Опубликован: 06.08.2007 | Доступ: свободный | Студентов: 1935 / 1084 | Оценка: 4.45 / 4.29 | Длительность: 18:50:00
Тема: Программирование
Специальности: Программист
Лекция 8: Организация таблиц символов
Таблицы на деревьях
Рассмотрим еще один способ организации таблиц символов с использованием двоичных деревьев.
Ориентированное дерево называется двоичным, если у него в каждую вершину, кроме одной ( корня ), входит одна дуга, и из каждой вершины выходит не более двух дуг. Ветвью дерева называется поддерево, состоящее из некоторой дуги данного дерева, ее начальной и конечной вершин, а также всех вершин и дуг, лежащих на всех путях, выходящих из конечной вершины этой дуги. Высотой дерева называется максимальная длина пути в этом дереве от корня до листа.
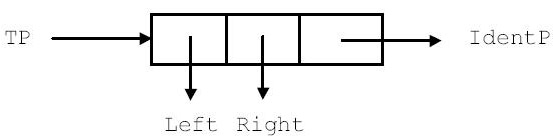
Пусть на множестве идентификаторов задан некоторый
линейный (например, лексикографический) порядок 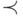 ,
то есть некоторое транзитивное, антисимметричное
и антирефлексивное отношение. Таким образом, для
произвольной пары идентификаторов id1 и id2 либо
,
то есть некоторое транзитивное, антисимметричное
и антирефлексивное отношение. Таким образом, для
произвольной пары идентификаторов id1 и id2 либо  , либо
, либо  , либо id1 совпадает с id2.
, либо id1 совпадает с id2.
Каждой вершине двоичного дерева, представляющего
таблицу символов, сопоставим идентификатор. При этом,
если вершина (которой сопоставлен id ) имеет левого потомка
(которому сопоставлен idL ), то  ; если имеет правого потомка (idR), то
; если имеет правого потомка (idR), то  . Элемент таблицы изображен на
рис.
7.5.
. Элемент таблицы изображен на
рис.
7.5.
Поиск в такой таблице может быть описан следующей функцией:
struct TreeElement * SearchTree(String Id,
struct TreeElement * TP)
{int comp;
if (TP==NULL) return NULL;
comp=IdComp(Id,TP->IdentP);
if (comp<0) return(SearchTree(Id,TP->Left));
if (comp>0) return(SearchTree(Id,TP->Right));
return TP;
}где структура для для элемента дерева имеет вид
struct TreeElement
{String IdentP;
struct TreeElement * Left, * Right;
};Занесение в таблицу осуществляется функцией
struct TreeElement * InsertTree(String Id,
struct TreeElement * TP)
{int comp=IdComp(Id,TP->IdentP);
if (comp<0) return(Fill(Id,TP->Left,
&(TP->Left)));
if (comp>0) return(Fill(Id,TP->Right,
&(TP->Right)));
return(TP);
}
struct TreeElement * Fill(String Id,
struct TreeElement * P,
struct TreeElement ** FP)
{ if (P==NULL)
{P=alloc(sizeof(struct TreeElement));
P->IdentP=Include(Id);
P->Left=NULL;
P->Right=NULL;
*FP=P;
return(P);
}
else return(InsertTree(Id,P));
}Как показано в работе [10], среднее время поиска в таблице размера n, организованной в виде двоичного дерева, при равной вероятности появления каждого объекта равно (2 ln 2) log2n + O(1). Однако, на практике случай равной вероятности появления объектов встречается довольно редко. Поэтому в дереве появляются более длинные и более короткие ветви, и среднее время поиска увеличивается.
Чтобы уменьшить среднее время поиска в двоичном дереве, можно в процессе построения дерева следить за тем, чтобы оно все время оставалось сбалансированным. А именно, назовем дерево сбалансированным, если ни для какой вершины высота выходящей из нее правой ветви не отличается от высоты левой более чем на 1. Для того, чтобы достичь сбалансированности, в процессе добавления новых вершин дерево можно слегка перестраивать следующим образом [1].
Определим для каждой вершины дерева характеристику, равную разности высот выходящих из нее правой и левой ветвей. В сбалансированном дереве характеристика вершины может быть равной -1, 0 и 1, для листьев она равна 0.
Пусть мы определили место новой вершины в дереве. Ее характеристика равна 0. Назовем путь, ведущий от корня к новой вершине, выделенным. При добавлении новой вершины могут измениться характеристики только тех вершин, которые лежат на выделенном пути. Рассмотрим заключительный отрезок выделенного пути, такой, что до добавления вершины характеристики всех вершин на нем были равны 0. Если верхним концом этого отрезка является сам корень, то дерево перестраивать не надо, достаточно лишь изменить характеристики вершин на этом пути на 1 или -1, в зависимости от того, влево или вправо пристроена новая вершина.
