
|
Не могу найти требования по оформлению выпускной контрольной работы по курсу профессиональной переподготовки "Менеджмент предприятия" |
Опубликован: 11.08.2009 | Доступ: свободный | Студентов: 5684 / 1177 | Оценка: 4.45 / 4.23 | Длительность: 28:40:00
Темы: Экономика, Менеджмент
Специальности: Руководитель
Лекция 9:
Описание неопределенностей в теории принятия решений
Прослеживается интересное явление: чем выше планка богатства для человека, тем к более низкой категории относительно этой планки он себя относит.
Для сводки данных естественно использовать гистограммы. Для этого необходимо сгруппировать ответы. Использовались 7 классов (интервалов):
1 - до 5 миллионов рублей в месяц на человека (включительно);
2 - от 5 до 10 миллионов;
3- от 10 до 15 миллионов;
4 - от 15 до 20 миллионов;
5 - от 20 до 25 миллионов;
6 - от 25 до 30 миллионов;
7 - более 30 миллионов.
(Во всех интервалах левая граница исключена, а правая, наоборот - включена.)
Сводная информация представлена на рис. 9.1 (для научных работников и преподавателей) и рис. 9.2 (для всех остальных, т.е. для лиц, не занятых в сфере науки и образования - служащих иных бюджетных организаций, коммерческих структур, рабочих, пенсионеров).
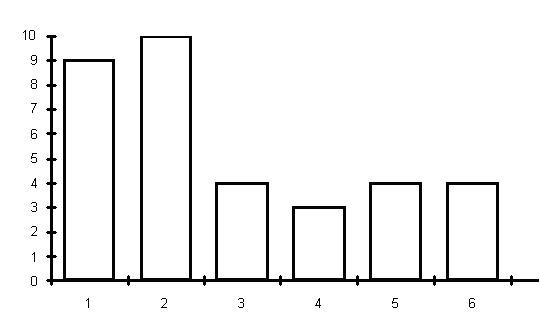
Рис. 9.2. Гистограмма ответов на вопрос 1 для лиц, не занятых в сфере науки и образования (34 человека).
Для двух выделенных групп, а также для некоторых подгрупп второй группы рассчитаны сводные средние характеристики - выборочные средние арифметические, медианы, моды. При этом медиана группы - количество млн. руб., названное центральным по порядковому номеру опрашиваемым в возрастающем ряду ответов на вопрос 1, а мода группы - интервал, на котором столбик гистограммы - самый высокий, т.е. в него "попало" максимальное количество опрашиваемых. Результаты приведены в табл. 9.4.
| Группа опрошенных | Среднее арифметическое | медиана | мода |
|---|---|---|---|
| Научные работники и преподаватели | 11,66 | 7,25 | (5; 10) |
| Лица, не занятые в сфере науки и образования | 14,4 | 10 | (5; 10) |
| Служащие коммерческих структур и бюджетных организаций | 17,91 | 10 | (5; 10) |
| Рабочие | 15 | 13 | - |
| Пенсионеры | 10,3 | 10 |
Построим нечеткое множество, описывающее понятие "богатый человек" в соответствии с представлениями опрошенных. Для этого составим табл. 9.5 на основе рис. 9.1 и рис. 9.2 с учетом размаха ответов на первый вопрос.
| № | Номер интервала | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Интервал, млн. руб. в месяц | (0;1) | [1;5] | (5;10] | (10;15] | (15;20] | (20;25] | (25;30] | (30;100) | [100;+?) |
| 2 | Число ответов в интервале | 0 | 19 | 21 | 13 | 5 | 6 | 7 | 2 | 1 |
| 3 | Доля ответов в интервале | 0 | 0,257 | 0,284 | 0,176 | 0.068 | 0,081 | 0,095 | 0,027 | 0,013 |
| 4 | Накопленное число ответов | 0 | 19 | 40 | 53 | 58 | 64 | 71 | 73 | 74 |
| 5 | Накопленная доля ответов | 0 | 0,257 | 0,541 | 0,716 | 0,784 | 0,865 | 0,960 | 0,987 | 1,000 |
Пятая строка табл. 9.5 задает функцию принадлежности нечеткого множества, выражающего понятие "богатый человек" в терминах его ежемесячного дохода. Это нечеткое множество является подмножеством множества из 9 интервалов, заданных в строке 2 табл. 9.5. Или множества из 9 условных номеров 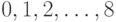 . Эмпирическая функция распределения, построенная по выборке из ответов 74 опрошенных на первый вопрос мини-анкеты, описывает понятие "богатый человек" как нечеткое подмножество положительной полуоси.
. Эмпирическая функция распределения, построенная по выборке из ответов 74 опрошенных на первый вопрос мини-анкеты, описывает понятие "богатый человек" как нечеткое подмножество положительной полуоси.
О разработке методики ценообразования на основе теории нечетких множеств. Для оценки значений показателей, не имеющих количественной оценки, можно использовать методы нечетких множеств. Например, в работе П.В. Битюкова нечеткие множества применялись при моделировании задач ценообразования на электронные обучающие курсы, используемые при дистанционном обучении. Им было проведено исследование значений фактора "Уровень качества курса" с использованием нечетких множеств. В ходе практического использования предложенной П.В. Битюковым методики ценообразования значения ряда других факторов могут также определяться с использованием теории нечетких множеств. Например, ее можно использовать для определения прогноза рейтинга специальности в вузе с помощью экспертов, а также значений других факторов, относящихся к группе "Особенности курса". Опишем подход П.В. Битюкова как пример практического использования теории нечетких множеств.
