
|
Здравствуйте прошла курсы на тему Алгоритмы С++. Но не пришел сертификат и не доступен.Где и как можно его скаачат? |
Опубликован: 05.01.2015 | Доступ: свободный | Студентов: 2196 / 0 | Длительность: 63:16:00
Специальности: Программист, Системный архитектор, Тестировщик, Архитектор программного обеспечения
Лекция 12:
Таблицы символов и деревья бинарного поиска
Бинарный поиск
В реализации последовательного поиска в массиве большого количества элементов общее время поиска можно существенно сократить, используя процедуру поиска, основанную на стандартном принципе " разделяй и властвуй " (см. "Рекурсия и деревья" ): делим множество элементов на две части, определяем, к какой из двух частей принадлежит искомый ключ, и затем продолжаем поиск в этой части. Разумный способ разделения множества элементов на части состоит в поддержании упорядоченности элементов и использовании индексов в отсортированном массиве для определения той части массива, с которой нужно продолжать работать. Такая технология поиска называется бинарным поиском (binary search). Программа 12.7 представляет собой рекурсивную реализацию этой фундаментальной стратегии. В программе 2.2 показана нерекурсивная реализация, в которой стек не нужен, поскольку рекурсивная функция в программе 12.7 завершается рекурсивным вызовом.
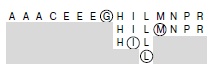
На рис. 12.1 показаны подфайлы, проверяемые в ходе бинарного поиска в небольшой таблице; на рис. 12.2 приведен больший пример. Каждая итерация отбрасывает чуть больше половины таблицы, поэтому количество требуемых итераций мало.
Для нахождения искомого ключа L в этом файле с помощью бинарного поиска достаточно только трех итераций. В первом вызове алгоритм сравнивает L с ключом в середине файла - G. Поскольку L больше этого ключа, в следующей итерации используется правая половина файла. Затем, поскольку L меньше M, находящегося в середине правой половины, в ходе третьей итерации рассматривается подфайл, состоящий из трех элементов - H, I и L. После выполнения еще одной итерации размер подфайла становится равным 1, и алгоритм находит ключ L.
Для нахождения записи в файле из 200 элементов бинарный поиск требует только семь итераций. Размеры подфайлов описываются последовательностью 200, 99, 49, 24, 11, 5, 2, 1; то есть каждая из исследуемых частей несколько меньше половины предыдущей.
Программа 12.7. Бинарный поиск (в таблице символов на основе массива)
Данная реализация функции search использует процедуру рекурсивного бинарного поиска. Для определения, присутствует ли заданный ключ v в отсортированном массиве, этот ключ сначала сравнивается с элементом в средней позиции. Если v меньше, он должен находиться в первой половине массива, а если больше - то во второй.
Массив должен быть отсортирован. Этой функцией можно заменить функцию search в программе 12.5, которая обеспечивает динамическое упорядочение во время вставки. Либо можно добавить конструктор таблицы символов, использующий стандартную процедуру сортировки, который принимает массив в качестве аргумента, а затем строит таблицу символов из элементов входного массива и готовит ее к поиску с помощью одной из стандартных подпрограмм сортировки.
private:
Item searchR(int l, int r, Key v)
{ if (l > r) return nullItem;
int m = (l+r)/2;
if (v == st[m].key()) return st[m];
if (l == r) return nullItem;
if (v < st[m].key())
return searchR(l, m-1, v);
else
return searchR(m+1, r, v);
}
public:
Item search(Key v)
{ return searchR(0, N-1, v); }
Лемма 12.5. При бинарном поиске выполняется не более чем  сравнений (и при успешном, и при неудачном).
сравнений (и при успешном, и при неудачном).
См. лемму 2.3. Интересно отметить, что максимальное количество сравнений, используемых для бинарного поиска в таблице размером N, в точности равно количеству битов в двоичном представлении числа N, поскольку операция сдвига на один бит вправо преобразует двоичное представление N в двоичное представление числа 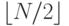 (см. рис. 2.6
рис.
2.6).
(см. рис. 2.6
рис.
2.6). 
