Опубликован: 11.04.2007 | Доступ: свободный | Студентов: 6201 / 2423 | Оценка: 4.37 / 4.24 | Длительность: 11:19:00
Тема: Безопасность
Специальности: Специалист по безопасности
Лекция 10:
Групповые коды
Аннотация: Объясняется, какой блочный код называется групповым. Математическое обоснование выводов. Упражнения для самопроверки. Совершенные и квазисовершенные коды. Их свойства. Полиномиальные коды. Частный случай полиномиальных кодов – циклические коды. Очень хорошее и доходчивое объяснение материала характерно для данной лекции
Ключевые слова: матрица, отображение, операции, групповым, расстояние, вес, кодовое слово, вероятность, ПО, класс, Лидером, слово, множества, разбиение, таблица, таблицей декодирования, декодирование, кодирование, совершенным, максимум, квазисовершенным, оптимальным, кодом Хэмминга, код хэмминга, представление, бит, длина, информация, улучшение, полиномиальном кодировании, многочлен, поле, остаток, делителем
Множество всех двоичных слов 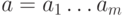 длины
длины 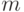 образует абелеву (коммутативную) группу относительно поразрядного сложения.
образует абелеву (коммутативную) группу относительно поразрядного сложения.
Пусть 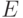 - кодирующая
- кодирующая  -матрица, у
которой есть
-матрица, у
которой есть 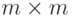 -подматрица с отличным от нуля определителем, например,
единичная. Тогда отображение
-подматрица с отличным от нуля определителем, например,
единичная. Тогда отображение 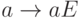 переводит группу
всех двоичных слов длины в группу кодовых слов длины
переводит группу
всех двоичных слов длины в группу кодовых слов длины  .
.
Предположим, что 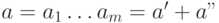 . Тогда для
. Тогда для 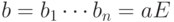 ,
,  ,
, 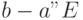 ,
получаем
,
получаем
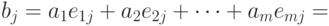

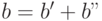 . Следовательно,
взаимно-однозначное отображение группы двоичных слов длины при помощи заданной
матрицы сохраняет свойства групповой операции, что означает, что кодовые слова
образуют группу.
. Следовательно,
взаимно-однозначное отображение группы двоичных слов длины при помощи заданной
матрицы сохраняет свойства групповой операции, что означает, что кодовые слова
образуют группу.Блочный код называется групповым, если его кодовые слова образуют группу.
Если код является групповым, то наименьшее расстояние между двумя кодовыми словами равно наименьшему весу ненулевого слова.
Это следует из соотношения  .
.
В предыдущем примере наименьший вес ненулевого слова равен 3. Следовательно, этот код способен исправлять однократную ошибку или обнаруживать однократную и двойную.
При использовании группового кода незамеченными остаются те и только те ошибки, которые отвечают строкам ошибок, в точности равным кодовым словам.
Такие строки ошибок переводят одно кодовое слово в другое.
Следовательно, вероятность того, что ошибка останется необнаруженной, равна сумме вероятностей всех строк ошибок, равных кодовым словам.
В рассмотренном примере вероятность ошибки равна  .
.
Рассмотрим задачу оптимизации декодирования группового кода с двоичной
матрицей кодирования . Требуется минимизировать вероятность
того, что 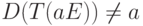 .
.
Схема декодирования состоит из группы 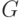 всех слов, которые
могут быть приняты (
всех слов, которые
могут быть приняты ( 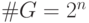 ). Так как кодовые слова
). Так как кодовые слова 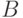 образуют
нормальную (нормальность следует из коммутативности ) подгруппу , то множеству можно придать структуру таблицы:
будем записывать в одну строку те элементы ,
которые являются членами одного смежного класса по . Первая строка,
соответствующая нулевому слову из , будет тогда всеми кодовыми
словами из , т.е.
образуют
нормальную (нормальность следует из коммутативности ) подгруппу , то множеству можно придать структуру таблицы:
будем записывать в одну строку те элементы ,
которые являются членами одного смежного класса по . Первая строка,
соответствующая нулевому слову из , будет тогда всеми кодовыми
словами из , т.е.  . В общем случае,
если
. В общем случае,
если 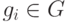 , то строка, содержащая
, то строка, содержащая  (смежный класс
(смежный класс 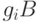 ) имеет вид
) имеет вид  .
