|
Не удается заказать доставку сертификата ни в pdf - ни в бумажном виде, сайт выдает окно с сообщением "Ошибка" и сразу его закрывает. |
Опубликован: 30.05.2023 | Доступ: свободный | Студентов: 1772 / 902 | Длительность: 16:08:00
Лекция 3:
Эволюция ИИ в процессе решения практических задач
Обратим внимание на модель Vision Transformer, показанную на рис.2.30 на границе 2020 года. В то время как архитектура Transformer стала стандартом дефакто для задач обработки естественного языка после 2017 года, ее применение в компьютерном зрении оставалось ограниченным. В задачах компьютерного зрения механизм внимания либо применялся совместно со сверточными сетями, либо использовался для замены определенных компонентов сверточных сетей при сохранении их общей структуры.
В 2020 году Досовицкий и др. (2020) [95] предложили модель Vision Transformer (ViT) и в данной публикации показали, что выше-упомянутая зависимость от CNN не является необходимой и чистый трансформер может хорошо справляться с задачами классификации изображений.
Как ранее было отмечено, трансформеры используют механизм внимания, суть которого в самом общем плане в NLP-задачах состоит в измерении связей между парами входных слов. Стоимость этой операции (с точки зрения вычислительных ресурсов) квадратично зависит от количества слов. Для изображений основной единицей анализа является пиксель. Однако вычисление взаимосвязей для каждой пары пикселей в типичном изображении является непомерно затратным с точки зрения вычислительных ресурсов. Вместо этого ViT вычисляет отношения между пикселями в различных небольших участках изображения (например, 16x16 пикселей), что позволило значительно снизить вычислительные затраты и показать хорошие результаты [96]. В нижней части рис. 2.30 представлена эволюция архитектур нейросетевых моделей, используемых в задачах NLP. Здесь выделено два больших блока - это RNN, которая господствовала до 2017 года, и сменившая ее архитектура Transformer, о которой мы написали выше. Боксами меньшего размера представлены конкретные модели, начиная от LSTM и заканчивая GPT-3, которые также ранее были рассмотрены.
В средней части приведены модели, которые были предложены для решения мультимодальных задач (компьютерное зрение - обработка языка). Для решения указанных задач необходима совместная обработка изображения и текста, связанного с ним. Подобные модели позволяют решать такие задачи, как генерация описания по изображению, изображения по текстовому описанию, визуальные ответы на вопросы 32Визуальные ответы на вопросы - это задача, в которой системе задается текстовый вопрос об изображении, на который она должна дать ответ. Это могут быть вопросы, касающиеся распознавания объектов, и в данном случае вопрос может быть сформулирован в форме "Что находится на изображении?" или поиск изображения по подписи.
Первая из упомянутых на рисунке моделей данного типа - это модель Google Show and Tell ("Покажи и расскажи"), которая позволяла определить, что изображено на фотографии. Модель была создана в 2014 году и в течение нескольких лет дорабатывалась. В публикации за 2016 год [97] было отмечено, что в ходе тренировки модели на подписях, созданных людьми, система научилась генерировать подписи с точностью около 94%.
Впоследствии, до появления архитектуры трансформеров (до 2017 г.) был предложен еще ряд мультимодальных моделей - это такие модели как Spatial Attention, DenseCAP, Semantic Attention.
После успеха предварительно обученных трансформаторов для языкового моделирования, таких как BERT, профессиональное сообщество предложило различные модели на основе трансформеров, такие как Vil-BERT 33ViLBERT - сокращение от Vision-and-Language BERT - модель для обучения совместных представлений изображений и естественного языка на базе архитектуры BERT (Lu и др. 2019), UNITER34UNITER - сокращение от UNiversal Image-Text Representation Learning - универсальное обучение представлению изображения и текста (Chen и др. 2020), ViLT35ViLT- сокращение от Vision-and-Language Transformer - модель для обучения совместных представлений изображений и естественного языка на базе архитектуры трансформер (Kim, Son и др. 2021), которые объединяют представления из текста и изображений и достигают высоких результатов в нескольких мультимодальных задачах [98].
В 2019 году была начата разработка нейронной сети DALL-E, когда OpenAI получила грант суммой в 1 миллиард долларов от компании Microsoft на разработку инновационных технологий в сфере искусственного интеллекта. Первая версия нейросети была представлена мировому сообществу в январе 2021 года, а в апреле 2022 года была анонсирована новая версия - DALL-E 2, созданная для генерации изображений на основе пользовательского описания.
В интернете доступна версия DALL-E Mini (Craiyon Image Generator From Text), где каждый может поэкспериментировать и посмотреть, как нейросеть строит изображения по текстовым описаниям пользователей (рис. 2.31).

Рис. 2.31. Онлайновый сервис построения изображений по тексту Craiyon Image Generator From Text. Изображения по тексту "Тарелка с яблоком и грушей". Источник: (DALL-E Mini)
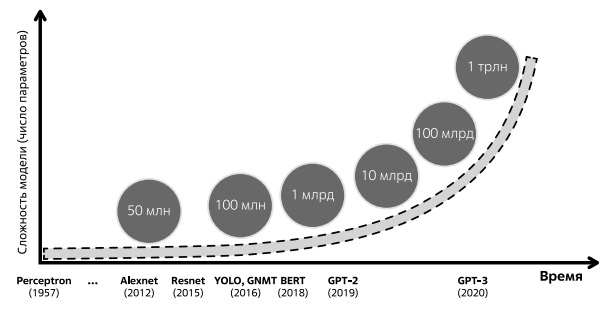
Мы рассмотрели последний период развития нейросетевых моделей применительно к решению задач компьютерного зрения и задач естественного языка. И далее хотели бы продемонстрировать общую картину развития нейросетевых моделей, начиная с их зарождения и заканчивая последними моделями победителей разного рода соревнований. Общая тенденция для обсуждаемых моделей - это экспоненциальный рост числа параметров (рис. 2.32).
Отсчет на рис. 2.32 ведется начиная с упомянутых в начале курса моделей - Персептрон, Alexnet, Resnet. Следом на рисунке идет представленная впервые в 2016 году нейронная сеть Yolo (You Only Look Once), используемая для обнаружения объектов в реальном времени с высокой точностью, которая имела более 65 млн обучаемых параметров. Следующей в ряду указана Google Neural MachineTranslation (GNMT) - система нейронного машинного перевода, разработанная компанией Google и представленная в ноябре 2016 года. Решение было использовано для повышения скорости и точности перевода в Google Translate. Двумя годами позже появилась также упомянутая нами нейросетевая модель-трансформер по имени BERT от компании Google, которая появилась в начале 2018 года. BERT имела 110 миллионов параметров, а ее версия Bert Large - 340 миллионов [99]. В 2019 году вышла модель GPT-2 от компании OpenAI с рекордным на момент появления числом параметров в полтора млрд [100]. GPT-3 была представлена в мае 2020 года и имела около 175 миллиардов обучаемых параметров, полная версия OpenAI GPT-3 стала самой большой моделью, обученной на момент представления.
На создание GPT-3 ушли десятки миллионов долларов. Известно, что только вычислительные затраты на одну итерацию обучения составили около 4,6 миллиона долларов, что представляет лишь небольшую долю общих затрат. Кривая рис. 2.32 показывает резкий рост стоимости обучения модели с увеличением ее размера.