
|
Здравствуйте прошла курсы на тему Алгоритмы С++. Но не пришел сертификат и не доступен.Где и как можно его скаачат? |
Опубликован: 05.01.2015 | Доступ: свободный | Студентов: 2189 / 0 | Длительность: 63:16:00
Специальности: Программист, Системный архитектор, Тестировщик, Архитектор программного обеспечения
Лекция 19:
Орграфы и DAG-графы
Сильные компоненты в орграфах
Неориентированные графы и DAG-графы — более простые структуры данных, чем орграфы общего вида, в силу структурной симметрии, которая характеризует отношения достижимости среди вершин: из того, что в неориентированном графе существует путь из s в t, следует, что существует путь из t в s; если в DAG-графе существует путь из s в t, то мы знаем, что путь из t в s не существует. В случае орграфов общего вида тот факт, что вершина t достижима из s, не несет никакой информации о достижимости s из t.
Чтобы понять структуру орграфов, мы рассмотрим сильную связность (strong connectivity), обладающую интересующей нас симметрией. Если s и t являются сильно связанными вершинами (каждая из них достижима из другой), то, по определению, таковыми являются и t и s. Как было сказано в разделе 19.1, из такой симметрии следует, что вершины орграфа разбиваются на классы сильных компонентов, состоящие из взаимно достижимых вершин. В этом разделе мы рассмотрим три алгоритма поиска сильных компонентов в орграфах.
Мы будем использовать тот же интерфейс, что и для задачи связности в алгоритмах поиска на неориентированных графах общего вида (см. программу 18.4). Назначение наших алгоритмов в том, чтобы присвоить номера компонентов каждой вершине в векторе, индексированном именами вершин, используя для обозначения сильных компонентов числа 0, 1, ... . Наибольший из присваиваемых номеров равен числу, на единицу меньшему количества сильных компонентов. Эти номера компонентов можно использовать для проверки за постоянное время, входят ли две заданные вершины в один и тот же сильный компонент.
Нетрудно разработать примитивный алгоритм решения этой задачи. С помощью АТД абстрактного транзитивного замыкания проанализируем каждую пару вершин s и t: достижима ли t из s и достижима ли s из t. Затем определим неориентированный граф с ребрами для каждой такой пары: связные компоненты этого графа соответствуют сильным компонентам орграфа. Этот алгоритм нетрудно описать и реализовать, а время его выполнения определяется в основном реализацией абстрактно-транзитивного замыкания, как сказано, скажем, в лемме 19.10.
Алгоритмы, которые мы рассмотрим в данном разделе — воплощение последних достижений в области построения алгоритмов. Они могут найти сильные компоненты любого графа за линейное время, т.е. в Vраз быстрее примитивного алгоритма. Для графов, содержащих 100 вершин, эти алгоритмы работают в 100 раз быстрее примитивного алгоритма, а для 1000 вершин — в 1000 раз быстрее, и мы можем решать подобные задачи для графов с миллионами вершин. Эта задача является характерным примером хорошего проектирования алгоритма, и мощным стимулом пристального изучения алгоритмов на графах. Где еще можно сэкономить используемые ресурсы в миллион и более раз за счет выбора элегантного алгоритма решения практически важной задачи?
История этой задачи достаточно поучительна (см. раздел ссылок). В пятидесятые и шестидесятые годы математики и специалисты по вычислительной технике приступили к серьезному изучению алгоритмов на графах. В это время как раз развивался сам анализ алгоритмов как область исследований. Во время бурного развития компьютерных систем, языков и формирования понятия эффективных вычислений приходилось рассматривать разнообразные алгоритмы обработки графов, однако многие такие задачи оставались нерешенными. Постепенно компьютерные специалисты стали постигать многие базовые принципы анализа алгоритмов и стали понимать, какие задачи на графах могут быть решены эффективно, а для каких задач это невозможно, и начали разрабатывать все более эффективные алгоритмы решения для первого набора задач. Р. Тарьян (R. Tarjan) предложил линейные по времени алгоритмы решения задачи сильной связности и других задач на графах в 1972 году, и в этом же году Р Карп (R. Karp) доказал невозможность эффективного решения задачи коммивояжера и многих других задач на графах. Долгое время с алгоритма Тарьяна начинались многие продвинутые курсы по анализу алгоритмов, поскольку он решает важную практическую задачу, используя простые структуры данных. В 1980-х годах Р Косарайю (R. Kosaraju) рассмотрел эту задачу с другой стороны и разработал новое решение; позднее оказалось, что статья с описанием этого же метода была опубликована в советской научной литературе намного раньше — в 1972 г. Позже, в 1999 г., Г. Габову (H. Gabov) удалось получить простую реализацию одного из первых подходов, предложенных в шестидесятых годах, то есть третий линейный по времени алгоритм для этой задачи.
