Тверской государственный университет
Опубликован: 06.10.2013 | Доступ: свободный | Студентов: 1457 / 341 | Длительность: 02:37:00
Тема: Образование
Специальности: Преподаватель
Лекция 2:
Тексты. Кодирование
Кодирование словами переменной длины
Кодировка символов алфавита T словами алфавита 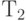 фиксированной длины k имеет то преимущество, что закодированный текст легко поддается расшифровке – декодированию. Действительно, достаточно закодированный текст разбить на группы длины
фиксированной длины k имеет то преимущество, что закодированный текст легко поддается расшифровке – декодированию. Действительно, достаточно закодированный текст разбить на группы длины 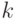 , и каждой группе поставить в соответствие символ алфавита. Недостатком такого способа является некоторая неэффективность процедуры кодирования, - каждому символу алфавита всегда соответствует битов алфавита . Память компьютера достаточно дешевая, поэтому жертвуют неэффективностью использования памяти ради удобства декодирования.
, и каждой группе поставить в соответствие символ алфавита. Недостатком такого способа является некоторая неэффективность процедуры кодирования, - каждому символу алфавита всегда соответствует битов алфавита . Память компьютера достаточно дешевая, поэтому жертвуют неэффективностью использования памяти ради удобства декодирования.
В других ситуациях эффективность важнее удобства декодирования. Примерами являются азбука Брайля, азбука Морзе. В азбуке Морзе, где для передачи информации используется алфавит из двух символов – точки и тире, для однозначного декодирования вводится третий символ – пауза. При передаче данных по телеграфу, использующему азбуку Морзе, точке, тире и паузе соответствуют сигналы разной длительности.
Рассмотрим пример неоднозначного кодирования. Пусть у нас есть алфавит из 3-х символов – А, М, П. Введем следующую кодировку: А – 0, М – 1, П – 10. Рассмотрим закодированный текст: 1010. Этому тексту соответствуют два слова – МАМА и ПП. Как видите, введенная кодировка не обеспечивает однозначное декодирование.
Можно ли при использования кодировки словами переменной длины наложить ограничения на способ кодирования, чтобы декодирование было однозначным? Ответ положителен. Если при кодировании выполняется условие Фано, то декодирование однозначно. Кодирование называется префиксным, если при кодировании существует пара символов, такая, что код одного символа является префиксом кода другого символа. В нашем примере кодирование является префиксным, поскольку для символов М и П код символа М является префиксом (началом) кода символа П. Условие Фано выполняется, если кодирование не является префиксным. Условие Фано является достаточным условием для однозначного декодирования. Оно не является необходимым условием.
Рассмотрим несколько задач, решение которых предполагает использование условия Фано.
Задача 13:
Для трехбуквенного алфавита {А, М, П} используется кодировка А – 01, М – 10, П – 001. Какой код минимальной длины следует задать для кодировки буквы Т, добавляемой в алфавит?
Ответ: Т – 11.
Решение: Используемая кодировка удовлетворяет условию Фано, - ни один код не является префиксом другого кода, что гарантирует однозначность декодирования. Для нового символа, добавляемого в алфавит, нельзя использовать код, состоящий из одного символа, поскольку будет нарушено условие Фано. Для кода, состоящего из двух символов, возможен только один вариант, удовлетворяющий условию Фано, - Т – 11.
Задача 14:
Для четырехбуквенного алфавита {А, М, П, Т} используется кодировка А – 01, М – 10, П – 001, Т - 11. Можно ли уменьшить длину кода одного из символов, сохраняя однозначность декодирования?
Ответ: Можно. П – 00.
Решение: Используемая кодировка удовлетворяет условию Фано, - ни один код не является префиксом другого кода, что гарантирует однозначность декодирования. Не нарушая условия Фано, для кодирования буквы П можно использовать код 00. Заметьте, в этом случае все символы кодируются словами постоянной длины. Для такой кодировки условие Фано выполняется автоматически, поскольку все слова различны и имеют одинаковую длину, так что ни одно из них не может быть префиксом другого слова.