Создание структуры и модели интеллектуального анализа. Задача кластеризации
Итак, в представлении vTargetMailу нас есть информация о клиентах (имя, дата рождения, семейное положение, число машин и т.д.) и о том, приобрел конкретный клиент велосипед или нет (столбец BikeBuyer=1, если велосипед покупался, иначе =0). Путь необходимо разделить всех клиентов на несколько групп, сходных по значениям параметров. Подобная задача называется задачей кластеризации. Средствами надстроек интеллектуального анализа для MS Office 2007 мы решали подобную задачу в ходе выполнения в ходе "Использование инструментов "AnalyzeKeyInfluencers" и "DetectCategories"" . Теперь разберем, как ее решить в среде BIDevStudio.
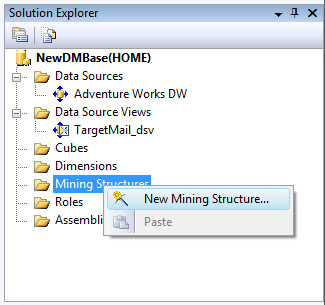
Сначала понадобится создать структуру и модель интеллектуального анализа. Откроем созданную ранее базу аналитических служб в среде BIDevStudio, в окне SolutionExplorer щелкнем правой клавишей мыши на узле узел MiningStructures и в контекстном меню выберем NewMiningStructure( рис. 28.1).
После вывода окна приветствия мастер DataMiningWizardзапросит, будет ли создаваемая структура основана на реляционном источнике данных или на кубе OLAP ( рис. 28.2). Нам нужен первый вариант, использующий реляционную БД.
увеличить изображение
Рис. 28.2. Создание новой структуры интеллектуального анализа данных (продолжение)
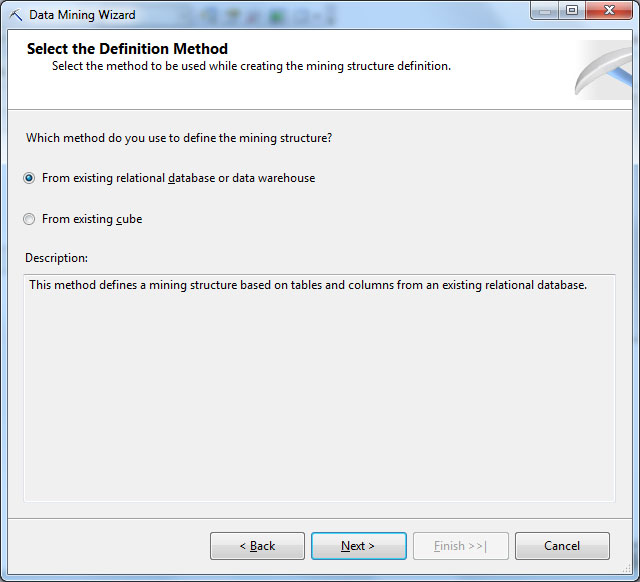
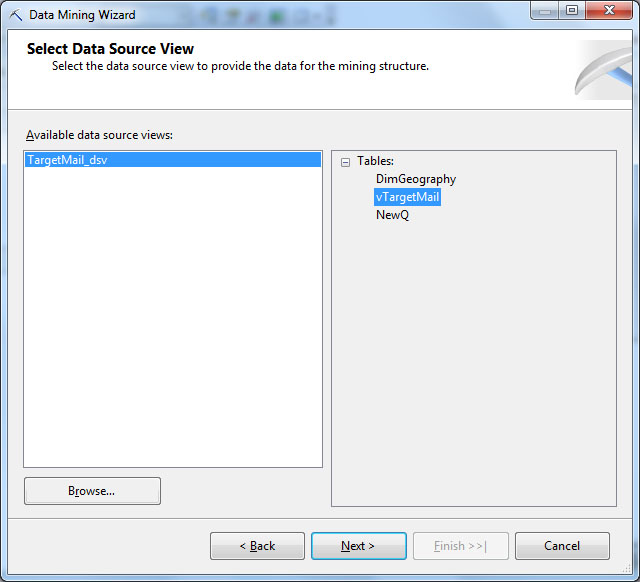
Следующий шаг - выбор между одновременным созданием структуры и модели интеллектуального анализа и только созданием структуры. Для решения поставленной задачи нам понадобится модель, использующая алгоритм кластеризации ( рис. 28.3). После чего будет предложено выбрать используемое представление источника данных. Пока в нашей базе DSV один, так что проблема выбора не стоит ( рис. 28.4).
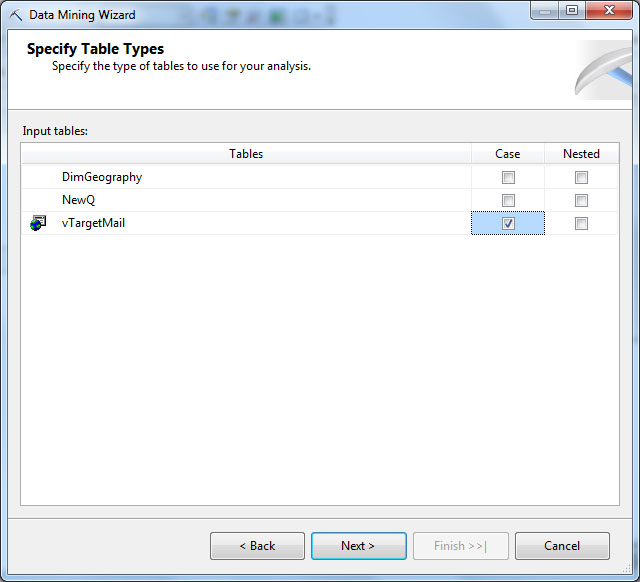
Следующий шаг - выбор таблицы вариантов и вложенных таблиц (если есть). В нашем случае, таблица вариантов - vTargetMail, вложенных таблиц нет ( рис. 28.5).

