|
Здравствуйте прошла курсы на тему Алгоритмы С++. Но не пришел сертификат и не доступен.Где и как можно его скаачат? |
Опубликован: 05.01.2015 | Доступ: свободный | Студентов: 2182 / 0 | Длительность: 63:16:00
Специальности: Программист, Системный архитектор, Тестировщик, Архитектор программного обеспечения
Лекция 15:
Поразрядный поиск
В таблица 15.2 приведены экспериментальные данные, подтверждающие выводы, приведенные в двух предыдущих абзацах.
| N | Создание | Неудачный поиск | ||||||
|---|---|---|---|---|---|---|---|---|
| B | H | T | T* | B | H | T | T* | |
| 1250 | 4 | 4 | 5 | 5 | 2 | 2 | 2 | 1 |
| 2500 | 8 | 7 | 10 | 9 | 5 | 5 | 3 | 2 |
| 5000 | 19 | 16 | 21 | 20 | 10 | 8 | 6 | 4 |
| 12500 | 48 | 48 | 54 | 97 | 29 | 27 | 15 | 14 |
| 25000 | 118 | 99 | 188 | 156 | 67 | 59 | 36 | 30 |
| 50000 | 230 | 191 | 333 | 255 | 137 | 113 | 70 | 65 |
| Обозначения: | |
| B | Стандартное BST-дерево (программа 12.8) |
| H | Хеширование с цепочками переполнения (M = N/5) (программа 14.3) |
| T | TST-дерево (программа 15.8) |
| T* | TST-дерево с R 2-путевым ветвлением в корне (программы 15.11 и 15.12) |
Эти сравнительные значения времени построения и поиска в таблицах символов, образованных строковыми ключами, наподобие библиотечных номеров на рис. 15.18, подтверждают, что TST-деревья, хотя и требуют больших затрат при построении, обеспечивают наиболее быстрый неудачный поиск строковых ключей. В основном это обусловлено тем, что для поиска не требуется просмотр всех символов ключа.
Третья причина привлекательности TST-деревьев заключается в том, что они поддерживают более общие операции, чем рассмотренные операции таблиц символов. Например, в программе 15.9 можно не указать отдельные символы ключа поиска, и она выведет все ключи в структуре данных, которые соответствуют указанным цифрам искомого ключа. Пример такого поиска показан на рис. 15.19. Очевидно, что, внеся небольшие изменения, эту программу можно приспособить для перебора всех соответствующих ключей (как для операции сортировать), а не просто для их вывода (см. упражнение 15.58).
TST-деревья позволяют легко решать еще несколько аналогичных задач. Например, можно посетить все ключи в структуре данных, которые отличаются от ключа поиска не более чем одним цифровым символом (см. упражнение 15.59). В других реализациях таблиц символов подобные операции требуют больших затрат или вовсе невозможны. Эти и многие другие задачи обнаружения нестрогого соответствия со строкой поиска будут рассмотрены в части 5.
Patricia-деревья предоставляют несколько аналогичных преимуществ; основное практическое преимущество TST-деревьев по сравнению с patricia-деревьями заключается в том, что они обеспечивают доступ к байтам или символам, а не к разрядам ключей. Одна из причин, почему это различие считается преимуществом, связана с тем, что предназначенные для этого машинные операции реализованы во многих компьютерах, а C++ обеспечивает непосредственный доступ к байтам символьных строк в стиле C. Другая причина состоит в том, что в некоторых приложениях работа с байтами или символами в структуре данных естественным образом соответствует байтовой структуре самих данных — например, в задаче поиска частичного соответствия, описанной в предыдущем абзаце (хотя, как будет показано в "Поиск на графе" , поиск частичного соответствия можно ускорить и с помощью продуманного использования доступа к разрядам).
Для устранения однонаправленных путей в TST-деревьях заметим, что большинство однонаправленных путей соответствует концам ключей, что несущественно, если применяется реализация таблицы символов, в которой записи хранятся в листьях, помещенных на самом верхнем уровне дерева различения ключей. Можно также использовать индексацию байтов, как в patricia-деревьях (см. упражнение 15.65), однако для простоты мы опустим это изменение. Сочетание многопутевого ветвления и представления в виде TST-дерева и само по себе достаточно эффективно во многих приложениях, но свертывание однонаправленных путей в стиле patricia-деревьев еще больше повышает производительность в тех случаях, когда ключи часто совпадают во многих символах подряд (см. упражнение 15.72).
