Инспектор
Вы можете этот курс.
Опубликован: 12.07.2010 | Уровень: специалист | Доступ: платный | ВУЗ: Алтайский государственный университет
Лекция 4:
Многоядерные процессоры с низким энергопотреблением
Первые шаги программирования мультикомпьютеров SEAFORTH40
Введение
Подход к программированию мультикомпьютеров SEAforth во многом существенно отличается от программирования многоядерных процессоров общего назначения. Это выражается в специфике среды разработки, структуре процессора (массовый параллелизм, распределенная память), сокращенный набор команд, небольшой объем памяти для оперативного хранения программ и данных.
Простая арифметика
В данном разделе рассмотрим простые примеры, иллюстрирующие работу с константами, переменными и математическими операциями:
- сложение/вычитание переменной с константой;
- различные варианты умножения – сокращенный, подпрограмма, вызов слов ПЗУ.
Задача первая – написать программу, для двух соседних ядер, одно из которых складывает два числа, другое вычитает, после чего они обмениваются результатами операций.
Для начала, каждое из ядер должно настроить один из индексных регистров на порт соседнего ядра, положить на стек два числа, произвести назначенную операцию, записать результат в коммуникационный порт и получить данные от соседа (рисунки 4.14).
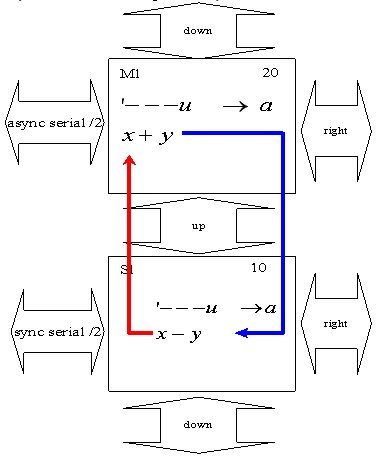
Возможный источник взаимной блокировки ядер – момент передачи данных. Для исключения блокировки, одно из ядер должно начать процедуру обмена с чтения порта, другое с записи. Графически процесс взаимодействия ядер достаточно удобно изображать в виде диаграммы последовательностей действий [17] (рисунки 4.15).

Т.к. в системе команд процессора отсутствует команда вычитания, ее придется реализовать, как сложение с числом в дополнительном коде.
\ макросы, определяющие операции сложения и вычитания чисел на стеке
macro: add
. + \ сложение
macro;
macro: sub \ вычитание
not 1 # . + \ перевод числа на стеке в доп. код
add
macro;
\ macro;
\ зададим пару констант
10 constant x
5 constant y
\ пусть ядро 10 выполняет сложение, ядро 20 - вычитание
\ т.к. сложение завершится быстрее, 10е ядро первым выполнит чтение с порта
\ дополнительно это позволит на некоторое время снизить энергопотребление процессора :
10 {node 0 org here =p '---u # a! \
x # y # add \ x+y
@a \ x+y x-y
over !a \ x+y x-y
.
node}
20 {node 0 org here =p '---u # a! \
x # y # sub \ x-y
!a @a \ x+y
.
node}При необходимости (например, многократное использование в коде программы), вычитание можно оформить в виде слова.
: - not 1 # . + . + ;
Следующий интересный момент связан с выполнением операции умножения на данном процессоре. Аппаратного умножителя в процессорных ядрах нет, и умножение реализуется программно на базе команды +*.
+ * используется в качестве строительных блоков для перемножения двух чисел, находящихся в регистрах S и A. Работает по принципу вычисления частичных произведений (сложение-сдвиг) [18]. Результат размещается в регистрах Т и А, которые работают при этом как 36-битный сдвиговый регистр. В Т (вершина стека) – старшая часть, в А – младшая.
Если бит 0 (LSB) в А равен 0, то 37-бит (бит расширения знака) регистра Т.А просто сдвигается вправо на один бит. Если он равен 1, содержимое S прибавляется к Т, перед тем, как 37-битный регистр Т.А будет сдвинут. Младший бит Т сдвигается в старший бит регистра А.