увеличить изображение
Рис. 28.3. Создание новой структуры и модели интеллектуального анализа: выбор алгоритма
увеличить изображение
Рис. 28.4. Создание новой структуры и модели интеллектуального анализа: выбор представления источника данных
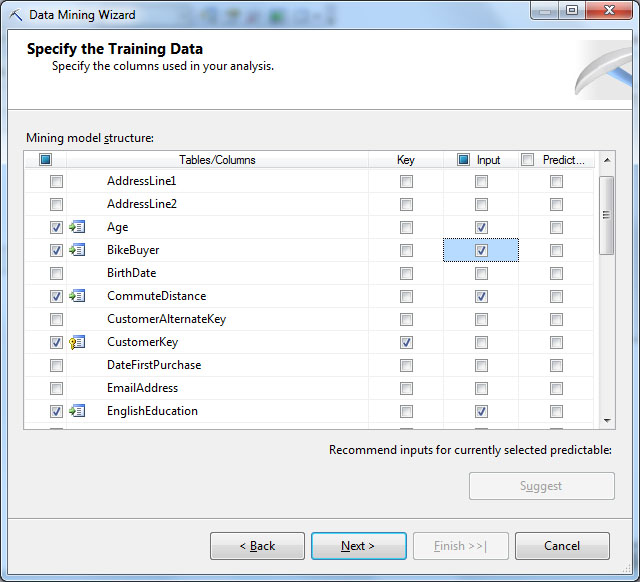
Далее потребуется указать ключевой столбец, входные столбцы и столбец, значение которого будет предсказываться. Ключевой столбец BIDevStudio определила автоматически, это первичный ключ таблицы CustomerKey ( рис. 28.6). В случае использования вложенных таблиц, указанию ключей надо уделить особое внимание. Для задачи кластеризации указание предсказываемого (Predictable) атрибута не требуется. А в качестве входных атрибутов будем использовать:
- Age (возрастклиента);
- BikeBuyer (признактого, чтоклиентприобрелвелосипед);
- CommuteDistance (расстояниедоработыилидругих "регулярных" поездок);
- EnglishEducation (образование);
- EnglishOccupation (должностьилиродзанятий);
- Gender (пол);
- NumberCarsOwned (числомашинвсобственности);
- NumberChildrenAtHome (числодетейдома, т.е. требующихприсмотра);
- Region (регион проживания);
- TotalChildren (общее число детей);
- YearlyIncome (годовой доход).
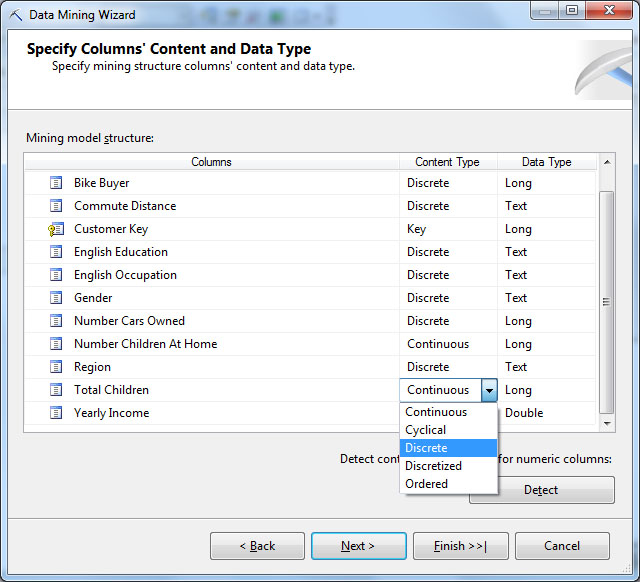
Следующий шаг - уточнение типов данных. На рис. 28.7 представлены исходные значения. Не все они могут быть признаны удачными. Например, тип содержимого (ContentType) атрибута TotalChildren установлен как "непрерывный" (Continious), тогда как более корректно был бы выбрать тип "дискретный", т.к. количество детей в семье будет принадлежать ограниченному множеству значений {0,1,2,..}. Можно изменить тип данных и тип содержимого вручную, выбирая нужное значение из выпадающего списка. А можно воспользоваться кнопкой Detect для автоматического определения. Правда в нашем случае тип содержимого для атрибутов TotalChildren и NumberChildrenAtHome придется менять все равно вручную.
После уточнения типов данных будет предложено зарезервировать часть данных для целей тестирования. В принципе, для решения задачи кластеризации тестовое множество создавать не требуется. Поэтому лучше здесь тестовый набор не создавать и в поле Percentageofdatafortesting указать значение 0%. В следующих лабораторных, когда мы будем решать задачу классификации, резервирование данных для тестирования будет необходимо.