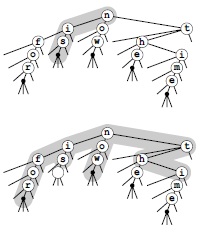
Чтобы найти все ключи в TST-дереве, которые соответствуют шаблону i* (вверху), мы выполняем поиск i в BST-дереве для первого символа. В данном примере после двух однопутевых разветвлений найдено слово is — единственное слово, соответствующее шаблону. Чтобы найти соответствия более общему шаблону наподобие *o* (внизу), в BST-дереве посещаются все узлы, соответствующие первому символу, но поиск продолжается только там, где есть o во втором символе — окончательно это дает слова for и now.
Еще одно простое усовершенствование поиска, основанного на использовании TST-деревьев — использование большого явного многопутевого узла в корне. Для этого проще всего хранить таблицу R TST-деревьев: по одному для каждого возможного значения первой буквы в ключах. Если значение R невелико, можно использовать первые две буквы ключей (и таблицу размером R2 ). Чтобы этот метод был эффективен, ведущие цифры ключей должны быть распределены достаточно равномерно. Результирующий гибридный алгоритм поиска соответствует тому, как человек мог бы искать фамилии в телефонном справочнике. Вначале принимается многопутевое решение ( " Так, фамилия начинается на А " ), а затем, вероятно, принимается несколько двухпутевых решений ( " Она находится перед Анискин, но после Азазель " ), после чего символы сравниваются последовательно ( " Алгонавт... Нет, Алгоритмиста здесь нет, поскольку ни одно слово не начинается с Алгор! " ).
Программы 15.10—15.12 включают в себя основанную на TST-дереве реализацию операций таблицы символов найти и вставить, в которой используется R-путевое ветвление в корне и хранение элементов в листьях (поэтому здесь нет однонаправленных путей, если ключи различны).
Эти программы, похоже, являются наиболее быстрыми программами поиска строковых ключей или ключей с большим основанием системы счисления. Лежащая в их основе структура TST-дерева может поддерживать также множество других операций.
В таблице символов, которая разрастается до очень больших размеров, можно согласовывать коэффициент ветвления с размером таблицы. В главе 16 "Внешний поиск" будет показан систематический способ увеличения многопутевого trie-дерева, чтобы можно было воспользоваться преимуществами многопутевого поиска при произвольных размерах файлов.
Лемма 15.8. Для выполнения поиска или вставки в TST-дереве, содержащем элементы в листьях (не имеющем однонаправленных путей в нижней части дерева) и с Rt-путевым ветвлением в корне, требуется приблизительно ln N — t ln R обращений к байтам для N случайных строковых ключей. При этом количество требуемых ссылок равно Rt (для корневого узла) плюс небольшая константа, умноженная на N.
Эти грубые оценки непосредственно следуют из леммы 15.6. При оценке затрат времени мы принимаем, что все узлы на пути поиска, за исключением небольшого постоянного количества узлов у вершины, выступают по отношению к R значениям символов как случайные BST-деревья. Поэтому затраты времени просто умножаются на lnR. При оценке затрат памяти предполагается, что узлы на нескольких первых уровнях заполнены R значениями символов, а узлы на нижних уровнях содержат только постоянное количество символов. 
Например, при наличии 1 миллиарда случайных строковых ключей, при R = 256 и при использовании на верхнем уровне таблицы размером
R2 = 65536
, для выполнения типичного поиска потребуется около 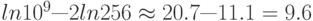 сравнений байтов. Использование таблицы в верхней части дерева уменьшает затраты на поиск в два раза.
сравнений байтов. Использование таблицы в верхней части дерева уменьшает затраты на поиск в два раза.
Если ключи действительно случайны, этой производительности можно достичь с помощью более непосредственных алгоритмов, использующих ведущие байты ключа и таблицу существования, как было описано в "Хеширование" . Однако TST-деревья позволяют получить такую же производительность и при менее случайной структуре ключей.