Код для ядра 30 иллюстрирует беззнаковое перемножение 18-битных чисел. В А помещается один множитель, вершина стека обнуляется, второй элемент стека содержит второй множитель.
30 {node 0 org here =p \ "ручная" реализация беззнакового умножения
'--l- # b!
\ t=0 s=x-любого знака a=y-положительный
155 # a! -2200 # \ t=4 a=5
dup dup \ -- 4 s=4 t=4 a=5
xor \ -- s=4 t=0 a=5
17 # for . +* unext \ -- s=x t=x*y_h a=x*y_l
@b
node}В том случае, если оба или один из сомножителей имеет небольшую размерность, можно использовать следующий прием – в регистр А помещается число с наименьшим количеством разрядов, число на вершине стека сдвигается вправо на это же число разрядов и выполнить команду +* столько раз, сколько значащих разрядов в регистре А.
Пример ниже демонстрирует умножение 25 на 3.
00 {node 0 org here =p \ умножение малоразрядных чисел
'--l- # b!
25 # 2* 2* 3 # dup a! . +* . +*
@b
node}Для экономии пространства ОЗУ можно использовать вызов слова * из ПЗУ ядер (есть практически во всех ядрах). Кроме всего прочего, это слово поддерживает знаковое умножение.
01 {node 0 org here =p \ работа подпрограммы умножения
'---u # b!
155 # -2200 # * 2/
@b
node}
02 {node 0 org here =p \ работа подпрограммы умножения
'---u # b!
155 # 2200 # * 2/
@b
node}Обмен данных между ядрами
Рассмотренная ниже задача носит учебный характер и врятли будет иметь смысл вне рамок запуска ее на симуляторе. Состоит она в следующем – надо организовать передачу слова между всеми ядрами процессора по цепочке – чем-то напоминает старую игру "Питон" - только роль клеток будут исполнять ядра процессоров.
Для начала зададим путь обхода процессора – рисунок 4.16.
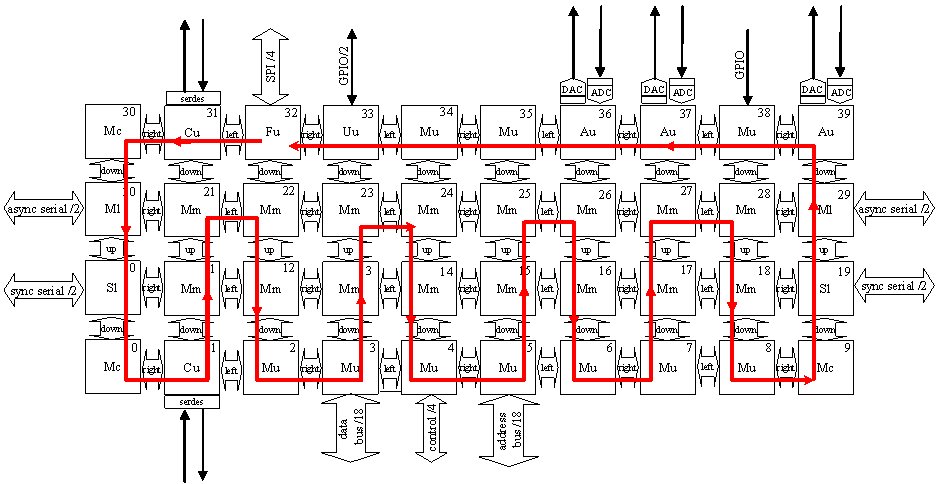
Алгоритм работы каждого из ядер предельно прост – считать слово данных от соседнего ядра, согласно месту в схеме обхода и передать следующему по обходу ядру. Исключение составит первое ядро в цепочке – оно только инициирует передачу слова.
Программный код ядер будет одинаковым - различаются только адреса портов. Снизить объем работы по написанию исходного текста можно, используя макроопределения (они же макросы).
Одно из возможных решений приводится ниже.
