Инспектор
Вы можете этот курс.
Опубликован: 12.07.2010 | Уровень: специалист | Доступ: платный | ВУЗ: Алтайский государственный университет
Лекция 4:
Многоядерные процессоры с низким энергопотреблением
SERDES
Процессор обладает двумя высокоскоростными последовательными интерфейсами –SERDES, расположенными в двух ядрах по разные стороны процессора – в 1м и в 31м. Средняя скорость передачи данных по SERDES около 400 Мбит/с, режим передачи полудуплексный.
Для выдачи данных через SERDES последовательность действий следующая – надо записать передаваемое слово по адресу DATA, включить кольцевой тактовый генератор приемопередатчика (запись $20000 по адресу IOR), записать любое слово по адресу UP (ожидание окончания передачи предыдущего слова), выключить тактовый генератор после задержки в 18 тактов.
Пример бесконечного цикла выдачи значения через SERDES
01 {node 0 org here =p
'data # a! \ инициализировать регистр а значением DATA
Begin
$0505 # !a \ записать число по адресу в регистре а (data)
$20000 # 'iocs # b! !b \ записать в b адрес ior
\ и записать по этому адресу код включения тактового генеротора
0 # dup '---u # b! !b \ пустая запись по адресу UP
| 18 # for . unext \ цикл ожидания окончания передачи
'iocs # b! !b \ выключение генератора
| 10000 # for . unext | \ пауза между передачами (около 15 мкс)
again
node}Цифровая фильтрация - КИХ-фильтр
Одно из часто встречающихся применений данных процессоров (собственно оно является одним из целевых для процессоров этой серии) - обработка сигналов в реальном времени.
Рассмотрим один из наиболее распространенных алгоритмов цифровой обработки сигналов – цифровую фильтрацию [18]. В ряде областей применения популярно использовать КИХ или БИХ фильтры довольно высоких порядков – с числом коэффициентов от десяток, до нескольких сотен.
Может показаться, что ядра процессора SEAforth40 не смогут поддерживать вычисления такого рода фильтров ввиду небольшого объема памяти. Но в данном случае первое впечатление обманчиво. В большинстве случаев экономить объем ОЗУ позволяет использование функций, прошитых в ПЗУ ядер. Это не только простые арифметические операции, но и целые процедуры, наподобие аппроксимации полиномами или табличной интерполяции – в этом случае расход памяти идет только на хранение ключевых точек. Аналогичная функция разработана и для поддержки цифровой фильтрации [18].
Слово taps позволяет внутри определений задавать таблицу коэффициентов фильтра и его начальные значения [5]. Например, КИХ фильтр на одном ядре:
: fir-kernel 4 # taps: a0 , 0 , a1 , 0 , a2 , 0 , a3 , 0 , a4 , 0 , : fir ( B:in __ out ) dup dup xor @b fir-kernel drop ; КИХ фильтр, задействующий несколько ядер: : long_fir_start dup dup xor @b fir_kernel !b !b ; : long_fir_mid @b push @b pop fir_kernel !b !b ; : long_fir_end @b push @b pop fir_kernel drop ; БИХ фильтр Чебышева: : lp.15.2p 4 # taps: $4038 , 0 , $8070 , 0 , $4038 , here 0 , $19D39 , 0 , $361E7 , 0 , ( here ) , : iir ( n _ n') push dup dup xor pop lp.15.2p drop dup !a ;
Если ядро будет использовано приложением только для вычисления фильтра, то для хранения отсчетов сигнала и коэффициентов фильтра можно отвести порядка 50-58 слов ОЗУ. При этом для программной части останется от 6 до 14 слов, что с учетом высокой плотности бинарного кода даст 24 – 56 команд языка.
Таким образом, в одном ядре может храниться и обрабатываться от 25 до 29 отсчетов входного сигнала и столько же коэффициентов. Если использовать все ядра для вычисления фильтра, получим значение 1000 -1150 коэффициентов. В реальной ситуации, конечно показатели могут быть меньше из-за возникающей потере точности – обработка данных ведется в целочисленном формате с 18-битной точностью. Как правило, удовлетворительные показатели достигаются при фильтрах порядка нескольких десятков.
В некоторых случаях для вычисления не изменяющихся в процессе выполнения программы значений функций можно использовать ресурсы компилятора, предварительно вычисляя нужные значения.