Суть всего этого не только в том, что трудные задачи обработки графов могут иметь простые решения, но и в том, что абстракции, которыми мы пользуемся (поиск в глубину и списки смежности), гораздо мощнее, чем мы можем предполагать. Так что не стоит удивляться, что по мере освоения этих и других подобных средств будут обнаруживаться новые простые решения и других важных задач на графах. Исследователи продолжают поиски подобных компактных реализаций для многих других важных алгоритмов на графах, и много таких алгоритмов еще предстоит открыть.
Метод Косарайю прост для понимания и реализации. Чтобы найти сильные компоненты графа, сначала выполняется поиск в глубину на его обращении, который вычисляет перестановку вершин, определенных обратной нумерацией. (Такой процесс представляет собой топологическую сортировку, если орграф является DAG-графом.) Затем выполняется еще один DFS на этом графе, но чтобы найти следующую вершину для поиска (при вызове рекурсивной функции поиска — в самом начале и при каждом возврате управления рекурсивной функцией в функцию поиска более высокого уровня), берется непосещенная вершина с максимальным обратным номером.
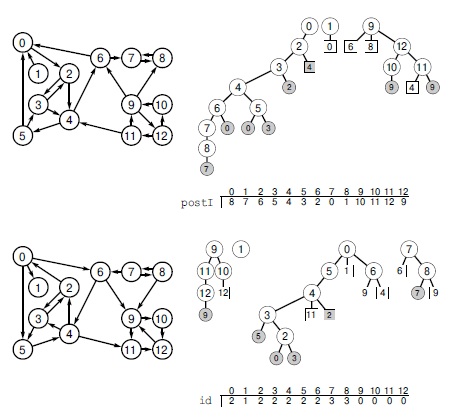
Фокус в этом алгоритме заключается в том, что при такой проверке непосещенных вершин в соответствии с топологической сортировкой деревья в лесе DFS определяют сильные компоненты — так же, как деревья в лесе DFS определяют связные компоненты в неориентированных графах: две вершины принадлежат одному и тому же сильному компоненту тогда и только тогда, когда они принадлежат одному и тому же дереву в этом лесе. На рис. 19.28 демонстрируется этот факт для нашего примера, а доказательство будет приведено чуть ниже. Поэтому можно пронумеровать компоненты, как в случае неориентированных графов, увеличивая номер компонента на единицу при каждом возврате рекурсивной функции на более высокий уровень. В программе 19.10 приведена полная реализация этого метода.
Чтобы вычислить сильные компоненты орграфа, изображенного внизу слева, мы сначала выполняем поиск в глубину на его обращении (вверху слева), вычисляя вектор обратных номеров, который присваивает вершинам индексы в порядке завершения рекурсивных DFS (вверху). Этот порядок эквивалентен обратному обходу леса DFS (вверху справа). Затем с помощью обращения этого порядка выполняется поиск в глубину на исходном графе (внизу). Сначала мы проверяем все узлы, доступные из вершины 9, затем просматриваем вектор справа налево и находим, что самая правая непосещенная вершина — это 1, поэтому мы выполняем рекурсивный вызов для вершины 1 и т.д. Деревья в лесе DFS, полученные в результате этого процесса, определяют сильные компоненты: все вершины каждого дерева имеют одинаковые значения в векторе id, индексированном именами вершин (внизу).