Значение оценки, присваиваемой каждому интервалу для фактора "Уровень качества курса", определяется на универсальной шкале [0,1], где необходимо разместить значения лингвистической переменной "Уровень качества курса": НИЗКИЙ, СРЕДНИЙ, ВЫСОКИЙ. Степень принадлежности некоторого значения вычисляется как отношение числа ответов, в которых оно встречалось в определенном интервале шкалы, к максимальному (для этого значения) числу ответов по всем интервалам.
Был проведен опрос экспертов о степени влияния уровня качества электронных курсов на их потребительную ценность. Каждому эксперту в процессе опроса предлагалось оценить с позиции потребителя ценность того или иного класса курсов в зависимости от уровня качества. Эксперты давали свою оценку для каждого класса курсов по 10-ти балльной шкале (где 1 - min, 10 - max). Для перехода к универсальной шкале [0,1], все значения 10-ти балльной шкалы оценки ценности были разделены на максимальную оценку 10.
Используя свойства функции принадлежности, необходимо предварительно обработать данные с тем, чтобы уменьшить искажения, вносимые опросом. Естественными свойствами функций принадлежности являются наличие одного максимума и гладкие, затухающие до нуля фронты. Для обработки статистических данных можно воспользоваться так называемой матрицей подсказок. Предварительно удаляются явно ошибочные элементы. Критерием удаления служит наличие нескольких нулей в строке вокруг этого элемента.
Элементы матрицы подсказок вычисляются по формуле:
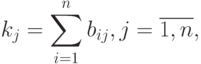
где 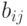 - элемент таблицы с результатами анкетирования, сгруппированными по интервалам. Матрица подсказок представляет собой строку, в которой выбирается максимальный элемент:
- элемент таблицы с результатами анкетирования, сгруппированными по интервалам. Матрица подсказок представляет собой строку, в которой выбирается максимальный элемент: 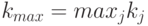 , и далее все ее элементы преобразуются по формуле:
, и далее все ее элементы преобразуются по формуле:
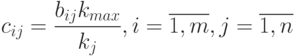
Для столбцов, где 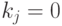 , применяется линейная аппроксимация:
, применяется линейная аппроксимация:
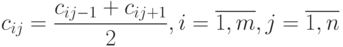
Результаты расчетов сводятся в таблицу, на основании которой строятся функции принадлежности. Для этого находятся максимальные элементы по строкам: 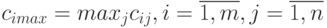 . Функция принадлежности вычисляется по формуле:
. Функция принадлежности вычисляется по формуле:  . Результаты расчетов приведены в табл. 9.6.
. Результаты расчетов приведены в табл. 9.6.
| Интервал на универсальной шкале | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
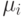 |
0 | 1,2 | 1 | 1 | 0.89 | 0 | 0 | 0 | 0 | |
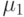 |
0 | 0 | 0 | 0 | 0 | 0,33 | 1 | 1 | 1 | 0 |
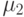 |
0 | 0 | 0 | 0 | 0 | 0,33 | 1 | 1 | 0 | 0 |
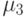 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
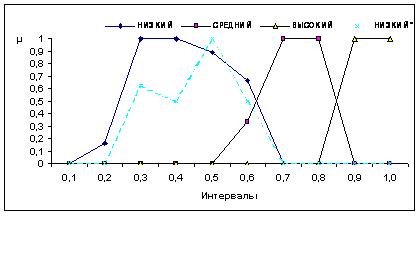
Рис. 9.3. График функций принадлежности значений лингвистической переменной "Уровень качества курса".
На рис. 9.3 сплошными линиями показаны функции принадлежности значений лингвистической переменной "Уровень качества курса" после обработки таблицы, содержащей результаты опроса. Как видно из графика, функции принадлежности удовлетворяют описанным выше свойствам. Для сравнения пунктирной линией показана функция принадлежности лингвистической переменной для значения НИЗКИЙ без обработки данных.
О статистике нечетких множеств. Нечеткие множества - частный вид объектов нечисловой природы. Статистические методы анализа объектов нечисловой природы описаны в. В частности, среднее значение нечеткого множества можно определить по формуле:
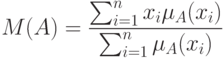
где  - функция принадлежности нечеткого множества
- функция принадлежности нечеткого множества 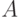 .
.
Как известно, методы статистики нечисловых данных базируются на использовании расстояний (или показателей различия) в соответствующих пространствах нечисловой природы. Расстояние между нечеткими подмножествами  и
и 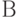 множества
множества 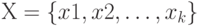 можно определить как
можно определить как
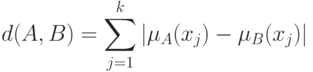
где 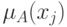 - функция принадлежности нечеткого множества , а
- функция принадлежности нечеткого множества , а  - функция принадлежности нечеткого множества
- функция принадлежности нечеткого множества 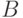 . Может использоваться и другое расстояние:
. Может использоваться и другое расстояние:
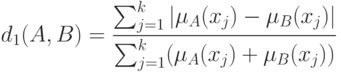
(Примем это расстояние равным 0, если функции принадлежности тождественно равны 0.)
В соответствии с аксиоматическим подходом к выбору расстояний (метрик) в пространствах нечисловой природы разработан обширный набор систем аксиом, из которых выводится тот или иной вид расстояний (метрик) в конкретных пространствах. При использовании вероятностных моделей расстояние между случайными нечеткими множествами само является случайной величиной, имеющей в ряде постановок асимптотически нормальное распределение.
В эконометрике разработан ряд методов статистического анализа нечетких данных, в том числе методы классификации, регрессии, проверки гипотез о совпадении функций принадлежности по опытным данным и т.д., при этом оказались полезными общие подходы статистики объектов нечисловой природы, основанные на использовании расстояний в выборочных пространствах.
Михаил Агапитов
Подобед Александр
|
Я нажал кнопку "начать курс" и почти его уже закончил, но для получения диплома на бумаге, нужно его же оплатить? Как оплатить? |