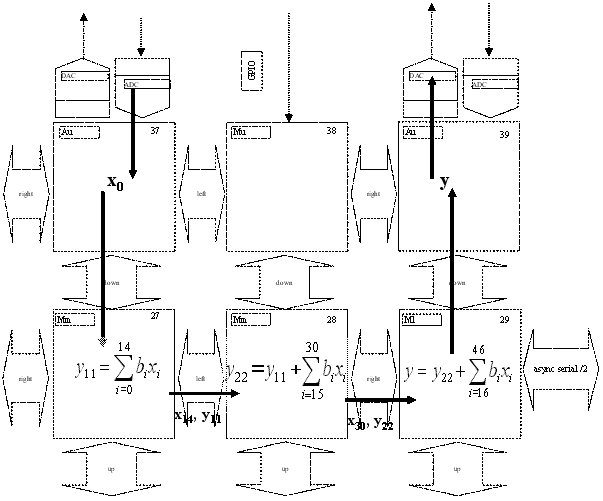
Для примера возьмем КИХ-фильтр нижних частот с 46 коэффициентами. В реализации фильтра задействуем три ядра процессора – первые два ядра вычисляют по 15 произведений коэффициентов с отсчетами входного сигнала, третье остальные 16. Для проверки на отладочной плате используется еще пара ядер – первое используется, как источник сигнала (сигнал формируется программно или формируются отсчеты АЦП), второе выдает сигнал на ЦАП.
Структурная схема вычислений с привязкой к ярдам процессора выглядит следующим образом – рис.4.7.
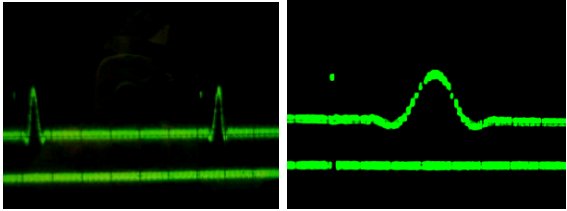
На рисунке 4.20 представлены осциллограммы реакции фильтра на одиночный импульс. Входной сигнал обрабатывается со скоростью, не превышающей скорости вычисления наибольшей частичной суммы y11 или y22. В данном случае реализуется конвеейрный вариант параллельных вычислений – ядро 27 выдав промежуточную сумму фильтра способно принимать новый отсчет сигнала. Ядро 37 также может задавать меньшую скорость вычисления отсчетов в соответствии с требованиями приложения. Синхронизация обеспечивается за счет передачи между ядрами промежуточных сумм и отсчетов входного сигнала.
На рисунке 4.21 также хорошо заметно запаздывание выходного сигнала относительно входного, составляющее величину, равную произведению количества коэффициентов фильтра на время между двумя последовательными отсчетами.
Для фильтра в примере максимальная частота следования отсчетов входного сигнала составляет порядка 83 КГц. Максимальная загрузка оперативной памяти ядер 65% (занято 42 слова из 64). Потеря точности обработки сигнала при использовании 18-битной арифметики примерно 4-5% (из-за ошибки округления коэффициентов). Скорость работы фильтра можно повысить, уменьшив количество коэффициентов фильтра, рассчитываемых одним ядром, увеличив при этом количество задействованных ядер.
Исходный код ниже.
\ первый блок фильтра
38 {node 0 org
: fir-kernel 15 # taps a0 , 0 , a1 , 0 , a2 , 0 , a3 , 0 , a4 , 0 ,
a5 , 0 , a6 , 0 , a7 , 0 , a8 , 0 , a9 , 0 ,
a10 , 0 , a11 , 0 , a12 , 0 , a13 , 0 , a14 , 0 , a15 , 0 ,
: long-fir-start '--l- # b! dup dup xor @b fir-kernel '-d-- # b! !b !b ;
here =p
begin
long-fir-start
again
node}
\ середина фильтра
28 {node 0 org
: fir-kernel 15 # taps a16 , 0 , a17 , 0 , a18 , 0 , a19 , 0 , a20 , 0 ,
a21 , 0 , a22 , 0 , a23 , 0 , a24 , 0 , a25 , 0 ,
a26 , 0 , a27 , 0 , a28 , 0 , a29 , 0 , a30 , 0 , a31 , 0 ,
: long-fir-mid '-d-- # b! @b push @b pop fir-kernel 'r--- # b! !b !b ;
here =p
begin
long-fir-mid
again
node}
\ выходной блок фильтра
29 {node 0 org \ here =p
: fir-kernel 13 # taps a32 , 0 , a33 , 0 , a34 , 0 , a35 , 0 , a36 , 0 ,
a37 , 0 , a38 , 0 , a39 , 0 , a40 , 0 , a41 , 0 ,
a42 , 0 , a43 , 0 , a44 , 0 , a45 , 0 ,
: long-fir-end 'r--- # b! @b push @b pop fir-kernel drop ;
here =p
begin
long-fir-end '-d-- # b! !b
again
node}
\ выдача выходных отсчетов на ЦАП
39 {node 0 org here =p
begin
'-d-- # b! @b $100 # . + $155 # xor 'iocs # a! !a
again
node}Вычисление преобразования Фурье через преобразование Хартли
Введение
Рассмотрим задачу вычисления дискретного преобразования Фурье [18, 19] на процессоре SEAforth40. Ограничимся вычислениями в формате фиксированной точкой - т.е. только целочисленные операции. Для вычисления преобразования Фурье требуется введение комплексной арифметики. В данном случае ограничимся только действительными числами при помощи дополнительного преобразования - преобразования Хартли, которое является чисто действительным. Имея вычисленные отсчеты преобразованиям Хартли можно получить как действительные и мнимые коэффициенты Фурье преобразования, так и спектр мощности и фазовый спектр.