Программа 19.10. Сильные компоненты (алгоритм Косарайю)
Клиенты могут использовать объекты этого класса для определения количества сильных компонентов орграфа (count) и проверок на сильную связность (stronglyreachable). Конструктор SC сначала создает обратный орграф и вычисляет с помощью DFS обратную нумерацию. Далее он выполняет поиск в глубину на исходном орграфе, используя обращение обратного порядка из первого поиска в глубину в цикле поиска, в котором выполняются вызовы рекурсивной функции. Каждый рекурсивный вызов во втором DFS посещает все вершины сильного компонента.
template <class Graph>
class SC
{ const Graph &G;
int cnt, scnt;
vector<int> postI, postR, id;
void dfsR(const Graph &G, int w)
{ id[w] = scnt;
typename Graph::adjIterator A(G, w);
for (int t = A.beg(); !A.end(); t = A.nxt())
if (id[t] == -1) dfsR(G, t);
postI[cnt++] = w;
}
public:
SC(const Graph &G) : G(G), cnt(0), scnt(0),
postI(G.V()), postR(G.V()), id(G.V(), -1)
{ Graph R(G.V(), true);
reverse(G, R);
for (int v = 0; v < R.V(); v++)
if (id[v] == -1) dfsR(R, v);
postR = postI; cnt = scnt = 0;
id.assign(G.V(), -1);
for (int v = G.V()-1; v >= 0; v--)
if (id[postR[v]] == -1)
{ dfsR(G, postR[v]); scnt++; }
}
int count() const { return scnt; }
bool stronglyreachable(int v, int w) const
{ return id[v] == id[w]; }
};
Лемма 19.14. Метод Косарайю находит сильные компоненты графа с линейными затратами времени и памяти.
Доказательство. Этот метод состоит из двух процедур DFS с небольшими изменениями, поэтому время его выполнения, как обычно, пропорционально V2 для насыщенных графов и V + E для разреженных графов (в случае представления списками смежности). Чтобы доказать, что он правильно вычисляет сильные компоненты, необходимо доказать, что во втором поиске две вершины s и t находятся в одном и том же дереве леса DFS тогда и только тогда, когда они взаимно достижимы.
Если вершины s и t взаимно достижимы, они обязательно находятся в одном и том же дереве DFS: когда первая из них посещена, вторая еще не посещена и достижима из первой. Поэтому она будет просмотрена до завершения рекурсивного вызова из корня.
Чтобы доказать обратное утверждение, предположим, что s и t находятся в одном и том же дереве, и пусть r — корень этого дерева. Из достижимости s из r (через ориентированный путь, состоящий из древесных ребер) следует, что в обратном орграфе существует ориентированный путь из s в r. В обратном орграфе должен существовать и путь из r в s, поскольку r имеет больший обратный номер, чем s (т.к. при втором поиске в глубину r была выбрана первой, когда обе вершины еще не были посещены), и существует путь из s в r. Ведь если бы пути из s в r не было, то путь из s в r в обратном орграфе оставил бы вершине s больший обратный номер. Итак, существуют ориентированные пути из s в r и из r в s — как в орграфе, так и в его обращении — то есть s и r сильно связаны. Аналогичные рассуждения доказывают, что t и r сильно связаны, и поэтому s и t также сильно связаны. 
Реализация алгоритма Косарайю для орграфа, представленного матрицей смежности, даже проще, чем программа 19.10, поскольку в этом случае не нужно явно вычислять обратный граф. Решение этой задачи мы оставляем на самостоятельную проработку (см. упражнение 19.125).
Программа 19.10 представляет собой оптимальное решение задачи сильной связности, аналогичное решениям задачи связности, рассмотренным в "Поиск на графе" . В разделе 19.9 будет рассмотрено расширение этого решения для вычисления транзитивного замыкания и решения задачи достижимости (абстрактного транзитивного замыкания) в орграфах.
Но вначале мы рассмотрим алгоритм Тарьяна и алгоритм Габова — хитроумные методы, требующие лишь небольших изменений в нашей базовой процедуре поиска в глубину. Они удобнее алгоритма Косарайю, поскольку используют только один проход по графу и не требуют обращения разреженных графов.
Алгоритм Тарьяна похож на программу из "Виды графов и их свойства" для поиска мостов в неориентированных графах (см. программу 18.7). Этот метод основан на двух наблюдениях, которые были сделаны в других контекстах. Во-первых, мы рассматриваем вершины в обратном топологическом порядке, чтобы в конце работы рекурсивной функции для вершины мы знали, что не встретим ни одной вершины из того же сильного компонента (потому что все вершины, достижимые из этой, уже обработаны). Во-вторых, обратные ссылки в дереве обеспечивают второй путь из одной вершины в другую и связывают сильные компоненты.
