Опубликован: 30.05.2023 | Доступ: свободный | Студентов: 1678 / 817 | Длительность: 16:08:00
Лекция 2:
Определения, структура и развитие систем ИИ
![Упрощенная схема робота на гусеничном ходу, следующего за источником света. Источник: по материалам [40]](/EDI/18_12_24_2/1734474022-28631/tutorial/963/objects/1/files/01-27.jpg)
Рис. 1.27. Упрощенная схема робота на гусеничном ходу, следующего за источником света. Источник: по материалам [40]
Входные ячейки (фотоэлектрические датчики) реагируют на свет, посылают сигналы на выходные ячейки (нейроны), которые подают сигнал на управление гусеницами робота. Обучить такой автомат разным вариантам движения в зависимости от положения света можно задав весовые коэффициенты, определяющие силу связи между ячейками. В рассмотренном примере задача по обучению робота состояла в необходимости обеспечения движения такой машины за источником света. Для этого были подобраны веса, определяющие силу связи (от 0,45 до 0,99), как показано на рисунке. Еслиположение источника света находится спереди слева от автомата, то активируется вращение правой гусеницы, и наоборот. Несложно представить, что подобная машина будет двигаться за источником света.
Мы рассмотрели простейшую однослойную сеть. Больший интерес представляют многослойные сети. На рис. 1.28 показана многослойная сеть, где каждый нейрон одного слоя посылает сигнал каждому нейрону другого слоя. Данная сеть - это сеть прямого распространения, то есть сеть, в которой сигнал распространяется от входного слоя к выходному в одном направлении33Сети, в которых выход нейрона может вновь подаваться на его вход, называются сетями с обратными связями или рекуррентными сетями, о таких сетях речь пойдет далее в этой лекции .
В показанной на рис. 1.28 сети пять слоев - один входной, три скрытых (промежуточных) и один выходной. Чем больше количество слоев, тем глубже сеть, поэтому и появился термин "глубокое обучение". Формально при наличии больше одного скрытого слоя уже принято говорить о глубоких нейронных сетях [41], сети с одним скрытым слоем называют неглубокими (shallow).
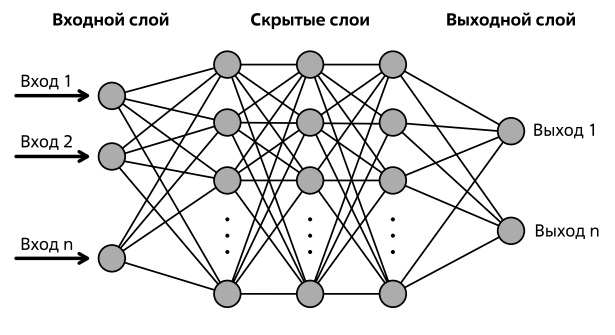
Далее поговорим об обучении нейронных сетей. В процессе обучения на вход подается вектор признаков ( рис.1.28), описывающий объект (массив значений), число элементов которого равно числу входных нейронов, на внутренних слоях происходит обработка сигналов, сеть преобразовывает сигнал в выходной слой.
Для того чтобы более наглядно объяснить, как происходит процесс обучения, рассмотрим конкретную задачу распознавания рукописных символов (рис. 1.29).
![Упрощенная схема распознавания рукописных цифр. Источник: [42]](/EDI/18_12_24_2/1734474022-28631/tutorial/963/objects/1/files/01-29.jpg)
Как показано на рисунке, изображение рукописного символа (в данном случае цифры 4) разбивается на пикселы, представляется в виде вектора чисел и подается на вход сети.
Если бы все символы были одного размера и начертания, то задача распознавания была бы предельно простой - в том смысле, что сети потребовался бы всего лишь один входной вектор, чтобы запомнить один правильный ответ. Но цифры могут быть напечатаны разными шрифтами, а если мы говорим про рукописные символы, то тут разнообразие еще больше. Все люди пишут числа по-разному - наклон, начертание (все то, что мы называем почерком). И если мы подадим сети, обученной на одном примере, немного измененный входной вектор, соответствующий несколько иному начертанию той же цифры, то правильного ответа уже не получим.
