![Условная схема автоматизированной системы вопросов и ответов. Источник: IBM [77]](/EDI/18_12_24_2/1734474022-28631/tutorial/963/objects/2/files/02-17.jpg)
|
Не удается заказать доставку сертификата ни в pdf - ни в бумажном виде, сайт выдает окно с сообщением "Ошибка" и сразу его закрывает. |
Опубликован: 30.05.2023 | Доступ: свободный | Студентов: 1820 / 933 | Длительность: 16:08:00
Лекция 3:
Эволюция ИИ в процессе решения практических задач
Для наглядного и упрощенного объяснения процесса (рис. 2.15) часто прибегают к аналогии, представляя один процесс в виде художника, пытающегося подделать картину, а другой в виде искусствоведа, который пытается отличить реальное изображение от сгенерированной фальшивки.
Представим, что в данной ситуации художник имеет возможность получать информацию о том, на каком основании искусствовед отличил картину-подделку от подлинника (не тот цвет, характер мазка и т. п.), и создавать улучшенную фальшивку. При многократном повторении данного цикла должен наступить момент, когда искусствовед не найдет отличий, - это и считается моментом появления изображения, неотличимого от оригинала.
Возвращаясь к состязательным сетям, можно сказать, что цель обучения модели G заключается в максимальном увеличении вероятности ошибки дискрминатора D. Использование этой техники и позволяет генерировать упомянутые нами ранее "фотографии несуществующих объектов", которые человеческим глазом воспринимаются как натуральные фото реальных объектов. Например, известна попытка синтезировать фотографии кошек, которые вводят в заблуждение эксперта, считающего их естественными фото [73].
Можно сказать, что мы не можем отличить сгенерированные моделью объекты от реально существующих, поскольку модель смогла "понять" характер внешности того или иного объекта именно так, как его понимают люди.
GAN-ы - это еще один этап в эволюции возможностей техники в проявлении художественных способностей, переход от умения создать точные копии объекта до возможности передачи некоторой совокупности усредненных качеств объекта, позволяющих воссоздать новый уникальный объект, неотличимый от его реальных прототипов.
GAN-ы оказались очень эффективны в решении задачи генерации изображений. И, надо отметить, возможности моделей постоянно совершенствуются. Первоначально основным способом оценки качества подобных моделей являлась экспертная оценка сгенерированных объектов, проводимая специалистом, человеком в виде ответа на вопрос "Насколько синтетический объект соответствует реальному?". Данный подход является субъективным, дорогим и малопригодным для обработки больших объемов данных. Со временем появились более объективные автоматические методы анализа характеристик генеративных моделей, которые позволяют количественно описать уровень качества создаваемых синтетических моделей и дают возможность аналитикам отслеживать процесс совершенствования моделей. Для оценки качества GAN используется ряд метрик, включая Fr?chet Inception Distance FID (начальное расстояние Фреше). Последняя метрика применима исключительно для оценки GAN, генерирующих изображения определенного формата. Метрика FID была введена в 2017 году для сравнения признаков сгенерированных и реальных изображений. Низкое значение FID соответствует изображениям высокого качества и наоборот. Добавление шума и искажений (снижение качества изображений) повышает FID.
На рис. 2.16 показан прогресс генеративных моделей за последние два года в создании синтетических изображений, проведенный по метрике FID на базе набора данных STL-10, который используется для проверки того, насколько эффективно системы генерируют изображения. STL-10 - это датасет для распознавания изображений, который состоит из 100 000 неразмеченных и 500 обучающих изображений и используется для разработки алгоритмов глубокого обучения и самообучения.
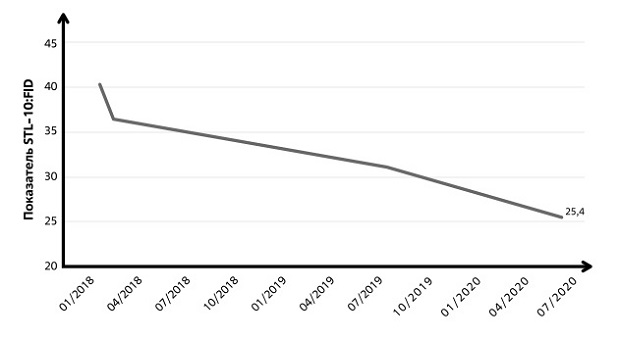
Рис. 2.16. Динамика показателя FID в соревновании STL-10 за период 2018-2020 г. Источник: AI Index Report 2021
Интересно отметить, что направления ИИ, связанные с обработкой изображений и естественного языка, в какой-то момент нашли пересечение.
В 2014 году одним из главных достижений в области ИИ стало появление технологии автоматического создания подписей к изображениям. К тому времени алгоритмы машинного обучения уже умели маркировать объекты на изображениях, и в дополнение к этому они научились создавать по изображению описания на естественном языке типа "На изображении девочка играет в мяч".
Со временем появилась идея - нельзя ли выполнить обратную задачу и сгенерировать изображение по текстовому описанию. Для того чтобы продолжить разговор о взаимодействии языковых моделей ИИ и технологий генерации изображений, следует более подробно остановиться на эволюции технологий обработки естественного языка.
Обработка естественного языка и нейронные сети
До сих пор, говоря об эволюции ИИ и нейронных сетей, в частности, мы преимущественно рассматривали примеры из области компьютерного зрения. Классификация изображений действительно была первым барьером, который удалось преодолеть с помощью глубокого обучения, но вскоре модели, основанные на данной технологии, также победили в задачах NLP- в машинном переводе [74, 75] и распознавании речи [76].
При этом надо сказать, что эволюция систем обработки естественного языка не менее важный аспект развития ИИ. Более того, в области обработки языка нейросетевая революция явила не менее впечатляющие результаты: машинный перевод на наших глазах стал почти неотличим от перевода людей-переводчиков, а голосовые интеллектуальные помощники стали привычным сервисом. Возможности аннотирования документов, голосовое управление, генерация текстов и даже стихов - все эти чудеса нам стали доступны с помощью нейросетевых NLP-технологий. Так что без экскурса в эволюцию систем NLP и анализа влияния глубокого обучения на NLP рассмотрение темы будет явно неполным.
NLP - это одно из важнейших направлений искусственного интеллекта, которое позволяет обеспечить взаимодействие между компьютером и человеком на базе естественного языка, то есть помогает компьютерам понимать человеческий язык, интерпретировать его и манипулировать им. NLP - это зонтичный термин, объединяющий ряд областей, связанных с обработкой естественного языка.
Основные элементы NLP можно представить на упрощенной замкнутой схеме системы "вопрос - ответ" (рис. 2.17), которая включает: перевод речи в текст; обработку текста (представление текста в интерпретируемые машиной данные); механизм контроля диалога, имеющий интерфейс к некоторому источнику знаний о предметной области; систему генерации ответа (текста на естественном языке); и, наконец, синтез этого текста обратно в речь.
Помимо сокращения NLP часто используются аббревиатуры NLU и NLG.
NLU (Natural-language understanding, понимание естественного языка) - это часть NLP - система, отвечающая за разбор высказываний пользователей и понимание их смысла, она включает такие этапы как предварительная обработка текста, классификация запроса, соотнесение с одним из классов, известных системе, и извлечение параметров запроса (сущностей).
NLG (Natural-language generation) - генерация естественного языка - процесс преобразования структурированных данных в естественный язык.
На базе технологий NLP созданы десятки различных приложений, некоторые из которых перечислены на рис. 2.18.