Для поиска достижимой вершины с максимальным номером (через обратную ссылку) из любого потомка каждой вершины в рекурсивной функции DFS выполняются те же вычисления, что и в программе 18.7. В ней также используется вектор, индексированный именами вершин, для отслеживания сильных компонентов и стек для хранения текущего пути поиска. Имена вершин заносятся в стек при входе в рекурсивную функцию, а после посещения последнего элемента каждого сильного компонента они выталкиваются из стека, при этом назначаются номера компонентам. Алгоритм основан на возможности определять этот момент при помощи простой проверки в конце рекурсивной процедуры (для этого отслеживается предок с максимальным номером, достижимый по одной восходящей ссылке из всех потомков каждого узла). Эта проверка сообщает, что все вершины, встреченные с момента входа (за исключением тех, которые уже приписаны какому-либо компоненту), принадлежат тому же сильному компоненту.
Реализация в программе 19.11 представляет собой полное описание рассматриваемого алгоритма, со всеми подробностями, которых нет в вышеприведенном общем описании. На рис. 19.29 показана работа алгоритма на нашем демонстрационном орграфе с рис. 19.1.
Программа 19.11. Сильные компоненты (алгоритм Тарьяна)
Данный класс DFS — еще одна реализация того же интерфейса, что и в программе 19.10. Он использует стек S для хранения каждой вершины до тех пор, пока не выяснится, что все вершины в верхней части стека до определенного уровня принадлежат одному и тому же сильному компоненту. Вектор low, индексированный именами вершин, отслеживает вершину с наименьшим прямым номером, достижимую из каждого узла через ряд нисходящих ссылок, за которыми следует одна восходящая ссылка (см. текст).
#include "STACK.cc"
template <class Graph>
class SC
{ const Graph &G;
STACK<int> S;
int cnt, scnt;
vector<int> pre, low, id;
void scR(int w)
{ int t;
int min = low[w] = pre[w] = cnt+ + ;
S.push(w);
typename Graph::adjIterator A(G, w);
for (t = A.beg(); !A.end(); t = A.nxt())
{ if (pre[t] == -1) scR(t);
if (low[t] < min) min = low[t];
}
if (min < low[w]) { low[w] = min; return; }
do
{ id[t = S.pop()] = scnt; low[t] = G.V(); }
while ( t ! = w) ;
scnt++;
}
public:
SC(const Graph &G) : G(G), cnt(0), scnt(0),
pre(G.V(), -1), low(G.V()), id(G.V())
{ for (int v = 0; v < G.V(); v++)
if (pre[v] == -1) scR(v);
}
int count() const { return scnt; }
bool stronglyreachable(int v, int w) const
{ return id[v] == id[w]; }
};
В основе алгоритма Тарьяна лежит рекурсивный DFS с дополнительным помещением вершин в стек. Он вычисляет индекс компонента для каждой вершины в векторе id, индексированном именами вершин, используя вспомогательные векторы pre и low (в центре). Дерево DFS для нашего демонстрационного графа показано в верхней части рисунка, а трассировка ребер — внизу слева. В центре нижней части приведено содержимое главного стека: в него заносятся вершины, достижимые через древесные ребра. Используя DFS для перебора вершин в обратном топологическом порядке, мы вычисляем для каждой вершины v максимальную точку, достижимую через обратную ссылку из предшественника (low[v]). Когда для вершины v выполняется pre[v]= low[v] (в данном случае это вершины 11, 1, 0 и 7), мы выталкиваем из стека ее и все вершины выше нее, и присваиваем им всем номер следующего компонента.
В алгоритме Габова мы заносим вершины в главный стек — как и в алгоритме Тарьяна — но параллельно заносим во второй стек (внизу справа) вершины, лежащие на пути поиска, о которых известно, что они находятся в других сильных компонентах, и выталкиваем все вершины после достижения каждого обратного ребра. Когда мы завершаем обработку вершины v (v находится на верхушке второго стека — на рисунке заштриховано), мы знаем, что все вершины, расположенные над v в главном стеке, находятся в одном и том же сильном компоненте.
Лемма 19.15. Алгоритм Тарьяна находит сильные компоненты орграфа за линейное время.
Схема доказательства. Если у вершины s нет потомков или восходящих ссылок в дереве DFS, либо если у нее есть потомок в дереве DFS с восходящей ссылкой, которая указывает на s, и нет потомков с восходящими ссылками, которые направлены в более высокую часть дерева, то она и все ее потомки (кроме вершин, которые удовлетворяют тому же свойству, и их потомков) составляют сильный компонент. Чтобы установить этот факт, заметим, что у каждого потомка t вершины s, который не удовлетворяет указанному свойству, имеется потомок с восходящей ссылкой, указывающей на вершину, которая находится в дереве выше t.
