|
Не удается заказать доставку сертификата ни в pdf - ни в бумажном виде, сайт выдает окно с сообщением "Ошибка" и сразу его закрывает. |
Опубликован: 30.05.2023 | Доступ: свободный | Студентов: 1772 / 901 | Длительность: 16:08:00
Лекция 3:
Эволюция ИИ в процессе решения практических задач
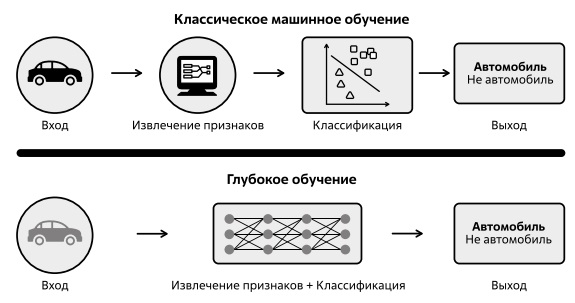
В верхней части рис. 2.2 показан процесс распознавания, при использовании классических ML-алгоритмов человек должен был вычленить уникальные особенности или признаки (опорные точки, наличие и координаты больших фрагментов изображения прямоугольной и круглой формы и т. д.), извлечь эти признаки и передать их алгоритму в качестве входных данных.
На основе выделенных признаков (если они правильно выбраны) алгоритм проведет классификацию изображений.
В случае с моделью глубокого обучения шаг извлечения признаков не нужен. Сеть извлекает эти признаки самостоятельно. Причем извлечение признаков возможно там, где человек выполнить подобную процедуру не может в принципе.
Действительно, даже если человек способен распознать тот или иной объект, он далеко не всегда может определить совокупность признаков, по которым он принял решение. Увидев ночью кошку или собаку, перебегающую дорогу даже при слабом освещении, мы, как правило, можем сказать, кто это был на самом деле, а вот сформулировать набор признаков, по которым мы смогли дать классификацию, крайне сложно.
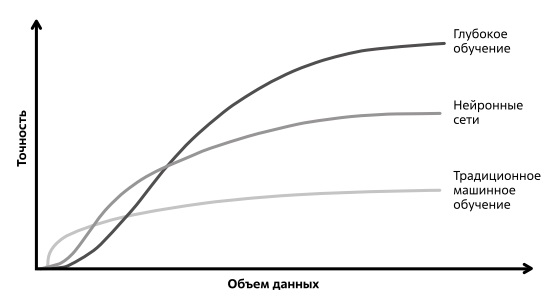
Способность глубокого обучения в извлечении уникального набора признаков и демонстрация высочайшей производительности (более высокой, чем у человека) состоит в том, что глубокая нейронная сеть опирается при обучении на огромные объемы данных. Глубокие нейронные сети позволяют получить производительность, недостижимую для алгоритмов классического машинного обучения, но, как правило, требуют для этого наборы данных очень большого объема (рис. 2.3).
Многие достижения в области искусственного интеллекта за последние годы связаны именно с глубоким обучением. Наиболее точные модели на его основе требуют тысяч и даже миллионов элементов обучающих данных.
Для решения задач, возникающих в небольших компаниях с ограниченными финансами, такие большие наборы данных и такие вычислительные ресурсы для обучения сети недоступны. При этом следует отметить, что классические алгоритмы машинного обучения (которые мы упоминали выше) в ряде случаев не потеряли своей актуальности, и часто их применение бывает даже более эффективным (см. рис. 2.3).
Например, для того чтобы классифицировать на конвейере продукты разного цвета, не обязательно использовать глубокую нейросеть, решения можно добиться, используя простое пороговое цветовое выделение. Например, можно посчитать среднее значение цвета по всем пикселям изображения и различать по этому числу разные продукты.
Существует множество задач в области компьютерного зрения, таких как потоковая обработка видео, автоматическая сшивка панорам, оценка движения и идентификация движущихся объектов, которые иногда проще реализовать классическими методами [62].
Говоря об эволюции моделей на базе глубокого обучения, необходимо отметить, что здесь прорыв возможностей нейросетей по распознаванию изображений стал прямым результатом роста вычислительной мощности. Этот факт наглядно демонстрирует рис. 2.4, рассматривая эволюцию производительности аппаратного обеспечения и рост потребностей в вычислительных мощностях со стороны крупнейших нейросетевых проектов.