Программа 15.10. Определения типов узлов в гибридном TST-дереве
Этот код определяет структуры данных, используемые в программах 15.11 и 15.12, которые предназначены для реализации таблицы символов с помощью TST-деревьев. Здесь используется R-путевое ветвление в корне: корень представляет собой массив heads, состоящий из R ссылок и индексированный первой цифрой ключей. Каждая ссылка указывает на TST-дерево, построенное из всех ключей, которые начинаются с соответствующей цифры. Этот гибрид сочетает в себе преимущества trie-деревьев (быстрый поиск с помощью индексации в корне) и TST-деревьев (эффективное использование памяти: один узел для каждого символа кроме корня).
struct node
{ Item item; int d; node *l, *m, *r;
node(Item x, int k)
{ item = x; d = k; l = 0; m = 0; r = 0; }
node(node* h, int k)
{ d = k; l = 0; m = h; r = 0; }
int internal()
{ return d != NULLdigit; }
};
typedef node *link;
link heads[R];
Item nullItem;
Интересно сравнить TST-деревья без многопутевого ветвления в корне со стандартными BST-деревьями при использовании случайных ключей. В соответствии с леммой 15.8 для выполнения поиска в TST-дереве требуется около lnN сравнений байтов, в то время как в стандартных BST-деревьях требуется около lnN сравнений ключей. В верхней части BST-дерева сравнения ключей можно выполнить с помощью сравнения всего одного байта, но в нижней части для выполнения сравнения ключа может потребоваться много байтовых сравнений. Но не это различие в производительности является решающим. Причины, по которым при использовании строковых ключей TST-деревья предпочтительнее стандартных BST-деревьев, таковы: они обеспечивают быстрый неудачный поиск; они непосредственно годятся для многопутевого ветвления в корне; и (что наиболее важно) они хорошо подходят для строковых ключей, не являющихся случайными, поэтому в TST-дереве длина поиска никогда не превышает длину ключа.
Программа 15.11. Вставка в гибридное TST-дерево для АТД таблицы символов
Данная реализация операции вставить использует TST-деревья, содержащие элементы в листьях (что обобщает программу 15.3). В ней используется R-путевое ветвление по первому символу и отдельные TST-деревья — для всех слов, начинающихся с каждого символа. Если поиск завершается на пустой ссылке, то создается лист для хранения элемента. Если поиск завершается в листе, создаются внутренние узлы, необходимые для различения найденного и искомого ключей. private:
link split(link p, link q, int d)
{ int pd = digit(p->item.key(), d),
qd = digit(q->item.key(), d);
link t = new node(nullItem, qd);
if (pd < qd)
{ t->m = q; t->l = new node(p, pd); }
if (pd == qd)
{ t->m = split(p, q, d+1); }
if (pd > qd)
{ t->m = q; t->r = new node(p, pd); }
return t;
}
link newext(Item x)
{ return new node(x, NULLdigit); }
void insertR(link& h, Item x, int d)
{ int i = digit(x.key(), d);
if (h == 0)
{ h = new node(newext(x), i); return; }
if (!h->internal())
{ h = split(newext(x), h, d); return; }
if (i < h->d) insertR(h->l, x, d);
if (i == h->d) insertR(h->m, x, d+1);
if (i > h->d) insertR(h->r, x, d);
}
public:
ST(int maxN)
{ for (int i = 0; i < R; i++) heads[i] = 0; }
void insert(Item x)
{ insertR(heads[digit(x.key(), 0)], x, 1); }
Программа 15.12. Поиск в гибридном TST-дереве для АТД таблицы символов
Данная реализация операции найти для TST-деревьев (построенных программой 15.11) похожа на поиск в многопутевом trie-дереве, но в ней каждый узел (за исключением корня) содержит только три, а не R, ссылки. Цифры ключа используются при спуске вниз по дереву, который завершается либо на пустой ссылке (неудачный поиск), либо в листе, содержащем ключ, который или равен (успешный поиск), или не равен (неудачный поиск) искомому ключу.
