
|
Здравствуйте прошла курсы на тему Алгоритмы С++. Но не пришел сертификат и не доступен.Где и как можно его скаачат? |
Опубликован: 05.01.2015 | Доступ: свободный | Студентов: 2196 / 0 | Длительность: 63:16:00
Специальности: Программист, Системный архитектор, Тестировщик, Архитектор программного обеспечения
Лекция 17:
Виды графов и их свойства
Генераторы графов
Чтобы углубить наше понимание различных свойств графов как комбинаторных структур, теперь мы рассмотрим подробные примеры графов, которыми позднее воспользуемся для тестирования изучаемых алгоритмов. Некоторые из этих примеров заимствованы из конкретных приложений. Другие взяты из математических моделей, которые предназначены как для исследования свойств, с какими мы можем столкнуться в реальных графах, так и для расширения набора входных данных, позволяющих тестировать наши алгоритмы.
Для конкретизации примеров мы представим их в виде клиентских функций программы 17.1 -тогда мы сможем непосредственно применять их для тестирования рассматриваемых реализаций алгоритмов на графах. Кроме того, мы рассмотрим реализацию функции io::scan из программы 17.4, которая считывает последовательность пар произвольных имен из стандартного ввода и строит граф с вершинами, соответствующими именам, и ребрами, соответствующими парам.
Реализации, которые будут рассмотрены в этом разделе, основаны на интерфейсе из программы 17.1, так что теоретически они должны правильно работать для любого представления графа. Хотя на практике, как мы увидим, некоторые сочетания интерфейса и представлений не могут обеспечить приемлемой производительности.
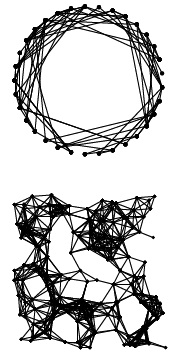
Оба приведенных здесь графа содержат по 50 вершин. Разреженный граф в верхней части рисунка содержит 50 ребер, а насыщенный граф в нижней части рисунка -500ребер. Разреженный граф не является связным, поскольку каждая его вершина соединена только с небольшим количеством других вершин; насыщенный граф, несомненно, является связным, т.к. каждая его вершина связана в среднем с 20 другими вершинами. Эти диаграммы демонстрируют сложность разработки алгоритмов вычерчивания произвольных графов (на рисунке вершины размещены в случайно выбранных местах).
Как обычно, нам нужны " случайные экземпляры задач " -как для опробования наших задач на произвольных входных данных, так и для получения представления о поведении программы в реальных ситуациях. В случае графов вторая цель достигается не так легко, как в других рассмотренных ранее предметных областях, но все-таки оправдывает затрачиваемые усилия. Мы столкнемся с различными моделями случайных данных, начиная со следующих двух.
Случайные ребра. Реализация этой модели довольно проста -см. генератор, представленный в программе 17.12. Для заданного количества вершин V генерируются произвольные ребра, т.е. пары случайных чисел от 0 до V—1. Результатом, скорее всего, будет произвольный мультиграф с петлями. Любая пара может содержать два одинаковых числа (т.е. возможны петли); и любая пара может повториться несколько раз (т.е. возможны параллельные ребра). Программа 17.12 генерирует ребра до тех пор, пока не наберется E ребер; решение об удалении параллельных ребер остается за реализацией. Если удалять параллельные ребра, то в насыщенных графах количество генерируемых ребер будет значительно больше, чем количество использованных ребер (E) (см. упражнение 17.62 и рис. 17.12); поэтому данный метод обычно используется для разреженных графов.
Случайный граф. Классическая математическая модель случайных графов -включение в граф каждого возможного ребра с одинаковой вероятностью p. Если нужно, чтобы ожидаемое количество ребер графа было равно E, следует выбрать p = 2E/V(V-1). Функция в программе 17.13 использует эту модель для генерации случайных графов.
Программа 17.12. Генератор случайных графов (случайные ребра)
Данная функция добавляет в граф случайные ребра. Для этого она генерирует E случайных пар целых чисел, интерпретируя числа как метки вершин, а пары меток вершин как ребра. Решение о том, как поступать с параллельными ребрами и петлями, возлагается на функцию-член insert класса Graph. Обычно этот метод не годится для генерации очень больших и насыщенных графов из-за большого количества параллельных ребер.
static void randE(Graph &G, int E)
{ for (int i = 0; i < E; i++)
{ int v = int(G.V()*rand()/(1.0+RAND MAX));
int w = int(G.V()*rand()/(1.0+RAND MAX));
G.insert(Edge(v,w));
}
}
Параллельные ребра не допускаются, а количество ребер в графе равно E только в среднем. Эта реализация удобна для генерации насыщенных, а не разреженных графов, поскольку за время, пропорциональное V(V-1)/2, она генерирует E = pV(V-1)/2 ребер. То есть для разреженных графов время работы программы 17.13 квадратично зависит от размера графа (см. упражнение 17.68).
