DMX. Параметры алгоритмов интеллектуального анализа данных. Временные ряды, кластеризация
MicrosoftTimeSeries
Начнем с рассмотрения процесса создания структуры и модели. Пусть мы работаем с чередующимся временным рядом, описывающим продажи в штуках велосипедов разных марок по месяцам в разных регионах. Подобный формат представлен в таблице 14.1.
| DateSeries | ModelRegion | Quantity |
|---|---|---|
| 200904 | M200 Europe | 30 |
| 200905 | M200 Europe | 40 |
| … | … | … |
| 200904 | M200 Pacific | 20 |
| … | … | … |
| 200904 | R250 Europe | 20 |
| … | … | … |
Пример кода, создающего структуру интеллектуального анализа, приведен ниже.
CREATE MINING STRUCTURE TimeSeries1_structure
([DateSeries] DATE KEY TIME,
[Model Region] TEXT KEY,
[Quantity] LONG CONTINUOUS)
При создании структуры надо обратить внимание на то, чтобы в ключ входил атрибут, содержащий отметку времени (в примере это [DateSeries]). Кроме того, для нормальной работы алгоритма необходимо, чтобы ряд был без пропусков. Поэтому в структуре резервирование данных для тестового набора (выполняемое с помощью инструкции WITH HOLDOUT) делать не надо. Теперь рассмотрим пример кода, создающего модель:
ALTER MINING STRUCTURE TimeSeries1_structure
ADD MINING MODEL TimeSeries1_TS
([DateSeries],
[Model Region],
[Quantity] PREDICT )
USING Microsoft_Time_Series (PERIODICITY_HINT = '{12}', MISSING_VALUE_SUBSTITUTION = 0)
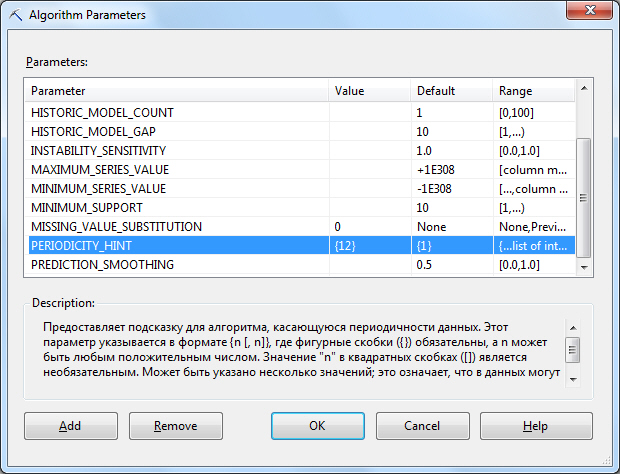
Надо обратить внимание на два использованных параметра. Первый из них - PERIODICITY_HINT - указывает на наличие периодичности 12 (по числу месяцев в году). Второй параметр (MISSING_VALUE_SUBSTITUTION) указывает, что пропущенные значения элементов ряда надо заменять на 0. В нашем случае, это означает, что если информации о продаже в данном месяце данной модели велосипедов нет, то считаем, что продаж не было. После создания модели параметры алгоритма можно просматривать и изменять, например, через графический интерфейс BIDevStudio.
Как мы уже разбирали в "Использование инструментов "AnalyzeKeyInfluencers" и "DetectCategories"" , алгоритм временных рядов Майкрософт (MicrosoftTimeSeries) предоставляет собой совокупность двух алгоритмов:
- "дерево авторегрессии с перекрестным прогнозированием" (ARTXP), который оптимизирован для прогнозирования следующего значения в ряду;появился в SQL Server 2005;
- "интегрированные скользящие средние авторегрессии" (ARIMA), являющийся отраслевым стандартом в данной области; добавлен в SQL Server 2008, чтобы повысить точность долгосрочного прогнозирования.