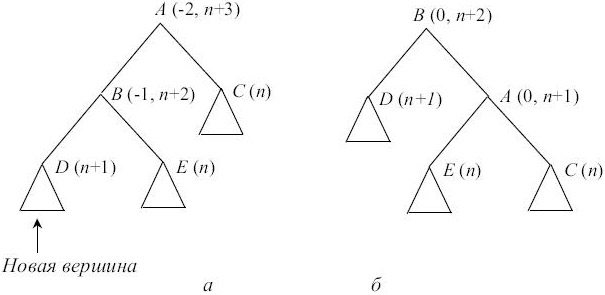
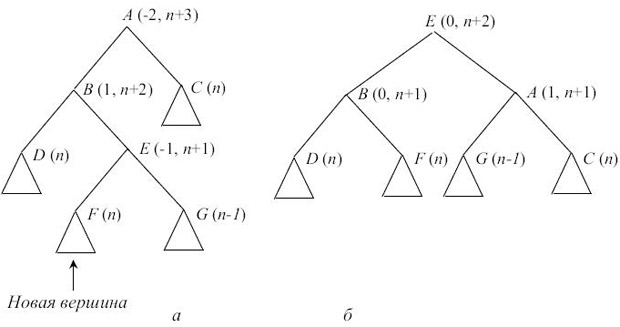
Пусть верхний конец заключительного отрезка - не
корень. Рассмотрим вершину A - "родителя" верхнего
конца заключительного отрезка. Перед добавлением новой
вершины характеристика A была равна  . Если A имела
характеристику 1 (-1) и новая вершина добавляется в левую
(правую) ветвь, то характеристика вершины A становится
равной 0, а высота поддерева с корнем в A не меняется. Так
что и в этом случае дерево перестраивать не надо.
Пусть теперь характеристика A до перестраивания была
равна -1 и новая вершина добавлена к левой ветви A
(аналогично - для случая 1 и добавления к правой ветви).
Рассмотрим вершину B - левого потомка A. Возможны
следующие варианты.
. Если A имела
характеристику 1 (-1) и новая вершина добавляется в левую
(правую) ветвь, то характеристика вершины A становится
равной 0, а высота поддерева с корнем в A не меняется. Так
что и в этом случае дерево перестраивать не надо.
Пусть теперь характеристика A до перестраивания была
равна -1 и новая вершина добавлена к левой ветви A
(аналогично - для случая 1 и добавления к правой ветви).
Рассмотрим вершину B - левого потомка A. Возможны
следующие варианты.

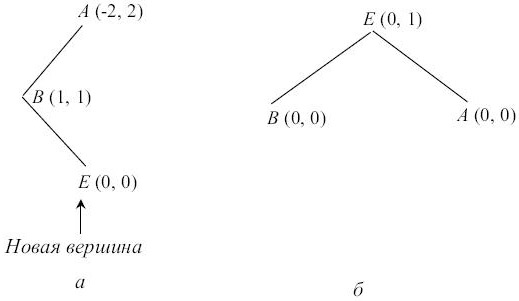
Если характеристика B после добавления новой вершины в D стала равна -1, то дерево имеет структуру, изображенную на рис. 7.6, а. Перестроив дерево так, как это изображено на рис. 7.6, б, мы добьемся сбалансированности (в скобках указаны характеристики вершин, где это существенно, и соотношения высот после добавления).
Если характеристика вершины B после добавления новой вершины в E стала равна 1, то надо отдельно рассмотреть случаи, когда характеристика вершины E, следующей за B на выделенном пути, стала равна -1, 1 и 0 (в последнем случае вершина E - новая). Вид дерева до и после перестройки для этих случаев показан соответственно на рис. 7.7, рис. 7.8 и рис. 7.9.
Реализация блочной структуры
С точки зрения структуры программы блоки (и/или процедуры) образуют дерево. Каждой вершине дерева этого представления, соответствующей блоку, можно сопоставить свою таблицу символов (и, возможно, одну общую таблицу идентификаторов). Работу с таблицами блоков можно организовать в магазинном режиме: при входе в блок создавать таблицу символов, при выходе - уничтожать. При этом сами таблицы должны быть связаны в упорядоченный список, чтобы можно было просматривать их в порядке вложенности. Если таблицы организованы с помощью функций расстановки, это означает, что для каждой таблицы должна быть создана своя таблица расстановки.
Сравнение методов реализации таблиц
Рассмотрим преимущества и недостатки рассмотренных методов реализации таблиц с точки зрения техники использования памяти.
Использование динамической памяти, как правило, довольно дорогая операция, поскольку механизмы поддержания работы с динамической памятью могут быть достаточно сложны. Необходимо поддерживать списки свободной и занятой памяти, выбирать наиболее подходящий кусок памяти при запросе, включать освободившийся кусок в список свободной памяти и, возможно, склеивать куски свободной памяти в списке.
С другой стороны, использование массива требует отведения заранее довольно большой памяти, а это означает, что значительная память вообще не будет использоваться. Кроме того, часто приходится заполнять не все элементы массива (например, в таблице идентификаторов или в тех случаях, когда в массиве фактически хранятся записи переменной длины, например, если в таблице символов записи для различных объектов имеют различный состав полей). Обращение к элементам массива может означать использование операции умножения при вычислении индексов, что может замедлить исполнение.
Наилучшим, по-видимому, является механизм доступа по указателям и использование факта магазинной организации памяти в компиляторе. Для этого процедура выделения памяти выдает необходимый кусок из подряд идущей памяти, а при выходе из процедуры вся память, связанная с этой процедурой, освобождается простой перестановкой указателя свободной памяти в состояние перед началом обработки процедуры. В чистом виде это не всегда, однако, возможно. Например, локальный модуль в Модуле-2 может экспортировать некоторые объекты наружу. При этом схему реализации приходится "подгонять" под механизм распределения памяти. В данном случае, например, необходимо экспортированные объекты вынести в среду охватывающего блока и свернуть блок локального модуля.