.
Лидером каждого из таких построенных смежных классов называется слово минимального веса.
Каждый элемент 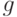 из однозначно представляется в
виде суммы
из однозначно представляется в
виде суммы 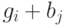 , где - лидер соответствующего
смежного класса и
, где - лидер соответствующего
смежного класса и  .
.
Множество классов смежности группы образуют фактор-группу,
которая есть фактор-множество множества по отношению
эквивалентности-принадлежности к одному смежному классу, а это означает, что
множества, составляющие это фактор-множество, образуют разбиение .
Отсюда следует, что строки построенной таблицы попарно либо не пересекаются, либо совпадают.
Если в рассматриваемой таблице в первом столбце записать лидеры, то полученная таблица называется таблицей декодирования. Она имеет вид:
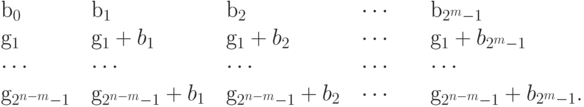
 следует из теоремы Лагранжа11, т.к. - это порядок фактор-группы
следует из теоремы Лагранжа11, т.к. - это порядок фактор-группы  ,
, 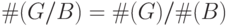 ,
,  .
.Декодирование слова 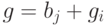 состоит в выборе кодового слова
состоит в выборе кодового слова 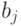 в качестве переданного и последующем применении операции, обратной умножению
на . Такая схема декодирования сможет исправлять ошибки.
в качестве переданного и последующем применении операции, обратной умножению
на . Такая схема декодирования сможет исправлять ошибки.
Для 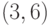 -кода из рассматриваемого примера таблица
декодирования будет следующей:
-кода из рассматриваемого примера таблица
декодирования будет следующей:

Первая строка в ней - это строка кодовых слов, а первый столбец - это лидеры.
Чтобы декодировать слово  , следует отыскать его в таблице
и выбрать в
качестве переданного слово в том же столбце и в первой строке.
, следует отыскать его в таблице
и выбрать в
качестве переданного слово в том же столбце и в первой строке.
Например, если принято слово 110011 (2-я строка, 3-й столбец таблицы), то считается, что было передано слово 010011; аналогично, если принято слово 100101 (3-я строка, 4-й столбец таблицы), переданным считается слово 110101, и т.д.
Групповое кодирование со схемой декодирования посредством лидеров исправляет все ошибки, строки которых совпадают с лидерами. Следовательно, вероятность правильного декодирования переданного по двоичному симметричному каналу кода равна сумме вероятностей всех лидеров, включая нулевой.
В рассмотренной схеме вероятность правильной передачи слова будет 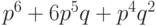 .
.
Кодовое слово любого столбца таблицы декодирования является ближайшим кодовым словом ко всем прочим словам данного столбца.
Пусть переданное слово 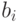 принято как
принято как  ,
, 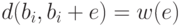 , т.е. это расстояние равно
весу соответствующего лидера. Расстояние от до любого
другого кодового слова равно весу их поразрядной суммы, т.е.
, т.е. это расстояние равно
весу соответствующего лидера. Расстояние от до любого
другого кодового слова равно весу их поразрядной суммы, т.е. 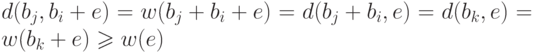 ,
т.к.
,
т.к.  - лидер смежного класса, к которому принадлежат как
- лидер смежного класса, к которому принадлежат как 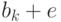 ,
так и .
,
так и .
Доказано, при схеме декодирования лидерами по полученному слову берется ближайшее к нему кодовое.
Упражнение 40 Для кодирующих матриц
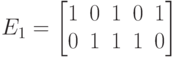
 :
:- Построить соответственно
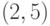 -код и
-код и 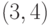 -код.
-код. - Найти основные характеристики полученных кодов: минимальное расстояние между словами кода; вероятность необнаружения ошибки; максимальную кратность ошибок, до которой включительно они все исправляются или обнаруживаются.
- Построить таблицы декодирования.
- Уточнить характеристики полученных кодов, при использовании их для исправления ошибок, т.е. найти вероятность правильной передачи и описать ошибки, исправляемые этими кодами.
- Во что будут декодированы слова: 10001, 01110, 10101, 1001, 0110, 1101?