необходимую процедуру за log2N итераций. Следует отметить, что при этом объем пересылаемых данных в каждой операции обмена удваивается от итерации к итерации: на первой итерации между подзадачами пересылаются данные об одном теле системы, на второй – о двух телах и т. д.
4.3.3. Масштабирование и распределение подзадач по процессорам
Как правило, число тел физической системы N значительно превышает количество процессоров p. Поэтому рассмотренные ранее подзадачи следует укрупнить, объединив в рамках одной подзадачи вычисления для группы из N/p тел. После проведения подобной агрегации число подзадач и количество процессоров будет совпадать и при распределении подзадач между процессорами останется лишь обеспечить наличие прямых коммуникационных линий между процессорами с подзадачами, у которых имеются информационные обмены при выполнении операции сбора данных.
4.3.4. Анализ эффективности параллельных вычислений
Оценим эффективность разработанных способов параллельных вычислений для решения задачи N тел. Поскольку предложенные варианты отличаются только методами выполнения информационных обменов, для сравнения подходов достаточно определить длительность операции обобщенного сбора данных. Используем для оценки времени передачи сообщений модель, предложенную Хокни (см. "Оценка коммуникационной трудоемкости параллельных алгоритмов" ), - тогда длительность выполнения операции сбора данных для первого варианта параллельных вычислений может быть выражена как
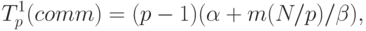 |
( 4.3) |
 и
и  есть параметры модели Хокни (латентность и пропускная
способность сети передачи данных), а m задает объем пересылаемых
данных для одного тела физической системы.
есть параметры модели Хокни (латентность и пропускная
способность сети передачи данных), а m задает объем пересылаемых
данных для одного тела физической системы.Для второго способа информационного обмена, как уже отмечалось ранее, объем пересылаемых данных на разных итерациях операции сбора данных различается. На первой итерации объем пересылаемых сообщений составляет Nm/p, на второй этот объем увеличивается вдвое и оказывается равным 2Nm/p и т.д. В общем случае, для итерации с номером i объем сообщений оценивается как 2i-1Nm/p. Как результат, длительность выполнения операции сбора данных в этом случае может быть определена при помощи следующего выражения:
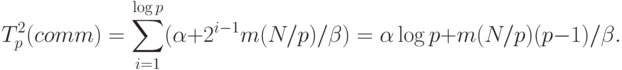 |
( 4.4) |
Сравнение полученных выражений показывает, что второй разработанный способ параллельных вычислений имеет существенно более высокую эффективность, требует меньших коммуникационных затрат и допускает лучшую масштабируемость при увеличении количества используемых процессоров.