private:
Item searchR(link h, Key v, int d)
{ if (h == 0) return nullItem;
if (h->internal())
{ int i = digit(v, d), k = h->d;
if (i < k) return searchR(h->l, v, d);
if (i == k) return searchR(h->m, v, d+1);
if (i > k) return searchR(h->r, v, d);
}
if (v == h->item.key()) return h->item;
return nullItem;
}
public:
Item search(Key v)
{ return searchR(heads[digit(v, 0)], v, 1); }
Некоторые приложения не могут воспользоваться преимуществом R-путевого ветвления в корне — например, все ключи в примере с библиотечными номерами на рис. 15.18 рис. 15.18 начинаются с буквы L или W. Для других приложений может требоваться более высокий коэффициент ветвления в корне: например, как было сказано, если бы ключи были случайными целыми числами, пришлось бы использовать максимально большую таблицу. Подобную зависимость от приложения можно использовать при настройке алгоритма на максимальную производительность, но не следует забывать о том, что одно из наиболее привлекательных свойств TST-деревьев — возможность не беспокоиться о зависимости от приложений и обеспечение достаточно высокой производительности без каких-либо настроек.
Вероятно, наиболее важное свойство trie-деревьев или TST-деревьев с записями в листьях заключается в том, что их характеристики производительности не зависят от длины ключа. Следовательно, их можно использовать для ключей произвольной длины. В разделе 15.5 мы рассмотрим одно очень эффективное приложение такого рода.
Упражнения
15.49. Нарисуйте trie-дерево существования, образованное вставками слов now is the time for all good people to come the aid of their party в первоначально пустое дерево. Используйте 27-путевое ветвление.
15.50. Нарисуйте TST-дерево существования, образованное вставками слов now is the time for all good people to come the aid of their party в первоначально пустое дерево.
15.51. Нарисуйте 4-путевое trie-дерево, образованное вставками элементов с ключами 01010011 00000111 00100001 01010001 11101100 00100001 10010101 01001010 в первоначально пустое дерево, в котором используются 2-разрядные байты.
15.52. Нарисуйте TST-дерево, образованное вставками элементов с ключами 01010011 00000111 00100001 01010001 11101100 00100001 10010101 01001010 в первоначально пустое дерево, в котором используются 2-разрядные байты.
15.53. Нарисуйте TST-дерево, образованное вставками элементов с ключами 01010011 00000111 00100001 01010001 11101100 00100001 10010101 01001010 в первоначально пустое дерево, в котором используются 4-разрядные байты.
15.54. Нарисуйте TST-дерево, образованное вставками элементов с ключами библиотечных номеров на рис. 15.18 в первоначально пустое дерево.
15.55. Измените реализацию поиска и вставки в многопутевом trie-дереве, приведенную в программе 15.7, так, чтобы она работала для ключей фиксированной длины, которые являются w-байтовыми словами (т.е. не требуется указание конца ключа).
15.56. Измените реализацию поиска и вставки в TST-дереве, приведенную в программе 15.8, так, чтобы она работала для ключей фиксированной длины, которые являются w-байтовыми словами (т.е. не требуется указание конца ключа).
15.57. Экспериментально сравните время и объем памяти, требуемые для 8-путевого trie-дерева, построенного из случайных целых чисел с использованием 3-разрядных байтов, для 4-путевого trie-дерева, построенного из случайных целых чисел с использованием 2-разрядных байтов, и для бинарного trie-дерева, построенного из тех же ключей, при N = 103, 104, 105 и 106 (см. упражнение 15.14).
15.58. Измените программу 15.9 так, чтобы она посещала все узлы, соответствующие искомому ключу (аналогично операции сортировать).
15.59. Напишите функцию, которая для заданного целочисленного значения k выводит все ключи в TST-дереве, отличающиеся от искомого не более чем в k позициях.
15.60. Приведите полную характеристику длины внутреннего пути худшего случая R-путевого trie-дерева с N различными w-разрядными ключами.
15.61. Разработайте реализацию таблицы символов на основе многопутевых trie-деревьев, которая включает в себя деструктор, конструктор копирования и перегруженную операцию присваивания, а также поддерживает операции создать, подсчитать, найти, вставить, удалить и объединить для АТД первого класса таблицы символов, поддерживающей клиентские дескрипторы (см. упражнения 12.6 и 12.7).
