|
Нахожу в тесте вопросы, которые в принципе не освещаются в лекции. Нужно гуглить на других ресурсах, чтобы решить тест, или же он всё же должен испытывать знания, полученные в ходе лекции? |
Опубликован: 02.09.2013 | Доступ: свободный | Студентов: 433 / 55 | Длительность: 19:27:00
Тема: Программирование
Специальности: Программист, Системный архитектор
Самостоятельная работа 6: Сравнение производительности некоторых алгоритмов в библиотеках OpenCV и IPP
Аннотация: Работа построена следующим образом: в начале демонстрируется процесс разработки программного приложения, позволяющего единообразно организовать запуск экспериментов по сравнению производительности. Далее поясняется, как можно выполнить сравнение для алгоритмов медианной фильтрации, эрозии, дилатации, построения гистограммы. Приводятся результаты первых прикидочных экспериментов, даются рекомендации и задания для самостоятельной проработки.
Ключевые слова: производительность, размерность, программа, путь, алгоритм, константы, память, MSD, LSD, исполнение, анализ, упорядоченный массив, репрезентативность, антивирус, amplifier, trace, GPU, visual, mic, профилировщик, интерпретация, IPP, минимум
Введение
Презентацию к лабораторной рабте Вы можете скачать здесь.
Дополнительные материалы к лабораторной работе Вы можете скачать здесь.
Производительность является одной из важнейших характеристик программного обеспечения. Так, например, при мониторинге состояния технических объектов от времени, необходимого на предсказание или диагностику возможной неисправности, может зависеть жизнь и здоровье людей. В различных "офисных" приложениях производительность существенно влияет на потребительские свойства продукта и его субъективное восприятие пользователями. В научных приложениях время счета может, в частности, ограничивать размерность решаемых задач, лимитируя возможности ученых по моделированию и исследованию физических, химических, экономических и других процессов. Наконец, в некоторых случаях недостаточно эффективно работающая программа в принципе не позволяет решать поставленную задачу на доступной вычислительной системе за приемлемое время. Заметим, что экстенсивный путь, состоящий в увеличении мощности аппаратной части является затратным с финансовой точки зрения, приводит к необходимости использования дополнительных площадей, увеличивает потребление электроэнергии и, что особенно важно, далеко не всегда приводит к решению проблемы. Перечисленные факторы определяют актуальность постановки вопроса о разработке высокопроизводительного программного обеспечения, эффективно работающего на современных вычислительных системах.
Для достижения хорошей эффективности прежде всего необходимо определиться с тем, что это такое, и научиться ее оценивать, как теоретически, так и экспериментально. Эффективность работы алгоритма и соответствующей ему программы можно понимать по-разному. Теория сложности вычислений (см., например, [1]) предоставляет методику теоретического изучения вопроса о времени работы алгоритма в зависимости от размера задачи (объема входных данных). Построенные оценки сложности часто позволяют определить, какой алгоритм является более подходящим для решения задачи. Однако не все так просто. Во-первых, существует немало задач, построение оценок для которых является далеко не тривиальным. Во-вторых, в ряде случаев оказывается, что более эффективные с точки зрения теории алгоритмы на практике проигрывают их, казалось бы, менее эффективным аналогам. Так, например, в задаче умножения матриц алгоритм Копперсмита-Винограда [2], имеющий отличные показатели эффективности, обычно не используется на практике в связи с наличием большой константы в оценке сложности. Выясняется, что в машинной реализации матрицы, при умножении которых мог бы достигаться выигрыш, просто не убираются в оперативную память, из-за чего на первый план выходят совершенно другие вопросы. Иногда хороший в теории алгоритм может плохо "ложиться" на архитектуру современных вычислительных систем. Заметим, что в случае использования параллельных систем ситуация еще более запутывается. Некоторые "хорошие" последовательные алгоритмы плохо поддаются распараллеливанию, что приводит к необходимости использования параллельных модификаций менее эффективных в последовательном случае алгоритмов (пример: алгоритмы сортировки MSD Sort и LSD Sort [10]) либо к разработке принципиально новых алгоритмов, изначально ориентированных на параллельное исполнение. В итоге мы можем заключить, что вопрос оценки эффективности алгоритма и соответствующей ему программы на практике является весьма сложным и, к сожалению, не всегда поддается исключительно теоретическому анализу, требуя проведения вычислительных экспериментов и соответствующей оценки производительности.