В дереве имеется нисходящий путь из s в t, а путь из t в s можно найти следующим образом: спускаемся по дереву из t в вершину с восходящей ссылкой, которая указывает выше t, затем продолжаем такой же процесс из этой вершины, пока не дойдем до s.
Как обычно, этот метод линеен по времени, поскольку он состоит из стандартного DFS с несколькими дополнительными операциями, выполняющимися за постоянное время.
В 1999 году Габов разработал версию алгоритма Тарьяна, приведенную в программе 19.12. Этот алгоритм использует такой же стек вершин и тем же способом, что и алгоритм Тарьяна, но он использует второй стек (вместо вектора прямых номеров, индексированного именами вершин) — для определения момента, когда нужно выталкивать из главного стека все вершины каждого сильного компонента. Этот второй стек содержит вершины, входящие в путь поиска. Когда обратное ребро показывает, что последовательность таких вершин целиком принадлежит одному и тому же сильному компоненту, мы выталкиваем содержимое этого стека, оставляя в нем только конечную вершину обратного ребра, которая находится ближе к корню дерева, чем любая другая вершина. После обработки всех ребер каждой вершины (выполняя рекурсивные вызовы всех ребер дерева, выталкивая из стека пути для обратных ребер и игнорируя прямые ребра), мы проверяем, находится ли текущая вершина в верхушке стека пути. Если это так, то она и все вершины над ней в главном стеке составляют сильный компонент — мы выталкиваем их из стека и присваиваем им номер следующего сильного компонента, как и в алгоритме Тарьяна.
Пример на рис. 19.29 показывает содержимое этого второго стека. То есть эта диаграмма может служить иллюстрацией работы алгоритма Габова.
Программа 19.12. Сильные компоненты (алгоритм Габова)
Данная альтернативная реализация рекурсивной функции-члена из программы 19.11 использует вместо вектора low, индексированного номерами вершин, второй стек path, чтобы определять, когда нужно выталкивать из главного стека вершины каждого сильного компонента (см. текст).
void scR(int w)
{ int v;
pre[w] = cnt++;
S.push(w); path.push(w);
typename Graph::adjIterator A(G, w);
for (int t = A.beg(); !A.end(); t = A.nxt())
if (pre[t] == -1)
scR(t);
else if (id[t] == -1)
while (pre[path.top()] > pre[t]) path.pop();
if (path.top() == w) path.pop(); else return;
do { id[v = S.pop()] = scnt; } while (v != w);
scnt++;
}
Лемма 19.16. Алгоритм Габова находит сильные компоненты орграфа за линейное время.
Формализация вышеизложенного рассуждения и доказательство взаимосвязи содержимого стеков, на котором оно основано — полезное упражнение для математически подготовленных читателей (см. упражнение 19.132). Этот метод также линеен по времени, поскольку он состоит из стандартного DFS с несколькими дополнительными операциями, выполняющимися за постоянное время.
Все рассмотренные в данном разделе алгоритмы выявления сильных компонентов оригинальны и обманчиво просты. Мы рассмотрели все три алгоритма, поскольку они демонстрируют мощь фундаментальных структур данных и тщательно разработанных рекурсивных программ. С практической точки зрения время выполнения всех этих алгоритмов пропорционально количеству ребер орграфа, и различия в производительности больше зависят от деталей реализации. Например, внутренний цикл алгоритмов Тарьяна и Габова составляют операции АТД стека магазинного типа. В нашей реализации используются простейшие реализации класса стека из "Абстрактные типы данных" ; реализации, использующие контейнеры stack из библиотеки STL, которые выполняют разные проверки и других действия, могут работать медленнее. Реализация алгоритма Косарайю — пожалуй, простейшая из всех трех, но она содержит небольшой недостаток (для разреженных графов): в ней выполняются три прохода по ребрам (один проход для построения обратного графа и два прохода поиска в глубину).
Теперь мы рассмотрим ключевое приложение, вычисляющее сильные компоненты: построение АТД эффективной достижимости (абстрактное транзитивное замыкание) в орграфах.