Поддержание таблицы в отсортированном виде, как при сортировке вставками, приводит к квадратичной зависимости времени выполнения от количества операций вставить, но эти затраты можно считать приемлемыми или даже пренебрежимыми при очень большом количестве операций найти. В типичной ситуации, когда все элементы (или большая их часть) доступны до начала поиска, можно создать таблицу с помощью конструктора, который принимает в качестве параметра массив и во время инициализации использует один из стандартных методов сортировки, описанных в лекциях 6-10. После этого обновления таблицы могут выполняться различными способами. Например, можно поддерживать упорядоченность во время вставок, как в программе 12.5 (см. также упражнение 12.21), либо накопить их отдельно, выполнить сортировку и слить с существующей таблицей (как описано в упражнении 8.1). Всякое обновление может быть связано со вставкой элемента, ключ которого меньше ключа любого из элементов таблицы, и тогда для освобождения места может потребоваться сдвиг всех элементов.
Эти потенциально высокие затраты на обновление таблицы - наибольший недостаток использования бинарного поиска. С другой стороны, существует огромное число приложений, в которых достаточно заранее отсортировать статическую таблицу, и в этом случае, благодаря быстрому доступу, обеспечиваемому такими реализациями, как программа 12.7, бинарный поиск очень удобен.
Если новые элементы требуется вставлять динамически, то для этого больше подошла бы связная структура. Однако односвязный список не позволяет создать эффективную реализацию, поскольку эффективность бинарного поиска зависит от возможности быстро попасть с помощью индекса в середину любого под-массива, а единственный способ попасть в середину связного списка - это проход по ссылкам. Для объединения эффективности бинарного поиска и гибкости связных структур требуются более сложные структуры данных, которые мы рассмотрим чуть позже.
Если в таблице могут быть повторяющиеся ключи, бинарный поиск можно расширить, включив операции для подсчета количества элементов с данным ключом или возврата их в виде группы. Несколько элементов, ключи которых совпадают с искомым, образуют в таблице непрерывный блок (поскольку таблица упорядочена), и в программе 12.7 успешный поиск завершится где-то внутри этого блока. Если приложению требуется доступ ко всем таким элементам, в программу можно добавить код для выполнения просмотра в обоих направлениях от точки завершения поиска и возврата двух индексов, ограничивающих элементы с ключами, равными искомому. В этом случае время выполнения поиска пропорционально lgN плюс количество найденных элементов. Аналогичный подход используется для решения более общей задачи поиска в диапазоне, которая состоит в нахождении всех элементов, ключи которых попадают в указанный интервал. Мы рассмотрим подобные расширения базового набора операций с таблицами символов в части 6.
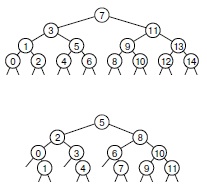
Последовательность сравнений, выполняемых алгоритмом бинарного поиска, предопределена: конкретная используемая последовательность зависит от значения искомого ключа и значения N. Ее можно описать в виде структуры бинарного дерева, подобной приведенной на рис. 12.3. Это дерево похоже на дерево из "Слияние и сортировка слиянием" , используемое для описания размеров под-файлов во время сортировки слиянием ( рис. 8.3). Но в бинарном поиске используется один путь в дереве, тогда как при сортировке слиянием - все пути. Это дерево является статическим и неявным; в разделе 12.5 будут рассмотрены алгоритмы, в которых для выполнения поиска используется динамическая, явно построенная структура бинарного дерева.
На этих диаграммах в виде деревьев " разделяй и властвуй " показана последовательность индексов для сравнений при бинарном поиске. Эти последовательности зависят только от размера исходного файла, но не от значений ключей в файле. Такие деревья несколько отличаются от деревьев, соответствующих сортировке слиянием и аналогичным алгоритмам ( рис. 5.6 и 8.3), поскольку элемент, находящийся в корне, в поддеревья не включается.
На верхней диаграмме показан поиск в файле из 15 элементов, проиндексированных от 0 до 14. Анализируется средний элемент (с индексом 7), затем (рекурсивно) левое поддерево, если искомый элемент меньше его, или правое поддерево, если искомый элемент больше корня. Каждый поиск соответствует пути от корня до низа дерева: например, поиск элемента, значение которого находится между 10 и 11, проходит по пути 7, 11, 9 и 10. Для файлов, размер которых не равен степени 2 минус 1, структура не настолько регулярна - пример одной из них (для 12 элементов) приведен на нижней диаграмме.