Если необходимо, чтобы сеть классифицировала все многочисленные варианты рукописного написания цифр (например, четверки, показанной на рисунке как числа "4"), то задача состоит в том, чтобы научить сеть способности обобщать признаки на различных входных данных.
Для этого сети нужно продемонстрировать максимально полный набор вариантов написания цифры разными способами, чтобы она "поняла", какая совокупность признаков позволяет людям относить все разные начертания к одному классу изображений (цифре четыре). Для решения подобной задачи создаются обучающие выборки - данные, по которым обучается сеть. Обучение производится на многочисленных примерах размеченных данных, то есть на базе изображений, в каждом из которых отмечен правильный результат. Подобное обучение называют обучением с учителем или контролируемым обучением. Этот процесс похож на обучение ребенка. Ученику показывают изображение цифры в курсе или написав ее на доске, сообщая при этом правильный ответ. А потом тестируют ученика на знание предмета. Похожая процедура проводится с сетью. Сеть обучают на большом числе примеров по многочисленным вариантам написания каждой цифры, в результате чего подбираются весовые коэффициенты всех связей нейронов, и сеть в результате этой операции приобретает способность распознавать те изображения рукописных цифр, которые ей ранее не были продемонстрированы. После того, как сеть обучена, качество полученной модели проверяют на тестовой выборке. Если тест пройден - модель готова.
На рис. 1.29 условно мы показали процесс распознавания рукописной цифры 4. Затемненные кружки на рисунке отражают процесс возбуждения (активаций) нейронов, приводящих к получению ответа на выходном слое. Темным цветом показана искомая цифра, а светло-серым в выходном слое обозначены нейроны, соответствующие цифрам 1 и 7, что отражает тот факт, что написание этих цифр имеет некоторые схожие признаки с цифрой "4".
Жизненный цикл нейронной сети, как и любой модели машинного обучения, состоит из двух этапов: обучение (training) и применение (inference). На рис. 1.30 показаны периоды обучения сети: 1 иллюстрирует сеть определенной топологии до начала обучения, 2 показывает процесс обучения. Речь идет о задаче, в которой сеть должна обучиться относить изображения к одному из двух классов - "кошка" и "собака". По аналогии с предыдущим примером, где речь шла о необходимости продемонстрировать сети все варианты написания цифр, в данном случае сети необходимо продемонстрировать все варианты расположения, все ракурсы, все варианты освещения изображений обоих животных, чтобы сеть могла вычленить общие признаки для распознавания каждого из двух классов на фото. По мере того, как в сеть подаются размеченные изображения (про каждое известно, что там показано - кошка или собака), идет процесс обучения, который состоит в том, чтобы так подобрать весовые коэффициенты, чтобы сеть правильно относила каждое изображение к одному из двух классов. На рисунке на стадии обучения нейроны показаны разных размеров, что условно означает процесс нахождения весовых коэффициентов, которые определяют разную силу связи между соседними нейронами (то есть вес отдельных нейронов). На рис. 1.30 (3-4) условно показан процесс оптимизации сети по производительности: производится удаление избыточных связей в сети - связей, которые определяются малыми весами.
![Стадии обучения искусственной нейронной сети. Источник: адаптировано по материалам [43]](/EDI/18_12_24_2/1734474022-28631/tutorial/963/objects/1/files/01-30.jpg)
На рис. 1.31 представлена более подробная схема, иллюстрирующая стадии обучения и применения нейронной сети с привязкой к ИТ-инфраструктуре. В верхней части диаграммы показана система приема и обработки данных. Левая ветвь показывает процесс обучеия модели.
В случае глубокой нейросети на вход подаются тысячи и более размеченных данных, на которых сеть должна обучиться, чтобы идентифицировать закономерности в данных. Обучение обычно требует больших затрат вычислительных ресурсов, процесс обучения может быть реализован на локальном оборудовании или в облаке.
Обученная и оптимизированная модель передается в систему, где происходит ее применение - сеть распознает новые изображения. Заметим, что обучение сети может являться довольно длительным процессом, а вычисление результатов обученной сетью модели происходит достаточно быстро. Готовая для использования модель может быть размещена в облаке в некотором ЦОДе, локально у заказчика или на периферийном устройстве. В случае периферийного устройства небольшой мощности может быть особенно актуальна стадия оптимизации модели по производительности, о которой мы упомянули ранее.