Упражнения
19.120. Опишите, что произойдет, если воспользоваться алгоритмом Косарайю для поиска сильных компонентов DAG-графа.
19.121. Опишите, что произойдет, если воспользоваться алгоритмом Косарайю для поиска сильных компонентов орграфа, который состоит из одного цикла.
19.122. Можно ли не вычислять обращение орграфа в версии метода Косарайю для представления списками смежности (программа 19.10), используя одну из трех технологий, описанных в разделе 19.4, которые позволяют не вычислять обращение при выполнении топологической сортировки? Для каждой технологии либо докажите, что она работает, либо приведите контрпример, показывающий, что она не работает.
19.123. Покажите в стиле рис. 19.28 леса DFS и содержимое вспомогательных векторов, индексированных именами вершин, которые получаются при использовании алгоритма Косарайю для вычисления сильных компонентов обращения орграфа с рис. 19.5. (Должны получиться те же самые сильные компоненты.)
19.124. Покажите в стиле рис. 19.28 леса DFS и содержимое вспомогательных векторов, индексированных именами вершин, которые получаются при использовании алгоритма Косарайю для вычисления сильных компонентов обращения орграфа
3-71-47-80-55-23-82-90-64-92-66-4.
19.125. Реализуйте алгоритм Косарайю для поиска сильных компонентов орграфа в представлении, которое поддерживает проверку существования ребра. Реализация не должна содержать явное вычисление обращения графа. Указание. Рассмотрите возможность использования двух различных рекурсивных функций DFS.
19.126. Опишите, что произойдет, если использовать алгоритм Тарьяна для поиска сильных компонентов DAG-графа.
19.127. Опишите, что произойдет, если использовать алгоритм Тарьяна для поиска сильных компонентов орграфа, который состоит из одного цикла.
19.128. Покажите в стиле рис. 19.28 лес DFS, содержимое стека во время выполнения алгоритма и окончательное содержимое вспомогательных векторов, индексированных именами вершин, которые получаются при использовании алгоритма Тарьяна для вычисления сильных компонентов обращения орграфа с рис. 19.5. (Должны получиться те же самые сильные компоненты.)
19.129. Покажите в стиле рис. 19.28 лес DFS, содержимое стека во время выполнения алгоритма и окончательное содержимое вспомогательных векторов, индексированных именами вершин, которые получаются при использовании алгоритма Тарья-на для вычисления сильных компонентов орграфа
3-71-47-80-55-23-82-90-64-92-66-4.
19.130. Измените реализации алгоритма Тарьяна в программе 19.11 и алгоритма Габова в программе 19.12, чтобы они могли использовать сигнальные значения и не выполнять явную проверку поперечных ссылок.
19.131. Покажите в стиле рис. 19.29 лес DFS, содержимое обоих стеков во время выполнения алгоритма и окончательное содержимое вспомогательных векторов, индексированных именами вершин, которые получаются при использовании алгоритма Габова для вычисления сильных компонентов орграфа
3-71-47-80-55-23-82-90-64-92-66-4.
19.132. Приведите полное доказательство леммы 19.16.
19.133. Разработайте версию алгоритма Габова, которая находит мосты и реберносвязные компоненты в неориентированных графах.
19.134. Разработайте версию алгоритма Габова, который находит точки сочленения и двусвязные компоненты в неориентированных графах.
19.135. Составьте таблицу в стиле таблица 18.1 для изучения сильных компонентов в случайных графах (см. таблица 19.2). Пусть S — множество вершин в наибольшем сильном компоненте. Изменяя размер множества S, проанализируйте процент ребер в следующих четырех классах: соединяющие две вершины внутри S, указывающие на вершины вне S, указывающие на вершины внутри S, и соединяющие две вершины вне S.
19.136. Эмпирически сравните примитивный метод вычисления сильных компонентов, описанный в начале этого раздела, с алгоритмом Косарайю, с алгоритмом Тарьяна и с алгоритмом Габова для различных типов орграфов (см. упражнения 19.11-19.18).
19.137. Разработайте линейный по времени алгоритм для задачи сильной 2-связности: нужно определить, остается ли сильно связанный орграф сильно связным после удаления любой вершины (и всех инцидентных ей ребер).
Бактыгуль Асаинова
Александра Боброва
|
Я прошла все лекции на 100%. Но в https://www.intuit.ru/intuituser/study/diplomas ничего нет. Что делать? Как получить сертификат? |