Опубликован: 06.08.2007 | Доступ: свободный | Студентов: 1933 / 1084 | Оценка: 4.45 / 4.29 | Длительность: 18:50:00
Тема: Программирование
Специальности: Программист
Лекция 4:
Лексический анализ
Функция followpos может быть вычислена также за один обход дерева снизу-вверх по таким двум правилам.
- Пусть n - внутренний узел с операцией
 (конкатенация), u и v - его потомки. Тогда для каждой
позиции i, входящей в lastpos(u), добавляем к множеству
значений followpos(i) множество firstpos(v).
(конкатенация), u и v - его потомки. Тогда для каждой
позиции i, входящей в lastpos(u), добавляем к множеству
значений followpos(i) множество firstpos(v). - Пусть n - внутренний узел с операцией * (итерация), u - его потомок. Тогда для каждой позиции i, входящей в lastpos(u), добавляем к множеству значений followpos(i) множество firstpos(u).
Пример 3.8. Результат вычисления функции followpos для регулярного выражения из предыдущего примера приведен на рис. 3.13.
Алгоритм 3.3. Прямое построение ДКА по регулярному выражению.
Вход. Регулярное выражение r в алфавите T.
Выход. ДКА M = (Q, T, D, q0, F), такой что L(M) = L(r).
Метод. Состояния ДКА соответствуют множествам позиций.
Вначале Q и D пусты. Выполнить шаги 1-6:
(1) Построить синтаксическое дерево для пополненного регулярного выражения (r)#.
(2) Обходя синтаксическое дерево, вычислить значения функций nullable, firstpos, lastpos и followpos.
(3) Определить q0 = firstpos(root), где root - корень синтаксического дерева.
(4) Добавить q0 в Q как непомеченное состояние.
(5) Выполнить следующую процедуру:

(6) Определить F как множество всех состояний из Q, содержащих позиции, связанные с символом #.
Пример 3.9. Результат применения алгоритма 3.3 для регулярного выражения (a|b)*abb приведен на рис. 3.14.

Построение детерминированного конечного автомата с минимальным числом состояний
Рассмотрим теперь алгоритм построения ДКА с минимальным числом состояний, эквивалентного данному ДКА [?].
Пусть M = (Q, T, D, q0, F) - ДКА. Будем называть M
всюду определенным, если 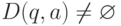 , для всех
, для всех 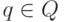 и
и 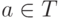 .
.
Лемма. Пусть M = (Q, T, D, q0, F) - ДКА, не являющийся всюду определенным. Существует всюду определенный ДКА M' , такой что L(M) = L(M').
Доказательство. Рассмотрим автомат
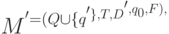
где 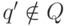 - некоторое новое состояние, а функция D'
определяется следующим образом:
- некоторое новое состояние, а функция D'
определяется следующим образом:
(1) Для всех и , таких что ,,
определить D'(q, a) = D(q, a).
(2) Для всех и , таких что 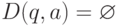 ,
определить D'(q, a) = q'.
,
определить D'(q, a) = q'.
(3) Для всех определить D'(q', a) = q'.
Легко показать, что автомат M' допускает тот же язык, что и M.
Приведенный ниже алгоритм получает на входе всюду определенный автомат. Если автомат не является всюду определенным, его можно сделать таковым на основании только что приведенной леммы.
Алгоритм 3.4.Построение ДКА с минимальным числом состояний.
Вход. Всюду определенный ДКА M = (Q, T, D, q0, F).
Выход. ДКА 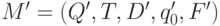 , такой что L(M) = L(M') и M' содержит наименьшее возможное число
состояний.
, такой что L(M) = L(M') и M' содержит наименьшее возможное число
состояний.
Метод. Выполнить шаги 1-5:
(1) Построить начальное разбиение  множества состояний
из двух групп: заключительные состояния Q и
остальные Q - F, то есть
множества состояний
из двух групп: заключительные состояния Q и
остальные Q - F, то есть 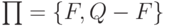 .
.
(2) Применить к следующую процедуру и получить новое
разбиение  :
:
for (каждой группы G в П){
разбить G на подгруппы так, чтобы
состояния s и t из G оказались
в одной подгруппе тогда и только тогда,
когда для каждого входного символа a
состояния s и t имеют переходы по a
в состояния из одной и той же группы в П,
заменить G в П new на множество всех
полученных подгрупп,
}(3) Если =  полагаем
полагаем 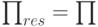 и переходим к шагу
4, иначе повторяем шаг 2 с
и переходим к шагу
4, иначе повторяем шаг 2 с 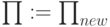 .
.
(4) 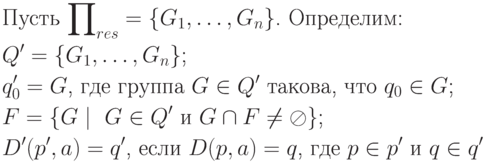
Таким образом, каждая группа в 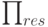 становится
состоянием нового автомата M'. Если группа содержит
начальное состояние автомата M, то эта группа
становится начальным состоянием автомата M'. Если
группа содержит заключительное состояние M, она
становится заключительным состоянием M'. Отметим,
что каждая группа либо состоит только из
состояний из F, либо не имеет состояний из F. Переходы
определяются очевидным образом.
становится
состоянием нового автомата M'. Если группа содержит
начальное состояние автомата M, то эта группа
становится начальным состоянием автомата M'. Если
группа содержит заключительное состояние M, она
становится заключительным состоянием M'. Отметим,
что каждая группа либо состоит только из
состояний из F, либо не имеет состояний из F. Переходы
определяются очевидным образом.
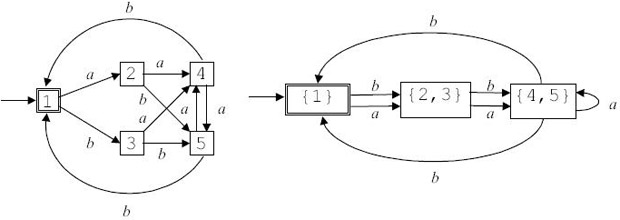
(5) Если M' имеет "мертвое"состояние, то есть состояние, которое не является допускающим и из которого нет путей в допускающие, удалить его и связанные с ним переходы из M'. Удалить из M' также все состояния, недостижимые из начального.
Пример 3.10. Результат применения алгоритма 3.4 приведен на рис. 3.15.