![Темпы роста вычислительной мощности для задач глубокого обучения и производительности оборудования. Источник: Документ "Вычислительные пределы глубокого обучения". Источник: [63]](/EDI/18_12_24_2/1734474022-28631/tutorial/963/objects/2/files/02-04.jpg)
Рис. 2.4. Темпы роста вычислительной мощности для задач глубокого обучения и производительности оборудования. Источник: Документ "Вычислительные пределы глубокого обучения". Источник: [63]
На рисунке отмечено три периода - эра масштабирования Деннарда 8Ученый обнаружил, что чем меньше размеры транзистора, тем быстрее он может переключаться, и чем быстрее транзистор может переключаться, тем быстрее работает процессор. Из этого следовал вывод о том, что уменьшение размеров транзистора и повышение его тактовой частоты позволят повышать его производительность, эра многоядерных вычислений и эра глубокого обучения.
Как известно, рост производительности аппаратного обеспечения связывают с законом Мура 9Эмпирическое наблюдение, изначально сделанное Гордоном Муром, согласно которому количество транзисторов, размещаемых на кристалле интегральной схемы, будет удваиваться каждые два года . Удвоение производительности на ватт потребляемой мощности лежало в основе возможности периодичного обновления серверного оборудования примерно через каждые три-четыре года. Со временем стало наблюдаться так называемое замедление действия этого закона, показанное на схеме отставанием реальной кривой от прогнозируемой.
В районе 2004-2005 гг. закон масштабирования Деннарда перестал работать, поскольку при уменьшении размеров транзисторов токи утечки приводят к перегреву процессора и выходу его из строя. Невозможность наращивания тактовой частоты стимулировала альтернативный подход - разработку многоядерных процессоров. В соответствии, с чем следующий период назван "мультиядерная эра".
В период с 1985 по 2009 год рост вычислительных требований наиболее крупных из используемых нейронных сетей увеличивался примерно пропорционально росту вычислительной мощности оборудования.
Поскольку рост вычислительной мощности в расчете на один доллар примерно повторяет рост вычислительной мощности в расчете на один чип, стоимость работы таких моделей была в значительной степени стабильной с течением времени примерно до 2009 года.
Переломным моментом стал перенос глубокого обучения на GPU 10Графический процессор (GPU) - специализированная электронная схема, эффективная при работе с обработкой изображений. Параллельная структура GPU делает их более эффективными (чем центральные процессоры общего назначения CPU) для алгоритмов, которые параллельно обрабатывают большие блоки данных, что дало ускорение в потреблении вычислительной мощности новыми моделями глубокого обучения в районе 2012 года, именно это, в частности, позволило осуществить важную победу Alexnet (о которой речь пойдет ниже) на конкурсе Imagenet в упомянутом году 11Заметим, что резкий рост доли исследований, посвященных компьютерному зрению после 2012 г., хорошо виден на самом первом рисунке данного курса .
Таким образом, кривая роста потребностей в вычислительной мощности для крупнейших проектов глубокого обучения после примерно 2005 года изменялась с ускорением, а кривая роста производительности оборудования с замедлением.
Одно из направлений преодоления "замедления закона Мура" стимулировало подходы, основанные на увеличении количества серверов путем объединения их в кластеры. Другое исходило из того, что, если темпы увеличения производительности центрального процессора сервера замедляются, необходимо ускорить работу серверного оборудования путем создания специализированных процессоров. То есть вместо использования универсальных процессоров для обработки множества различных задач внедрить различные типы процессоров, адаптированных к потребностям конкретных задач. Так, одним из важнейших факторов для практического применения глубоких нейронных сетей стала доступность параллельных вычислений на графических ускорителях, о чем более подробно пойдет речь ниже.
Помимо проблем доступной вычислительной мощности следует отметить, что до 2005 года у специалистов не было достаточного количества данных, на основе которых можно было бы создать высокопроизводительные модели распознавания изображений. В 2009 году произошло объединение ряда американских институтов для создания массивного набора данных под названием ImageNet.
ImageNet - это проект по созданию и сопровождению массивной базы данных размеченных изображений из более чем 14 миллионов изображений 1000 классов 12По состоянию на 2021 г., который предоставляет данные исследователям для обучения алгоритмов искусственного интеллекта.
С 2010 года в рамках ILSVRC 13ImageNet Large Scale Visual Recognition Challenge - широкомасштабное соревнование по распознаванию образов на базе ImageNet проводятся соревнования, где конкурируют различные исследовательские группы по распознаванию объектов. На рис. 2.5 показаны данные результатов соревнований разработчиков ИИ в рамках данного проекта в период с 2010 по 2017 г.