
|
Нахожу в тесте вопросы, которые в принципе не освещаются в лекции. Нужно гуглить на других ресурсах, чтобы решить тест, или же он всё же должен испытывать знания, полученные в ходе лекции? |
Опубликован: 02.09.2013 | Доступ: свободный | Студентов: 429 / 54 | Длительность: 19:27:00
Тема: Программирование
Специальности: Программист, Системный архитектор
Самостоятельная работа 3:
Машинное обучение
2.4. Случайный лес
Случайный лес является бэггинг алгоритмом, основная идея которого заключается в построении как можно менее зависимых друг от друга деревьев решений, с последующим принятием решения путем усреднения в случае регрессии и голосованием в случае классификации. Зависимость между деревьями снижается за счет использования случайной выборки с возвращением из исходных прецедентов и случайного подмножества признаков.
Алгоритм случайного леса реализован в библиотеке OpenCV в виде класса CvRTrees. Рассмотрим принципы работы с данным классом. Для обучения случайного леса предназначен метод train:
bool train( const Mat< trainData,
int tflag,
const Mat< responses,
const Mat< varIdx=Mat(),
const Mat< sampleIdx=Mat(),
const Mat< varType=Mat(),
const Mat< missingDataMask=Mat(),
CvRTParams params=CvRTParams() );Назначение и формат параметров данного метода целиком совпадает с методом CvDTree::train, реализующим обучение одиночного дерева решений, за исключением параметров алгоритма обучения. Параметры случайного леса представляются в виде структуры CvRTParams:
struct CvRTParams : public CvDTreeParams
{
bool calc_var_importance;
int nactive_vars;
CvTermCriteria term_crit;
CvRTParams();
CvRTParams( int max_depth,
int min_sample_count,
float regression_accuracy,
bool use_surrogates,
int max_categories,
const float* priors,
bool calc_var_importance,
int nactive_vars,
int max_num_of_trees_in_the_forest,
float forest_accuracy,
int termcrit_type );
}; Так как алгоритм случайного леса строит деревья решений, большинство параметров определяют настройки алгоритма обучения одиночных деревьев (см. описание структуры CvDTreeParams). Следует отметить, что в рамках модели случайного леса обучаются большие (оригинальный подход [4] не подразумевал ограничение высоты дерева как критерий останова его построения) деревья решений без последующего применения процедуры отсечения. Теперь рассмотрим параметры, имеющие отношение непосредственно к модели случайного леса:
-
nactive_vars – количество признаков, выбираемых случайным
образом для обучения каждого дерева решений. Если
nactive_vars=0, то при обучении дерева будет использоваться
целая часть снизу от
 признаков, если же указано значение
nactive_vars>0, то min(nactive_vars, d ) признаков.
признаков, если же указано значение
nactive_vars>0, то min(nactive_vars, d ) признаков. - term_crit – критерий прекращения добавления деревьев в ансамбль (лес). Так как при обучении каждого дерева используются не все прецеденты обучающей выборки, то неиспользуемая часть выборки (out-of-bag samples) может быть использована в качестве тестовой для оценки качества модели (out-of-bag error, oob error). В связи с этим появляется возможность прекратить построение новых деревьев, при достижении достаточно малой oob ошибки. Структура CvTermCriteria была рассмотрена выше (см. описание CvSVMParams), здесь отметим лишь, что значение term_crit.max_iter задает максимальное количество обучаемых деревьев, term_crit.epsilon – максимальную допустимую oob ошибку, term_crit.type – тип используемого критерия останова.
- calc_var_importance – флаг, определяющий необходимость вычисления значимости переменных в ходе обучения модели случайного леса.
Для осуществления предсказаний в классе CvRTrees предназначен метод predict:
float predict( const Mat< sample,
const Mat< missing=Mat() ) const;
Параметрами метода являются признаковое описание объекта и маска пропущенных значений в данном описании. Возвращаемое значение соответствует предсказанной величине целевого признака.
Методы save и load, осуществляющие сохранение и загрузку модели соответственно, применяются аналогично данным методам классов CvSVM и CvDTree.
Приведем пример использования класса CvRTrees для решения задачи бинарной классификации и иллюстрацию порождаемого обученной моделью разбиения пространства признаков (см. рис. 10.3).
#include <stdlib.h>
#include <stdio.h>
#include <opencv2/core/core.hpp>
#include <opencv2/ml/ml.hpp>
using namespace cv;
// размерность пространства признаков
const int d = 2;
// функция истинной зависимости целевого признака
// от остальных
int f(Mat sample)
{
return (int)((sample.at<float>(0) < 0.5f &&
sample.at<float>(1) < 0.5f) ||
(sample.at<float>(0) > 0.5f &&
sample.at<float>(1) > 0.5f));
}
int main(int argc, char* argv[])
{
// объем генерируемой выборки
int n = 2000;
// объем обучающей части выборки
int n1 = 1000;
// матрица признаковых описаний объектов
Mat samples(n, d, CV_32F);
// номера классов (матрица значений целевой переменной)
Mat labels(n, 1, CV_32S);
// генерируем случайным образом точки
// в пространстве признаков
randu(samples, 0.0f, 1.0f);
// вычисляем истинные значения целевой переменной
for (int i = 0; i < n; ++i)
{
labels.at<int>(i) = f(samples.row(i));
}
// создаем маску прецедентов, которые будут
// использоваться для обучения: используем n1
// первых прецедентов
Mat trainSampleMask(1, n1, CV_32S);
for (int i = 0; i < n1; ++i)
{
trainSampleMask.at<int>(i) = i;
}
// будем обучать случайный лес из 250 деревьев
// высоты не больше 10
CvRTParams params;
params.max_depth = 10;
params.min_sample_count = 1;
params.calc_var_importance = false;
params.term_crit.type = CV_TERMCRIT_ITER; params.term_crit.max_iter = 250;
CvRTrees rf;
Mat varIdx(1, d, CV_8U, Scalar(1));
Mat varTypes(1, d + 1, CV_8U, Scalar(CV_VAR_ORDERED));
varTypes.at<uchar>(d) = CV_VAR_CATEGORICAL;
rf.train(samples, CV_ROW_SAMPLE,
labels, varIdx,
trainSampleMask, varTypes,
Mat(), params);
rf.save("model-rf.yml", "simpleRTreesModel");
// вычисляем ошибку на обучающей выборке
float trainError = 0.0f;
for (int i = 0; i < n1; ++i)
{
int prediction =
(int)(rf.predict(samples.row(i)));
trainError += (labels.at<int>(i) != prediction);
}
trainError /= float(n1);
// вычисляем ошибку на тестовой выборке
float testError = 0.0f;
for (int i = 0; i < n - n1; ++i)
{
int prediction =
(int)(rf.predict(samples.row(n1 + i)));
testError +=
(labels.at<int>(n1 + i) != prediction);
}
testError /= float(n - n1);
printf("train error = %.4f\ntest error = %.4f\n",
trainError, testError);
return 0;
}
Андрей Терёхин
Демянчик Иван
|
В главе 14 мы видим понятие фильтра, но не могу разобраться, чем он является в теории и практике. " Искомый объект можно описать с помощью фильтра |
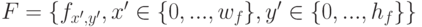 "
"