Макрос, реализующий описанный выше алгоритм будет иметь следующий вид:
macro: pipel, ( $in $out -- ) : start here =p # b! # a! @a dup !b macro;
Он задает точку старта процессорного ядра, берет со стека компиляции пару чисел – адресов портов источника и приемника слова и компилирует код, отвечающий за прием-передачу слова.
Согласно структурной схеме процессора выделим те пары портов, между которыми происходят передачи – источник-приемник. Для каждой из пар определим макрос с нужными для данной пары адресами портов:
macro: lr, ( $in $out ) '--l- 'r--- pipel, macro; macro: rd, ( $in $out ) 'r--- '-d-- pipel, macro; macro: du, ( $in $out ) '-d-- '---u pipel, macro; macro: ud, ( $in $out ) '---u '-d-- pipel, macro; macro: ul, ( $in $out ) '---u '--l- pipel, macro; macro: dr, ( $in $out ) '-d-- 'r--- pipel, macro; macro: rl, ( $in $out ) 'r--- '--l- pipel, macro; macro: lu, ( $in $out ) '--l- '---u pipel, macro;
Как видно из исходного кода, компилятором допускается использование вложенных макросов. Последним шагом зададим код для каждого из ядер.
\ начальное ядро
32 {node 0 org here =p '--l- # b! 0 # !b 'r--- # a! @a node}
\ ядра с направлением передачи от левого порта правому
31 {node lr, node} 35 {node lr, node} 37 {node lr, node} 33 {node lr, node}
\ от правого - нижнему
30 {node rd, node} 1 {node rd, node} 3 {node rd, node} 5 {node rd, node}
7 {node rd, node} 9 {node rd, node}
\ от нижнего - верхнему
20 {node du, node} 11 {node du, node} 13 {node du, node} 15 {node du, node}
17 {node du, node} 19 {node du, node}
\ от верхнего - нижнему
10 {node ud, node} 12 {node ud, node} 14 {node ud, node} 16 {node ud, node}
18 {node ud, node} 29 {node ud, node}
\ от верхнего - левому
21 {node ul, node} 23 {node ul, node} 25 {node ul, node} 27 {node ul, node}
\ от нижнего - правому
0 {node dr, node} 2 {node dr, node} 4 {node dr, node} 6 {node dr, node}
8 {node dr, node} 39 {node dr, node}
\ от правого - левому
34 {node rl, node} 36 {node rl, node} 38 {node rl, node}
\ от левого - верхнему
22 {node lu, node} 24 {node lu, node} 26 {node lu, node} 28 {node lu, node}Запуская на симуляторе, можно видеть примерно следующее – область с активными ядрами перемещается согласно заданному нами пути (рисунок 4.17).
Работа с периферийными устройствами
АЦП
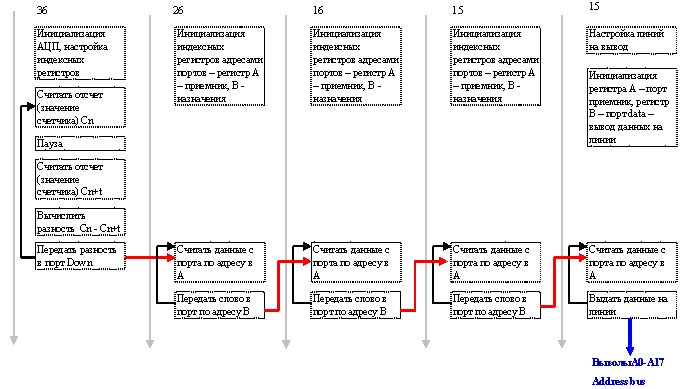
Запустим АЦП на ядре 36 и данные, генерируемые на нем будем выдавать в параллельном виде на линиях ядра №5. В этом случае в работе приложения будут задействованы несколько ядер (а именно – 36, 26, 16, 15 и 5-е), выполняющих каждое свою задачу. Ядро 36 считывает данные с АЦП, ядра 26, 16, 15 служат для передачи значений АЦП 5-му ядру, и ядро 5 по мере поступления данных выставляет их в параллельный порт. Путь данных показан на рисунке 4.18.

Диаграмма последовательностей выглядит следующим образом – рисунке 4.19.