|
Здравствуйте. А уточните, пожалуйста, по какой причине стоимость изменилась? Была стоимость в 1 рубль, стала в 9900 рублей. |
Спонсор: Microsoft
Вы можете этот курс.
Опубликован: 25.05.2011 | Доступ: свободный | Студентов: 6110 / 2301 | Оценка: 4.19 / 3.94 | Длительность: 12:28:00
Тема: Сетевые технологии
Специальности: Программист, Архитектор программного обеспечения
Лекция 8:
Azure Services Platform. Часть 2
Те же URL могут использоваться для возвращения объектов blob. Одна операция PUT может обеспечить размещение в хранилище объектов blob размером до 64МБ. Для сохранения объектов blob размером больше 64МБ и вплоть до 50 ГБ необходимо сначала разместить все блоки посредством соответствующего количества операций PUT и затем, с помощью все той же операции PUT, передать список блоков, чтобы обеспечить пригодную для чтения версию blob. В примере, который иллюстрирует рис. 2, только после размещения всех блоков и подтверждения их принадлежности blob посредством списка блоков blob может быть считан с использованием следующего URL:
http://sally.blob.core.windows.net/pictures/MOV1.AVI
Операции GET всегда выполняются на уровне blob и не предполагают использования блоков.
Рассмотрим абстракции данных блоков. Каждый блок идентифицирует ID блока размером до 64 байт. Область действия ID блока ограничена именем blob, поэтому разные объекты blob могут иметь блоки с одинаковыми ID. Блоки неизменны. Каждый блок может быть размером до 4МБ, и один blob может включать блоки разного размера. Windows Azure Blob обеспечивает следующие операции уровня блока:
- PUT block – загрузить блок blob. Обратите внимание, что успешно загруженный посредством операции PUT block блок не является частью blob до тех пор, пока это не будет подтверждено списком блоков, загружаемым операцией PUT blocklist.
- PUT blocklist – подтвердить blob через предоставление списка ID блоков, его составляющих. Указанные в этой операции блоки должны быть уже успешно загружены через вызовы PUT. Порядок блоков в операции PUT blocklist обеспечит пригодную для чтения версию blob.
- GET blocklist – извлечь список блоков, переданный ранее для blob операцией PUT blocklist. В возвращаемом списке блоков указываются ID и размер каждого блока.
Во всех рассматриваемых далее примерах используется blob "MOV1.avi", располагающийся в контейнере "movies" (ролики) под учетной записью "sally".
Ниже представлен пример REST-запроса для размещения блока размером 4МБ посредством операции PUT block. Обратите внимание, что используется HTTP-команда PUT. "?comp=block" указывает на то, что это операция PUT block. Затем задается BlockID. Параметр Content-MD5 может быть задан для защиты от ошибок передачи по сети и обеспечения целостности. В данном случае, Content-MD5 – это контрольная сумма MD5 данных блока в запросе. Контрольная сумма проверяется на сервере, в случае несовпадения возвращается ошибка. Параметр Content-Length (Длина содержимого) определяет размер содержимого блока. Также в заголовке HTTP-запроса имеется заголовок авторизации, как показано ниже.
PUT http://sally.blob.core.windows.net/movies/MOV1.avi ?comp=block &blockid=BlockId1 &timeout=60 HTTP/1.1 Content-Length: 4194304 Content-MD5: HUXZLQLMuI/KZ5KDcJPcOA== Authorization: SharedKey sally: F5a+dUDvef+PfMb4T8Rc2jHcwfK58KecSZY+l2naIao= x-ms-date: Mon, 27 Oct 2008 17:00:25 GMT ……… Block Data Contents ………
Ниже представлен пример REST-запроса для операции PUT blocklist. Обратите внимание, что используется HTTP-команда PUT. "?comp=blocklist" указывает на то, что это операция PUT blocklist. Список блоков задается в теле HTTP-запроса в формате XML, как показано в примере ниже. Обратите внимание, что значение поля Content-Length в заголовке запроса соответствует размеру тела запроса, а не размеру создаваемого blob. Также в заголовке HTTP-запроса имеется заголовок авторизации, как показано ниже.
PUT http://sally.blob.core.windows.net/movies/MOV1.avi ?comp=blocklist &timeout=120 HTTP/1.1 Content-Length: 161213 Authorization: SharedKey sally: QrmowAF72IsFEs0GaNCtRU143JpkflIgRTcOdKZaYxw= x-ms-date: Mon, 27 Oct 2008 17:00:25 GMT <?xml version="1.0" encoding="utf-8"?> <BlockList> <Block>BlockId1</Block> <Block>BlockId2</Block> ……………… </BlockList>
Ниже представлен пример REST-запроса для операции GET blob. В данном случае используется HTTP-команда GET. Этот запрос обеспечит извлечение всего содержимого заданного blob. Если для контейнера, которому принадлежит blob (в данном примере "movies"), задана политика совместного использования "Private", для получения blob необходимо пройти аутентификацию. Если задана политика совместного использования "Public-Read", аутентификация не требуется, и заголовок аутентификации в заголовке запроса не нужен.