15.62. Разработайте реализацию таблицы символов на основе многопутевых TST-деревьев, которая включает в себя деструктор, конструктор копирования и перегруженную операцию присваивания, а также поддерживает операции создать, подсчитать, найти, вставить, удалить и объединить для АТД первого класса таблицы символов, поддерживающей клиентские дескрипторы (см. упражнения 12.6 и 12.7).
15.63. Напишите программу, которая выводит все ключи в R-путевом trie-дереве, имеющие те же первые t байтов, что и заданный ключ поиска.
15.64. Измените реализацию поиска и вставки в многопутевом trie-дереве, приведенную в программе 15.7, чтобы исключить однонаправленные пути, как в patricia-деревьях.
15.65. Измените реализацию поиска и вставки в TST-дереве, приведенную в программе 15.8, чтобы исключить однонаправленные пути, как в patricia-деревьях.
15.66. Напишите программу, которая балансирует BST-деревья, представляющие внутренние узлы TST-дерева (реорганизует их так, чтобы все их внешние узлы располагались на одном или двух уровнях).
15.67. Напишите версию операции вставить для TST-деревьев, которая поддерживает представление всех внутренних узлов в виде сбалансированных деревьев (см. упражнение 15.66).
15.68. Приведите полную характеристику длины внутреннего пути худшего случая TST-дерева, содержащего N различных w-разрядных ключей.
15.69. Напишите программу, генерирующую случайные 80-байтовые строковые ключи (см. упражнение 10.19). Воспользуйтесь этим генератором для построения 256-пу-тевого trie-дерева, содержащего N случайных ключей при N = 103, 104, 105 и 106 , применяя операцию найти, а после неудачного поиска — операцию вставить. Программа должна выводить общее количество узлов в каждом дереве и общее время построения каждого дерева.
15.70. Выполните упражнение 15.69 для TST-деревьев. Сравните полученные характеристики производительности с характеристиками trie-деревьев.
15.71. Напишите программу, которая генерирует ключи, тасуя случайную 80-байтовую последовательность (см. упражнение 10.21). Воспользуйтесь полученным генератором ключей для построения 256-путевого trie-дерева, содержащего N случайных ключей при N = 103, 104, 105 и 106 . Для вставки применяйте операцию найти, а после неудачного поиска — операцию вставить. Сравните полученные характеристики производительности с характеристиками для случайных ключей из упражнения 15.69.
о 15.72. Напишите программу, которая генерирует 30-байтовые случайные строки из четырех полей: 4-байтового поля, содержащего одну из 10 заданных строк; 10-байтового поля, содержащего одну из 50 заданных строк; 1-байтового поля, содержащего одно из двух заданных значений; и 15-байтового поля, содержащего случайные буквенные выровненные влево строки, длина которых с равной вероятностью может составлять от 4 до 15 символов (см. упражнение 10.23). Воспользуйтесь этим генератором ключей для построения 256-путевого trie-дерева, содержащего N случайных ключей при N = 103, 104, 105 и 106 . Для вставки применяйте операцию найти, а после неудачного поиска — операцию вставить. Обеспечьте возможность вывода общего количества узлов в каждом trie-дереве и общего времени, затраченного на построение каждого trie-дерева. Сравните полученные характеристики производительности с характеристиками для случайных ключей (см. упражнение 15.69).
15.73. Выполните упражнение 15.72 для случая TST-деревьев. Сравните полученные характеристики производительности с характеристиками для trie-деревьев.
15.74. Разработайте реализацию операций найти и вставить для ключей в виде строк байтов, использующую многопутевые деревья цифрового поиска.
15.75. Нарисуйте 27-путевое DST-дерево (см. упражнение 15.74), образованное вставками элементов с ключами now is the time for all good people to come the aid of their party в первоначально пустое дерево.
15.76. Разработайте реализацию поиска и вставки в многопутевом trie-дереве, в котором для представления узлов trie-дерева используются связные списки (в отличие от используемого для TST-деревьев представления в виде BST-дерева). Определите экспериментальным путем, что эффективнее использовать: упорядоченные или неупорядоченные списки, и сравните эту реализацию с реализацией на основе TST-деревьев.
Бактыгуль Асаинова
Александра Боброва
|
Я прошла все лекции на 100%. Но в https://www.intuit.ru/intuituser/study/diplomas ничего нет. Что делать? Как получить сертификат? |