Лекция 9: Логически прозрачные нейронные сети и производство явных знаний из данных
Логически прозрачные нейронные сети
Одним из основных недостатков нейронных сетей, с точки зрения многих пользователей, является то, что нейронная сеть решает задачу, но не может рассказать как. Иными словами из обученной нейронной сети нельзя извлечь алгоритм решения задачи. Однако специальным образом построенная процедура контрастирования позволяет решить и эту задачу.
Зададимся классом сетей, которые будем считать логически прозрачными (то есть такими, которые решают задачу понятным для нас способом, для которого легко сформулировать словесное описания в виде явного алгоритма). Например потребуем, чтобы все нейроны имели не более трех входных сигналов.
Зададимся нейронной сетью у которой все входные сигналы подаются на все нейроны входного слоя, а все нейроны каждого следующего слоя принимают выходные сигналы всех нейронов предыдущего слоя. Обучим сеть безошибочному решению задачи.
После этого будем производить контрастирование в несколько этапов. На первом этапе будем контрастировать только веса связей нейронов входного слоя. Если после контрастирования у некоторых нейронов осталось больше трех входных сигналов, то увеличим число входных нейронов. Затем аналогичную процедуру произведем поочередно для всех остальных слоев. После завершения описанной процедуры будет получена логически прозрачная сеть. Можно произвести дополнительное контрастирование сети, чтобы получить минимальную сеть. На рис. 9.2 приведены восемь минимальных сетей. Если под логически прозрачными сетями понимать сети, у которых каждый нейрон имеет не более трех входов, то все сети кроме пятой и седьмой являются логически прозрачными. Пятая и седьмая сети демонстрируют тот факт, что минимальность сети не влечет за собой логической прозрачности.
В качестве примера приведем интерпретацию алгоритма рассуждений, полученного по второй сети приведенной на рис. 9.2. Постановка задачи: по ответам на 12 вопросов необходимо предсказать победу правящей или оппозиционной партии. Ниже приведен список вопросов.
- Правящая партия была у власти более одного срока?
- Правящая партия получила больше 50% голосов на прошлых выборах?
- В год выборов была активна третья партия?
- Была серьезная конкуренция при выдвижении от правящей партии?
- Кандидат от правящей партии был президентом в год выборов?
- Был ли год выборов временем спада или депрессии?
- Был ли рост среднего национального валового продукта на душу населения больше 2.1%?
- Произвел ли правящий президент существенные изменения в политике?
- Во время правления были существенные социальные волнения?
- Администрация правящей партии виновна в серьезной ошибке или скандале?
- Кандидат от правящей партии - национальный герой?
- Кандидат от оппозиционной партии - национальный герой?
Ответы на вопросы описывают ситуацию на момент, предшествующий выборам. Ответы кодировались следующим образом: "да" - единица, "нет" - минус единица. Отрицательный сигнал на выходе сети интерпретируется как предсказание победы правящей партии. В противном случае ответом считается победа оппозиционной партии. Все нейроны реализовывали пороговую функцию, равную 1, если алгебраическая сумма входных сигналов нейрона больше либо равна 0, и -1 при сумме меньшей 0. Ответ сети базируется на проявлениях двух синдромов: синдрома политической нестабильности (сумма ответов на вопросы 3, 4 и 9) и синдрома плохой политики (ответы на вопросы 4, 8 и 6). Заметим что симптом несогласия в правящей партии вошел в оба синдрома. Таким образом, для победы правящей партии необходимо отсутствие ( -1 ) обоих синдромов.
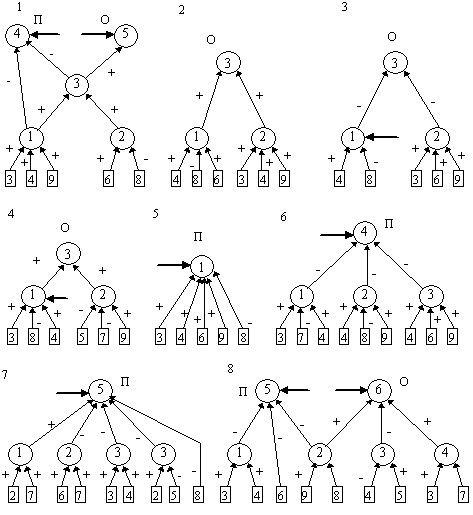

На рис. 9.2 приведены структуры шести логически прозрачных нейронных сетей, решающих задачу о предсказании результатов выборов президента США [9.6, 9.11]. Все сети, приведенные на этом рисунке минимальны в том смысле, что из них нельзя удалить ни одной связи так, чтобы сеть могла обучиться правильно решать задачу. По числу нейронов минимальна пятая сеть.
Заметим, что все попытки авторов обучить нейронные сети со структурами, изображенными на рис. 9.2, и случайно сгенерированными начальными весами связей закончились провалом. Все сети, приведенные на рис. 9.2, были получены из существенно больших сетей с помощью процедуры контрастирования. Сети 1, 2, 3 и 4 были получены из трехслойных сетей с десятью нейронами во входном и скрытом слоях. Сети 5, 6, 7 и 8 были получены из двухслойных сетей с десятью нейронами во входном слое. Легко заметить, что в сетях 2, 3, 4 и 5 изменилось не только число нейронов в слоях, но и число слоев. Кроме того, почти все веса связей во всех восьми сетях равны либо 1, либо -1.
Заключение
Технология получения явных знаний из данных с помощью обучаемых нейронных сетей выглядит довольно просто и вроде бы не вызывает проблем - необходимо ее просто реализовывать и пользоваться.
Первый этап: обучаем нейронную сеть решать базовую задачу. Обычно базовой является задача распознавания, предсказания (как в предыдущем разделе) и т.п. В большинстве случаев ее можно трактовать как задачу о восполнении пробелов в данных. Такими пробелами являются и имя образа при распознавании, и номер класса, и результат прогноза, и др.
Второй этап: с помощью анализа показателей значимости, контрастирования и доучивания (все это применяется, чаще всего, неоднократно) приводим нейронную сеть к логически прозрачному виду - так, чтобы полученный навык можно было "прочитать".
Полученный результат неоднозначен - если стартовать с другой начальной карты, то можно получить другую логически прозрачную структуру. Каждой базе данных отвечает несколько вариантов явных знаний. Можно считать это недостатком технологии, но мы полагаем, что, наоборот, технология, дающая единственный вариант явных знаний, недостоверна, а неединственность результата является фундаментальным свойством производства явных знаний из данных.
Работа выполнена при поддержке Красноярского краевого фонда науки, грант 6F0124.