Считается, что алгоритм ARTXP, давая более точный прогноз для ближайших значений ряда, существенно менее точен в долгосрочных прогнозах по сравнению с ARIMA. При настройках по умолчанию будут использоваться результаты работы обоих алгоритмов. При этом, с помощью параметров модели можно указать, в какой степени каждый из алгоритмов оказывает влияние на итоговый результат, или вообще включить использование только одного алгоритма.
На рис. 14.2a показано, как модель объединяет результаты алгоритмов, если параметр PREDICTION_SMOOTHING имеет значение по умолчанию - 0,5. Вначале алгоритмы ARIMA и ARTXP получают равные весовые коэффициенты, но по мере увеличения числа шагов прогнозирования вес алгоритма ARIMA растет. На рис. 14.2b показано, как результаты будут объединяться при значении PREDICTION_SMOOTHING равном 0,2.

увеличить изображение
Рис. 14.2. Коэффициенты, с которыми учитываются результаты прогнозирования алгоритмов ARIMA и ARTXP. a)PREDICTION_SMOOTHING=0,5; b) PREDICTION_SMOOTHING=0,2
Общее число параметров алгоритма достаточно велико, поэтому ниже перечислены только наиболее значимые из них. Более полную информацию можно получить из литературы [1] и справочной системы SQLServer.
| MISSING_VALUE_SUBSTITUTION | указывает порядок заполнения пропусков в данных. По умолчанию пропуски в данных не допускаются. Ниже перечислены возможные значения для этого параметра: | |
| Previous | повторяет значение из предыдущего временного среза; | |
| Mean | использует значение скользящего среднего среди временных рядов, использованных в обучении; | |
| числовая константа | использует конкретное число для замены всех отсутствующих значений; | |
| None | замещает отсутствующие значения значениями, расположенными на кривой обученной модели.Это значение по умолчанию. | |
| AUTO_DETECT_PERIODICITY | числовое значение от 0 до 1, используемое для автоматического обнаружения периодичности. Значение по умолчанию - 0,6.Если значение ближе к 0, то периодичность учитывается только для строго периодических данных. Использование значения близкого к 1, повышает вероятность обнаружения многих закономерностей, близких к периодическим, и автоматического создания подсказок периодичности. | |
| PERIODICITY_HINT | предоставляет подсказку для алгоритма, касающуюся периодичности данных. Например, если продажи варьируются в зависимости от года, а в ряду в качестве единицы измерения используются месяцы, то периодичность равна 12. Этот параметр имеет формат {n [, n]}, где n - любое положительное число.
Число n внутри квадратных скобок [] является необязательным и может повторяться сколь угодно часто. Например, чтобы задать несколько подсказок периодичности для данных, пополняемых ежемесячно, можно ввести {12, 3, 1}, чтобы обнаруживать закономерности, проявляющиеся ежегодно, ежемесячно и ежеквартально. Однако подсказки периодичности сильно влияют на качество работы модели. Если заданная подсказка отличается от реальной периодичности, это может отрицательно сказаться на результатах.Значение по умолчанию равно {1}. Фигурные скобки указывать обязательно. Кроме того, этот параметр имеет строковый тип данных. Поэтому, если нужно ввести этот параметр в составе инструкции расширений интеллектуального анализа данных, необходимо поместить в кавычки числовое значение в фигурных скобках. |
|
| FORECAST_METHOD | указывает, какой алгоритм используется для анализа и прогнозирования. Возможные значения -ARTXP, ARIMA и MIXED. Значение по умолчанию - MIXED. | |
| PREDICTION_SMOOTHING | указывает, как модель должна использовать сочетание двух алгоритмов для оптимизации прогнозов (имеет смысл, если FORECAST_METHOD установлен в MIXED). Может принимать значения от 0 до 1. | |
| 0 | при прогнозировании используется только алгоритм ARTXP. Процесс прогнозирования оптимизируется для небольшого числа прогнозов. | |
