|
Нахожу в тесте вопросы, которые в принципе не освещаются в лекции. Нужно гуглить на других ресурсах, чтобы решить тест, или же он всё же должен испытывать знания, полученные в ходе лекции? |
Опубликован: 02.09.2013 | Доступ: свободный | Студентов: 429 / 54 | Длительность: 19:27:00
Тема: Программирование
Специальности: Программист, Системный архитектор
Самостоятельная работа 3:
Машинное обучение
Последним нерассмотренным полем структуры CvSVMParams является term_crit. Данная переменная содержит параметры итерационного метода, используемого для решения оптимизационной задачи на этапе обучения. Данные параметры указываются с помощью следующей структуры:
struct CvTermCriteria
{
int type;
int max_iter;
double epsilon;
};
Рассмотрим поля данной структуры:
- type – вид критерия останова: по точности (CV_TERMCRIT_EPS) или по количеству итераций (CV_TERMCRIT_ITER). Значение type, равное CV_TERMCRIT_EPS + CV_TERMCRIT_ITER, применяется в случае, когда используются оба критерия.
- max_iter – максимальное количество итераций.
- epsilon – пороговое значение точности.
Для использования обученной ранее модели в классе CvSVM используются методы
float predict( const Mat< sample,
bool returnDFVal=false ) const;
void predict( InputArray samples,
OutputArray results ) const;
Рассмотрим их параметры.
-
sample – матрица-вектор типа CV_32F и размера
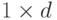 ,
содержащая координаты одной точки в пространстве признаков.
,
содержащая координаты одной точки в пространстве признаков. -
returnDFVal – флаг, позволяющий получать расстояние со
знаком от разделяющей поверхности до указанной точки. Если
returnDFVal=true и решается задача бинарной классификации,
то возвращаемым значением будет величина
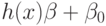 , иначе
будет возвращено предсказанное значение целевого признака.
, иначе
будет возвращено предсказанное значение целевого признака. -
samples – матрица типа CV_32F и размера
 , построчно
содержащая координаты точек в пространстве признаков, для
которых необходимо сделать предсказания.
, построчно
содержащая координаты точек в пространстве признаков, для
которых необходимо сделать предсказания. - results – матрица-вектор, в которую будут сохранены предсказанные значения.
Для сохранения обученной модели используется метод
void save( const char* filename,
const char* name=0 ) const;
Параметры данного метода:
- filename – путь и имя файла, в который будет сохранена модель. В OpenCV поддерживается запись в XML- и YAML-файлы.
- name – имя, под которым будет сохранена модель. Имя модели может состоять из строчных и заглавных букв латинского алфавита, цифр, символов ‘-’ и ‘_’. В случае сохранения в YAML-формате также допустимо использование пробелов.
Загрузка модели из файла осуществляется методом
void load( const char* filename, const char* name=0 );
Рассмотрим его параметры:
- filename – XML- или YAML-файл, из которого будет выполнена загрузка.
- name – имя модели, которую требуется загрузить.
Также в классе CvSVM реализован метод, позволяющий получить количество опорных векторов:
int get_support_vector_count() const;
и метод для получения опорного вектора с номером :
const float* get_support_vector(int i) const;
Рассмотрим пример использования класса CvSVM для решения задачи классификации.
#include <stdlib.h>
#include <stdio.h>
#include <opencv2/core/core.hpp>
#include <opencv2/ml/ml.hpp>
using namespace cv;
// размерность пространства признаков
const int d = 2;
// функция истинной зависимости целевого признака
// от остальных
int f(Mat sample)
{
return (int)((sample.at<float>(0) < 0.5f &&
sample.at<float>(1) < 0.5f) ||
(sample.at<float>(0) > 0.5f &&
sample.at<float>(1) > 0.5f));
}
int main(int argc, char* argv[]) {
// объем генерируемой выборки
int n = 2000;
// объем обучающей части выборки
int n1 = 1000;
// матрица признаковых описаний объектов
Mat samples(n, d, CV_32F);
// номера классов (матрица значений целевой переменной)
Mat labels(n, 1, CV_32S);
// генерируем случайным образом точки
// в пространстве признаков
randu(samples, 0.0f, 1.0f);
// вычисляем истинные значения целевой переменной
for (int i = 0; i < n; ++i)
{
labels.at<int>(i) = f(samples.row(i));
}
// создаем маску прецедентов, которые будут
// использоваться для обучения: используем n1
// первых прецедентов
Mat trainSampleMask(1, n1, CV_32S);
for (int i = 0; i < n1; ++i)
{
trainSampleMask.at<int>(i) = i;
}
// используем SVM типа C_SVC и радиальным ядром
CvSVMParams params;
params.svm_type = CvSVM::C_SVC;
params.kernel_type = CvSVM::RBF;
params.gamma = 1.0;
params.C = 1.0;
CvSVM svm;
svm.train(samples, labels,
Mat(), trainSampleMask, params);
svm.save("model.yml", "simpleSVMModel");
// вычисляем ошибку на обучающей выборке
Mat predictions;
svm.predict(samples.rowRange(0, n1), predictions);
float trainError = 0.0f;
for (int i = 0; i < n1; ++i)
{
trainError += (labels.at<int>(i) !=
(int)(predictions.at<float>(i)));
} trainError /= float(n1);
// вычисляем ошибку на тестовой выборке
predictions = Mat();
svm.predict(samples.rowRange(n1, n), predictions);
float testError = 0.0f;
for (int i = 0; i < n - n1; ++i)
{
testError += (labels.at<int>(n1 + i) !=
(int)(predictions.at<float>(i)));
}
testError /= float(n - n1);
printf("train error = %.4f\ntest error = %.4f\n",
trainError, testError);
return 0;
}
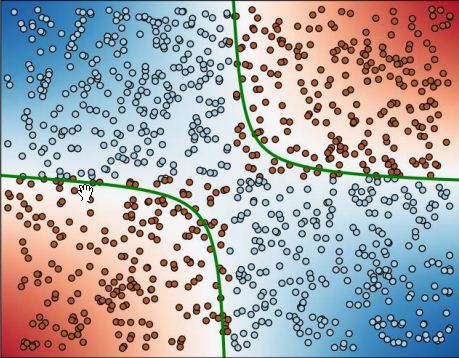
Визуальное представление данных и построенной границы между точками разных классов приведено на рис. 10.1.
Андрей Терёхин
Демянчик Иван
|
В главе 14 мы видим понятие фильтра, но не могу разобраться, чем он является в теории и практике. " Искомый объект можно описать с помощью фильтра |
 "
"