GET http://sally.blob.core.windows.net/movies/MOV1.avi
HTTP/1.1
Authorization: SharedKey sally: RGllHMtzKMi4y/nedSk5Vn74IU6/fRMwiPsL+uYSDjY=
X-ms-date: Mon, 27 Oct 2008 17:00:25 GMT
Как показано в примере ниже, также поддерживается операция GET для извлечения
диапазона байт заданного blob.
GET http://sally.blob.core.windows.net/movies/MOV1.avi
HTTP/1.1
Range: bytes=1024000-2048000Загрузка blob в виде списка блоков обладает следующими преимуществами:
- Возможность продолжения – для каждого блока в отдельности можно проверить успешность загрузки, в случае сбоя повторить попытку загрузки и продолжить выполнение с этого момента.
- Параллельная загрузка – загрузка блоков может выполняться параллельно, что обеспечивает сокращение времени загрузки очень больших объектов blob.
- Загрузка не по порядку – Блоки могут загружаться в произвольном порядке. Значение имеет лишь порядок блоков в списке операции PUT blocklist. Список блоков в операции PUT blocklist определяет пригодную для чтения версию blob.
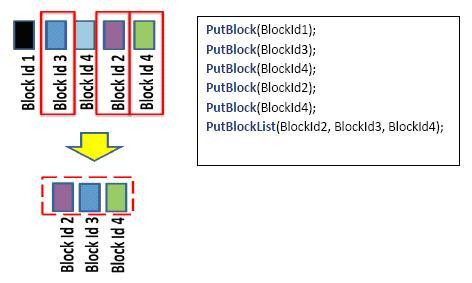
- Используя представленный на рисунке 7.3 пример, опишем различные сценарии, возможные при использовании блоков для загрузки объектов blob:
- Загрузка блоков с одинаковыми ID блока – когда для одного blob загружаются блоки с одинаковыми ID блока, при формировании окончательно версии blob в операции PUT blocklist из всех блоков с одинаковым ID будет использоваться только загруженный самым последним. В примере выше загружаются два блока с BlockId4, и только второй из них будет использоваться в окончательном списке блоков blob.
- Загрузка блоков в произвольном порядке – блоки могут загружаться в порядке, отличном от указанного в окончательном списке блоков blob. В примере выше в окончательном списке блоки располагаются в порядке BlockId2, BlockId3 и BlockId4, но загружались они в другой последовательности. Упорядочивание данных blob (через операцию GET) в пригодную для чтения версию выполняется соответственно списку, указанному в операции PUT blocklist.
- Неиспользуемые блоки – более того, некоторые блоки могут никогда не войти в окончательный список блоков blob. Эти блоки будут удалены системой в процессе сборки мусора. В рассматриваемом примере такими блоками являются BlockId1 и первый блок с ID BlockId4. Точнее говоря, как только blob создан посредством операции PUT blocklist, все загруженные, но не вошедшие в список блоков операции PUT blocklist блоки будут удалены путем сборки мусора.
Загрузка большого blob может занимать довольно длительное время. При этом загруженные, но не использованные блоки занимают место в хранилище. Многие загруженные блоки могут никогда не войти в список PUT blocklist. В случае отсутствия активности для данного blob в течение длительного периода времени (в настоящее время этот период составляет неделю), эти неиспользованные блоки будут удалены системой в процессе сборки мусора.
Любопытным является сценарий параллельной загрузки блоков для одного blob. В этом случае заслуживают внимания два вопроса:
- ID блоков – если для загрузки блоков в один blob приложение использует множество клиентских модулей записи, во избежание конфликтов ID блоков должны быть уникальными среди всех этих модулей записи, или они должны представлять содержимое записываемого блока (таким образом, если один и тот же блок записывается несколькими клиентами, ID блока во всех клиентах будет одинаковым, поскольку он представляет одни и те же данные). Во избежание ошибок при потенциальной возможности записи одного Blob несколькими модулями записи в качестве ID блока рекомендуется использовать хеш (например, MD5-хеш) содержимого блока. Таким образом, ID блока будет представлять его содержимое.
- Приоритет имеет первая фиксация – в ситуации, когда множество клиентов выполняют загрузку блоков для одного blob параллельно, приоритет имеет первая фиксация blob посредством операции PUT blocklist (или модуль записи, вызвавший PUT blob первым). Все остальные неиспользованные блоки, загруженные другими модулями записи для blob с этим именем, будут удалены в процессе сборки мусора. Следовательно, для эффективного параллельного обновления blob необходима координация всех клиентов, ведущих запись параллельно.