Эти модели хорошо изучены, а их реализация не представляет трудностей, однако они не обязательно генерируют такие графы, которые встречаются на практике. В частности, графы, которые моделируют карты, электронные схемы, расписания, транзакции, сети и другие реальные ситуации, обычно являются не только разреженными, но и локальными -вероятность того, что заданная вершина связана с одной из вершин конкретного множества вершин, выше, чем с другими вершинами. Как показывают следующие примеры, существует много различных способов моделирования локальности.
Программа 17.13. Генератор случайных графов (случайный граф)
Как и в программе 17.12, данная функция генерирует случайные пары целых чисел от 0 до V—1 и добавляет их в граф как ребра, однако она использует другую вероятностную модель, по условиям которой каждое возможное ребро появляется независимо от других с вероятностью p. Значение p вычисляется таким образом, чтобы ожидаемое количество ребер (pV(V—1)/2) было равно E. Количество ребер в каждом конкретном графе, сгенерированном этой программой, близко к E, однако вряд ли точно равно E. Этот метод пригоден в основном для насыщенных графов, поскольку время его выполнения пропорционально V2.
static void randG(Graph &G, int E)
{ double p = 2.0*E/G.V()/(G.V()-1);
for (int i = 0; i < G.V(); i++)
for (int j = 0; j < i; j++)
if (rand() < p*RAND MAX)
G.insert(Edge(i, j));
}
k-соседний граф. Граф, изображенный в верхней части рис. 17.13, получен в результате простого изменения в генераторе графов со случайными ребрами, мы выбираем случайным образом первую вершину v, затем случайным образом выбираем следующую вершину из тех, индексы которых отстоят от v не более чем на постоянное число к (с возвратом от V-1 до 0, если вершины упорядочены в виде окружности, как на рис. 17.13). Такие графы легко генерируются и, безусловно, обладают свойством локальности, которое не характерно для случайных графов.
Здесь приведены примеры двух моделей разреженных графов. Граф с соседними связями в верхней части рисунка содержит 33 вершины и 99ребер, и каждое ребро может соединять одну вершину с другой, если их индексы отличаются не более чем на 10 (по модулю V). Евклидов граф с соседними связями в нижней части рисунка моделирует графы, которые встречаются в приложениях, где вершины привязаны к конкретным геометрическим точкам. Для вершин выбраны случайные точки на плоскости, а ребра соединяют любую пару вершин, расстояние между которыми не превышает d.
Этот граф относится к категории разреженных (177вершин и 1001 ребро). Изменяя значения d, можно построить граф любой степени насыщенности.
Евклидов граф с соседними связями. Граф, показанный в нижней части рис. 17.13, вычерчен генератором, который выбирает на плоскости V точек со случайными координатами от 0 до 1, а затем генерирует ребра, соединяющие любые две точки, расстояние между которыми не превышает d. Если d невелико, то граф получается разреженным, а если d большое, то граф насыщенный (см. упражнение 17.74). Такой граф моделирует графы, с которыми мы сталкиваемся при работе с картами, электронными схемами или другими приложениями, где вершины привязаны к определенным геометрическим точкам. Их нетрудно представить наглядно, они позволяют наглядно увидеть свойства алгоритмов, характерные для подобных приложений.
Один из возможных недостатков этой модели состоит в том, что разреженные графы запросто могут оказаться несвязными; еще одна трудность заключается в низкой вероятности появления вершин высокой степени, а также в отсутствии длинных ребер. При желании можно внести в эти модели изменения для устранения этих недостатков, а можно рассмотреть многочисленные аналогичные примеры и попытаться смоделировать другие ситуации (см., например, упражнения 17.72 и 17.73).
Алгоритмы можно тестировать и на реальных графах. Во многих ситуациях нет недостатка в примерах задач, основанных на реальных данных, которые можно использовать для тестирования алгоритмов. Например, довольно часто встречаются очень большие графы, полученные из реальных географических данных, еще два таких примера приведены в двух последующих абзацах. Преимущество работы с реальными, а не с моделированными графами, заключается в том, что в процессе совершенствования алгоритмов мы сразу видим решения реальных задач. Недостаток -мы можем потерять возможность оценивать производительность разрабатываемых алгоритмов с помощью математического анализа. Мы вернемся к этой теме в конце "Поиск на графе" , когда будем готовы провести сравнение решений одной и той же задачи несколькими различными алгоритмами.