Дискретное преобразование Хартли вычисляется следующим образом:
H(v)=1/N*(Summ((t=0;N-1) f(t)*cas(2*pi*t*v/N)));
Одним из замечательных свойств этого преобразования является то, что обратное преобразование вычисляется по аналогичной формуле, за исключением масштабирующего коэффициента 1/N.
С преобразованием Фурье оно связано следующим образом.
гармоники спектра мощности:
Фр(v)=(H(v)^2+H(N-v)^2)/2;
фазовый спектр:
Фф(v)=arctg((H(v)-H(N-v))/(H(v)+H(N-v))).
Таким образом, задача вычисления преобразования Фурье разбивается на два больших этапа - вычисление преобразование Хартли и уже на его основе преобразования Фурье.
Трудоемкость задачи может быть оценена в N^2 операций сложения и умножения на вычисление H(v), плюс 3N умножений и сложений на получение отсчетов преобразования Фурье. Прямое вычисление Фурье преобразования даст порядка (2N)^2 операций сложения и умножения. Для быстрого преобразования Фурье имеем 2NlogN умножений и 3NlogN сложений. Быстрое Преобразование Хартли имеет порядка 3/2NlogN сложений и NlogN умножений.
Учитывая скромные ресурсы процессора по встроенной оперативной памяти, ограничимся преобразованиями с небольшим числом N. Для ускорения вычислений ДПХ распределим вычисления коэффициентов преобразования на различные ядра процессора - пусть каждое ядро вычисляет один или несколько коэффициентов преобразования.
Рассмотрим случай N=16. Для него возможен вариант, при котором одно ядро процессора вычисляет один коэффициент (аналогичная ситуация возможна и при количестве отсчетов сигнала порядка 32-х). Т.о количество операций выполняемых ядром можно оценить как N+3 операций сложения и умножения. Вычисления тригонометрических функций целесообразно выполнить табличным методом - каждое ядро будет иметь свой фиксированный набор значений функции cas() и arctg().
Для удобства в вычислениях будут задействованы центральные 16 ядер. Предполагается, что отсчеты сигнала поступают в процессор посредством одного из периферийных ядер. В рассмотренном ниже примере источником сигнала является ядро №10 (можно предполагать, что оно получает сигнал с внешнего АЦП), ядро №20 принимает сигнал после подачи его на преобразователь и может передать его на дальнейшую обработку другим ядрам. Ядро, вычисляющее коэффициент преобразования ждет отсчет входного сигнала, копирует его себе, передает следующему ядру, вычисляет произведение с накоплением. Результаты преобразования остаются в ядрах.
В итоге имеем следующую диаграмму потоков данных при вычислении преобразования Хартли.
[20]<-f(t)-[21]<-f(t)-..<-[28]
^
|
f(t)
|
[10]-f(t)->[11]-f(t)->..->[18]11е ядро вычисляет H(0), 12е - H(1), ... 28e H(8) и т.д.
На втором этапе - вычислении Фурье спектра диаграмма потоков данных для рассматриваемого N выглядит следующим образом.
[20] [21] [28]
| |
H(15) H(8)
H(0) H(7)
| |
[10] [11] [18]Где "|" соответствует взаимному обмену коэффициентами. В силу симметрии ДПФ относительно N/2 для вычисления спектра мощности достаточно произвести вычисление только на половине ядер.
Алгоритмы работы ядер
Алгоритм работы ядер, вычисляющих коэффициенты преобразований, практически одинаков, и может быть представлен в виде последовательности нескольких шагов.
- начальная инициализация, промежуточная сумма s=0 ;
- цикл от 0 до 15 из следующих ниже шагов;
- прием входного отсчета сигнала - f(t) ;
- копирование сигнала себе;
- передача отсчета сигнала соседнему ядру;
- выборка из таблицы значения cas(vt) ;
- вычисление произведения p=p*cas(vt) ;
- вычисление промежуточной суммы s=s+p ;
- если отсчет не 16й, возврат на начало цикла - п.3.
- H(v)=s ;
- прием H(N-v) ;
- вычисление Фр(v)=(H(v)^2+H(N-v)^2)/2 ;
Ниже приводится один из вариантов реализации описанного алгоритма.
hart2.vf реализует этапы с 1 по 10й.
fourier2.fv этапы 11, 12.