Решение задач нейронными сетями
Сети Кохонена для кластер-анализа и классификации без учителя
Построение отношений на множестве объектов - одна из самых загадочных и открытых для творчества областей применения искусственного интеллекта. Первым и наиболее распространенным примером этой задачи является классификация без учителя. Задан набор объектов, каждому объекту сопоставлен вектор значений признаков (строка таблицы). Требуется разбить эти объекты на классы эквивалентности.
Естественно, прежде, чем приступать к решению этой задачи, нужно ответить на один вопрос: зачем производится это разбиение и что мы будем делать с его результатом? Ответ на него позволит приступить к формальной постановке задачи, которая всегда требует компромисса между сложностью решения и точностью формализации: буквальное следование содержательному смыслу задачи нередко порождает сложную вычислительную проблему, а следование за простыми и элегантными алгоритмами может привести к противоречию со здравым смыслом.
Итак, зачем нужно строить отношения эквивалентности между объектами? В первую очередь - для фиксации знаний. Люди накапливают знания о классах объектов - это практика многих тысячелетий, зафиксированная в языке: знание относится к имени класса (пример стандартной древней формы: "люди смертны", "люди" - имя класса). В результате классификации как бы появляются новые имена и правила их присвоения.
Для каждого нового объекта мы должны сделать два дела:
- найти класс, к которому он принадлежит;
- использовать новую информацию, полученную об этом объекте, для исправления (коррекции) правил классификации.
Какую форму могут иметь правила отнесения к классу? Веками освящена традиция представлять класс его "типичным", "средним", "идеальным" и т.п. элементом. Этот типичный объект является идеальной конструкцией, олицетворяющей класс.
Отнесение объекта к классу проводится путем его сравнения с типичными элементами разных классов и выбора ближайшего. Правила, использующие типичные объекты и меры близости для их сравнения с другими, очень популярны и сейчас.
Простейшая мера близости объектов - квадрат евклидового расстояния между векторами значений их признаков (чем меньше расстояние - расстояние - тем ближе объекты). Соответствующее определение признаков типичного объекта - среднее арифметическое значение признаков по выборке, представляющей класс.
Мы не оговариваем специально существование априорных ограничений, налагаемых на новые объекты - естественно, что "вселенная" задачи много 'уже и гораздо определеннее Вселенной.
Другая мера близости, естественно возникающая при обработке сигналов, изображений и т.п. - квадрат коэффициента корреляции (чем он больше, тем ближе объекты). Возможны и иные варианты - все зависит от задачи.
Если число классов m заранее определено, то задачу классификации без учителя можно поставить следующим образом.
Пусть {xp} - векторы значений признаков для рассматриваемых объектов и в пространстве таких векторов определена мера их близости 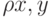 . Для определенности примем, что чем ближе объекты, тем меньше
. Для определенности примем, что чем ближе объекты, тем меньше 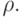 С каждым классом будем связывать его типичный объект. Далее называем его ядром класса. Требуется определить набор из m ядер y1, y2, ... ym и разбиение {xp} на классы:
С каждым классом будем связывать его типичный объект. Далее называем его ядром класса. Требуется определить набор из m ядер y1, y2, ... ym и разбиение {xp} на классы:
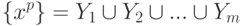
минимизирующее следующий критерий
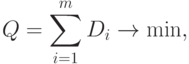 |
( 14) |
где для каждого ( i -го) класса 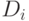 - сумма расстояний от принадлежащих ему точек выборки до ядра класса:
- сумма расстояний от принадлежащих ему точек выборки до ядра класса:
 |
( 15) |
Минимум Q берется по всем возможным положениям ядер 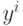 и всем разбиениям {xp} на m классов Yi.
и всем разбиениям {xp} на m классов Yi.
Если число классов заранее не определено, то полезен критерий слияния классов: классы Yi и Yj сливаются, если их ядра ближе, чем среднее расстояние от элемента класса до ядра в одном из них. (Возможны варианты: использование среднего расстояния по обоим классам, использование порогового коэффициента, показывающего, во сколько раз должно расстояние между ядрами превосходить среднее расстояние от элемента до ядра и др.)
Использовать критерий слияния классов можно так: сначала принимаем гипотезу о достаточном числе классов, строим их, минимизируя Q, затем некоторые Yi объединяем, повторяем минимизацию Q с новым числом классов и т.д.
Существует много эвристических алгоритмов классификации без учителя, основанных на использовании мер близости между объектами. Каждый из них имеет свою область применения, а наиболее распространенным недостатком является отсутствие четкой формализации задачи: совершается переход от идеи кластеризации прямо к алгоритму, в результате неизвестно, что ищется (но что-то в любом случае находится, иногда - неплохо).
Сетевые алгоритмы классификации без учителя строятся на основе итерационного метода динамических ядер. Опишем его сначала в наиболее общей абстрактной форме. Пусть задана выборка предобработанных векторов данных {xp}. Пространство векторов данных обозначим E. Каждому классу будет соответствовать некоторое ядро a. Пространство ядер будем обозначать A. Для каждых 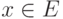 и
и 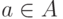 определяется мера близости d(x,a). Для каждого набора из k ядер a1,...,ak и любого разбиения {xp} на k классов
определяется мера близости d(x,a). Для каждого набора из k ядер a1,...,ak и любого разбиения {xp} на k классов  определим критерий качества:
определим критерий качества:
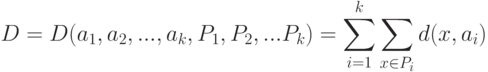 |
( 16) |
Требуется найти набор a1,...,ak и разбиение , минимизирующие D.