Такие последовательности пар чисел могут представлять список телефонных вызовов в местной телефонной станции, или финансовые операции между счетами, или любую подобную ситуацию, если выполняются транзакции между двумя элементами, которым присвоены уникальные идентификаторы. Такие графы нельзя рассматривать как чисто случайные, ведь некоторые телефонные номера используются намного чаще, чем остальные, а некоторые счета гораздо более активны, чем другие.
Граф транзакций. На рис. 17.14 показан всего лишь небольшой фрагмент графа, который можно обнаружить в компьютерах телефонной компании. В этом графе каждому телефонному номеру соответствует вершина, а каждое ребро, соединяющее пару i и j, соответствует телефонному звонку от i к j в течение некоторого фиксированного промежутка времени. Это множество ребер представляет собой мультиграф огромных размеров. Он, естественно, разрежен, поскольку каждый абонент звонит лишь в мизерную часть всех доступных телефонов. Этот граф характерен и для многих других приложений. Аналогичную информацию может, например, содержать кредитная карточка финансового учреждения и записи кредитной истории.
Граф вызовов функций. Граф можно поставить в соответствие любой компьютерной программе: функции будут в нем вершинами графа, а ребро будет соединять вершину X с вершиной Y всякий раз, когда функция X вызывает функцию Y. Программу можно даже оснастить средством построения таких графов (или переложить эту задачу на компилятор). Нас интересуют два абсолютно различных графа: статическая версия, когда ребра создаются на этапе компиляции на основе вызовов функций, которые находятся в коде каждой функции; и динамическая версия, когда ребра создаются во время выполнения программы, при фактическом выполнении вызовов. Статические графы вызовов функций нужны для изучения структуры программы, а динамические -для изучения поведения программы. Обычно это большие разреженные графы.
В подобных случаях приходится иметь дело с большими объемами данных, поэтому изучать производительность алгоритмов часто лучше на реальных данных, а не на вероятностных моделях. Можно попытаться избежать вырожденных случаев, выбирая ребра случайным образом или вводя случайность в сами алгоритмы, но это все-таки не генерация случайных графов. А во многих случаях изучение свойств структуры графа является самостоятельной целью.
В некоторых приведенных выше примерах вершины представляют собой естественные имена объектов, а ребра -пары именованных объектов. Например, граф транзакций может быть построен из последовательности пар телефонных номеров, а евклидов граф -из последовательности пар населенных пунктов. Программа 17.14 представляет собой реализацию функции scan из программы 17.4, которой можно воспользоваться для построения графов в общих ситуациях. Для удобства клиентских программ она использует в качестве определения графа множество ребер и определяет множество имен вершин графа на основании их присутствия в ребрах. А именно, программа считывает последовательность пар символов из стандартного ввода, использует таблицу символов для связывания этих символов с номерами вершин от 0 до V-1 (где V -количество различных символов во входных данных) и строит граф путем вставки ребер, как в программах 17.12 и 17.13. Для потребности программы 17.14 можно приспособить любую реализацию таблицы символов -например, программу 17.15, в которой используются TST-деревья (см. "Хеширование" ). Эти программы упрощают тестирование алгоритмов на реальных графах, которые невозможно точно описать какой бы то ни было вероятностной моделью.
Программа 17.14. Построение графа из пар символов
Данная реализация функции scan из программы 17.4 использует таблицу символов для построения графа на основе пар символов, считываемых из стандартного ввода. Функция index АТД таблицы символов ставит в соответствие каждому символу целое число: если поиск в таблице размера N заканчивается неудачно, она добавляет в таблицу символ с привязанным к нему целым числом N+1; а если поиск завершается успешно, она просто возвращает целое число, которое ранее было связано с этим символом. Годится любой метод работы с таблицами символов из рассмотренных в части IV -например, программа 17.15.
#include "ST.cc"
template <class Graph>
void IO<Graph>::scan(Graph &G)
{ string v, w;
ST st;
while (cin >> v >> w)
G.insert(Edge(st.index(v), st.index(w)));
}
Программа 17.15 важна еще и потому, что она обосновывает наше допущение, которое было сделано во всех разрабатываемых нами алгоритмах: что имена вершин являются целочисленными значениями от 0 до V-1. Если у какого-то графа имеется другое множество имен вершин, то перед построением представления графа нужно выполнить программу 17.15, чтобы переобозначить имена вершин целыми числами из диапазона от 0 до V-1.
Бактыгуль Асаинова
Александра Боброва
|
Я прошла все лекции на 100%. Но в https://www.intuit.ru/intuituser/study/diplomas ничего нет. Что делать? Как получить сертификат? |