Оценка и анализ производительности – вещи субъективные, во многом зависящие от методики постановки и анализа результатов вычислительного эксперимента. Правильная постановка эксперимента для анализа производительности крайне важна. Так, например, подавая уже упорядоченный массив на вход сортировки пузырьком, можно получить великолепные показатели времени работы и ошибочно признать соответствующую реализацию лучшей (важный момент: репрезентативность исходных данных). Примером другой распространенной ошибки являются выводы по результатам одиночного запуска, во время которого неожиданно "проснулся" установленный в системе антивирус, поглотив при этом половину имеющихся ресурсов (важный момент: нивелирование наведенных эффектов). Существуют и другие виды ошибок [3]. Анализ полученных данных о производительности тоже не прост. Для помощи разработчикам программного обеспечения созданы специальные инструменты – профилировщики, помогающие ответить на вопрос: где программа тратила процессорное время? Такие профилировщики помогают анализировать ситуацию в последовательных системах (Intel VTune и др.), в параллельных системах с общей памятью (Intel VTune Amplifier XE и др.), в параллельных системах с распределенной памятью (Intel Trace Collector/Analyzer и др.), в системах с использованием ускорителей GPU (NVIDIA Visual Profiler и др.) и MIC (Intel VTune Amplifier XE). Тем не менее, профилировщик лишь собирает для разработчиков статистическую информацию. Ее правильная интерпретация является нашей задачей. Таким образом, правильно поставить эксперимент по оценке производительности, интерпретировать его результаты, при необходимости внести изменения в программный код весьма непросто. Подобная работа требует существенных теоретических знаний и практических навыков [4-7].
Данная лабораторная работа не дает исчерпывающего описания методики анализа эффективности алгоритмов и программ, и, тем более, не учит оптимизировать программы по скорости их работы. В контексте курса по разработке мультимедийных приложений с использованием библиотек OpenCV и IPP работа закрепляет сформированные навыки использования библиотек, а также предлагает сравнить производительность функциональности, присутствующей в обеих библиотеках, на тестовых задачах.
Основная идея работы заключается вовсе не в том, чтобы показать, что библиотека IPP работает быстрее библиотеки OpenCV или наоборот. Отметим, что постановка вопроса "Кто быстрее?" в данном случае как минимум крайне сомнительна, хотя бы потому, что библиотеки существенно отличаются по назначению и реализованной функциональности. В тех же случаях, когда в обеих библиотеках присутствуют методы решения одних и тех же задач, эти методы не всегда совпадают. В связи с этим для одинаковых входных данных средствами OpenCV и IPP можно получить несколько разные результаты; постановка вопроса о сравнении производительности в этом случае выглядит сомнительно. Тем не менее, в ряде случаев библиотеки предоставляют реализации одних и тех же алгоритмов, применимых при решении задач компьютерного зрения [8, 9], что и обуславливает практический интерес к вопросу о том, что работает быстрее. Производительность некоторых таких алгоритмов сравнивается в данной лабораторной работе.
1. Методические указания
1.1. Цели и задачи работы
Целью работы является сравнение производительности некоторых алгоритмов, реализованных как в библиотеке OpenCV, так и в библиотеке IPP.
Для достижения данной цели необходимо решить следующие задачи:
- Построить каркас приложения для сравнения производительности, включающий функции загрузки изображения, возможность запуска алгоритмов из библиотеки OpenCV и IPP, сравнения результатов работы алгоритмов, измерения времени работы.
- Запрограммировать вызов алгоритмов медианной фильтрации, эрозии, дилатации, построения гистограммы из библиотек OpenCV и IPP.
- Подобрать подходящие тестовые данные.
- Запустить приложение на выбранных данных, сравнить время работы алгоритмов.
1.2. Структура работы
Работа построена следующим образом: в начале демонстрируется процесс разработки программного приложения, позволяющего единообразно организовать запуск экспериментов по сравнению производительности. Далее поясняется, как можно выполнить сравнение для алгоритмов медианной фильтрации, эрозии, дилатации, построения гистограммы. Приводятся результаты первых прикидочных экспериментов, даются рекомендации и задания для самостоятельной проработки.
1.3. Тестовая инфраструктура
В работе использовалось следующее аппаратное и программное обеспечение:
- CPU: Intel Core2 Quad Q9550 2.83 GHz.
- RAM: 5 GB.
- OS: Windows 7 Pro SP1.
- Microsoft Visual Studio 2010.
- IPP из Intel Parallel Studio 2013 XE.
- OpenCV 2.4.2.
1.4. Рекомендации по проведению занятий
Рекомендуется придерживаться следующей последовательности при проведении занятия:
- Выяснить у слушателей степень их владения библиотеками OpenCV и IPP. При необходимости кратко охарактеризовать функциональность и область назначения библиотек, показать примеры работы с ними (см. лабораторные работы, направленные на освоение OpenCV и IPP).
- Совместно со слушателями разработать каркас тестового приложения. В случае недостатка времени дать слушателям готовый каркас приложения в исходных кодах и объяснить его наполнение.
- Реализовать вызов тестируемых алгоритмов (медианная фильтрация, эрозия, дилатация, построение гистограммы).
- Убедиться в корректности программы.
- Сравнить производительность при запуске на одном изображении.
- Предложить слушателям расширить приложение для запуска на серии изображений (либо зациклить обработку одного изображения).
- Обсудить полученные результаты и перспективы совместного использования OpenCV и IPP.
Андрей Терёхин
Демянчик Иван
|
В главе 14 мы видим понятие фильтра, но не могу разобраться, чем он является в теории и практике. " Искомый объект можно описать с помощью фильтра |
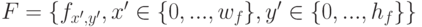 "
"