| 1 | при прогнозировании используется только алгоритм ARIMA. Процесс прогнозирования оптимизируется для большого числа прогнозов. | |
| 0.5(по умолчанию) | указывает, что при прогнозировании используются оба алгоритма, а их результаты объединяются. | |
| Этот параметр доступен только в выпуске SQL ServerEnterprise. | ||
| HISTORIC_MODEL_COUNT | указывает количество моделей с предысторией, которые будут построены. Эти дополнительные модели обучаются по "обрезанному" временному ряду и могут использоваться для анализа точности прогнозирования (более подробно об этом см.[1] и справочную систему SQLServer) Значение по умолчанию - 1. Этот параметр доступен только в выпуске SQL Server Enterprise. | |
| HISTORICAL_MODEL_GAP | указывает интервал времени между двумя последовательными моделями с предысторией. Значение по умолчанию - 10. Это значение выражено в единицах времени, которые определяются моделью.Этот параметр доступен только в выпуске SQL Server Enterprise. | |
| MAXIMUM_SERIES_VALUEиMINIMUM_SERIES_VALUE | максимальное и минимальное значения, используемые для прогнозов. Например, можно указать, что прогнозируемый объем продаж никогда не должен быть отрицательным числом.Эти параметры доступны только в выпуске SQL ServerEnterprise. | |
MicrosoftClustering
Рассмотрим пример кода, создающего модель интеллектуального анализа данных. Пусть надо выполнить кластеризацию клиентов, про которых мы знаем возраст, число детей, семейное положение. Сначала создадим структуру:
CREATE MINING STRUCTURE Customer_structure
([CustomerKey] LONGKEY,
[MaritalStatus] TEXTDISCRETE,
[TotalChildren] LONGDISCRETE,
[Age] LONG CONTINUOUS)
К созданной структуре добавим модель, основанную на алгоритме кластеризации. Атрибуты [MaritalStatus], [TotalChildren], [Age] будут рассматриваться как выходные. И явно укажем число кластеров, которое хотим получить:
ALTER MINING STRUCTURE Customer_structure
ADD MINING MODEL Customer_CL
([CustomerKey],
[MaritalStatus],
[TotalChildren],
[Age])
USING Microsoft_Clustering (CLUSTER_COUNT=6)
WITHDRILLTHROUGH
Требования к данным для модели кластеризации будут следующими [15]:
- каждая модель должна содержать один ключевой числовой или текстовый столбец, применение составных ключей не допускается;
- каждая модель должна содержать, по меньшей мере, один входной столбец, включающий значения, которые используются для формирования кластеров;
- необязательный прогнозируемый столбец: этому алгоритму не требуется прогнозируемый столбец для формирования модели, но предусмотрена возможность добавления прогнозируемого столбца с данными почти любого типа. Например, если требуется предсказать доход заказчика путем кластеризации по таким демографическим показателям, как регион или возраст, то можно задать доход как PredictOnly и ввести все остальные столбцы, например с данными о регионе или возрасте, в качестве входных данных.
Ниже приведен код, позволяющий обработать модель и выполнить прогнозирующий запрос, в котором номер кластера выводится с помощью функции Cluster(), оценка вероятности того, что данный вариант принадлежит данному кластеру, выводится функцией ClusterProbability().
//заполнение структуры с обработкой структур и модели
INSERTINTOMININGSTRUCTURE [Customer_structure]
([CustomerKey], [Age], [MaritalStatus], [TotalChildren])
OPENQUERY ([Adventure Works DW],
'SELECT [CustomerKey], [Age], [MaritalStatus], [TotalChildren]
FROMdbo.vTargetMail')
GO
// запрос, возвращающий для клиента номер кластера и оценку вероятности
SELECT t.*, Cluster(), ClusterProbability()
FROM Customer_CL
NATURALPREDICTIONJOIN
OPENQUERY ([Adventure Works DW],
'SELECT [CustomerKey], [Age], [MaritalStatus], [TotalChildren]
FROM dbo.vTargetMail') as t
Теперь перечислим основные параметры алгоритма, которые можно указать для модели.