Одно из возможных усовершенствований бинарного поиска - более точное предположение о положении ключа поиска в текущем интервале (вместо тупого сравнения его на каждом шаге со средним элементом). Эта тактика имитирует способ поиска имени в телефонном справочнике или слова в словаре: если нужная запись начинается с буквы, находящейся в начале алфавита, мы открываем книгу ближе к началу, а если она начинается с буквы из конца алфавита, поиск выполняется в конце книги. Для реализации данного метода, называемого интерполяционным поиском (interpolation search), нужно заменить в программе 12.7 оператор
m = (l+r)/2
на оператор
m = l+(v-[l].key())*(r-l)/(a[r].key()-a[l].key());
Для обоснования этого изменения отметим, что выражение (l + r) / 2 равнозначно выражению 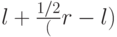 : мы вычисляем середину интервала, добавляя к левой границе половину размера интервала. Использование интерполяционного поиска сводится к замене в этой формуле коэффициента
: мы вычисляем середину интервала, добавляя к левой границе половину размера интервала. Использование интерполяционного поиска сводится к замене в этой формуле коэффициента 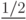 оценкой положения ключа - а именно
оценкой положения ключа - а именно 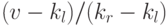 , где kl и kr соответственно означают a[l].key() и a[r].key(). При этом предполагается, что значения ключей являются числовыми и равномерно распределенными.
, где kl и kr соответственно означают a[l].key() и a[r].key(). При этом предполагается, что значения ключей являются числовыми и равномерно распределенными.
Можно показать, что при интерполяционном поиске в файлах со случайными ключами для каждого поиска (успешного или неудачного) используется менее lg lg N + 1 сравнений. Доказательство этого утверждения выходит далеко за рамки этой книги. Эта функция растет очень медленно, и на практике ее можно считать постоянной: если N равно 1 миллиарду, то lg lg N < 5. Таким образом, любой элемент можно найти, выполнив лишь несколько обращений (в среднем) - это существенное достижение по сравнению с бинарным поиском. Для ключей, которые распределены не вполне случайно, производительность интерполяционного поиска еще выше. А его граничным случаем является метод распределяющего поиска, описанный в разделе 12.2.
Однако интерполяционный поиск в значительной степени основывается на предположении, что ключи распределены во всем интервале более или менее равномерно - в противном случае, что обычно и имеет место на практике, метод окажется гораздо менее эффективным. Кроме того, для его реализации требуются дополнительные вычисления. Для небольших значений N затраты на обычный бинарный поиск (lg N) достаточно близки к затратам интерполяционного поиска (lg lg N), и поэтому интерполяцию вряд ли стоит использовать. Однако интерполяционный поиск определенно заслуживает внимания при работе с большими файлами, в приложениях, в которых сравнения очень дорогостоящи, и при использовании внешних методов, сопряженных с большими затратами на доступ.
Упражнения
12.34. Приведите нерекурсивную реализацию функции бинарного поиска (см. программу 12.7).
12.35. Нарисуйте деревья, соответствующие рис. 12.3 для N = 17 и N = 24.
12.36. Найдите значения N, для которых бинарный поиск в таблице символов размером N становится в 10, 100 и 1000 раз быстрее последовательного поиска. Предскажите значения аналитически и проверьте их экспериментально.
12.37. Пусть вставки в динамическую таблицу символов размера N реализованы как в сортировке вставками, но для выполнения операции найти используется бинарный поиск. Предположим, что поиск выполняется в 1000 раз чаще, чем вставки. Определите в процентах долю времени, затрачиваемую на вставки, для N = 103, 104, 105 и 106 .
12.38. Разработайте реализацию таблицы символов, в которой используются бинарный поиск и " ленивая " вставка и поддерживаются операции создать, подсчитать, найти, вставить и сортировать, с помощью следующей стратегии. Храните большой отсортированный массив для основной таблицы символов и неупорядоченный массив для недавно вставленных элементов. При вызове функции search отсортируйте недавно вставленные элементы (если они есть), слейте их с основной таблицей, а затем воспользуйтесь бинарным поиском.
12.39. Добавьте " ленивое " удаление в реализацию из упражнения 12.38.
12.40. Ответьте на вопрос упражнения 12.37 для реализации из упражнения 12.38.
12.41. Реализуйте функцию, аналогичную бинарному поиску (программа 12.7), которая возвращает количество элементов в таблице символов с ключами, равными данному.
12.42. Напишите программу, которая при заданном значении N создает последовательность N макрокоманд вида compare(l, h), проиндексированных от 0 до N-1, где i-я макрокоманда в списке означает " сравнить ключ поиска со значением в таблице по индексу i; затем при равенстве сообщить, что ключ найден; если он меньше, выполнить l-ю инструкцию, и если больше - h-ю инструкцию " (индекс 0 зарезервируйте для индикации неудачного поиска). Любой поиск с помощью этой последовательности должен выполнять те же сравнения, что и бинарный поиск на этом наборе данных.
12.43. Разработайте расширение макрокоманд, созданных в упражнении 12.42, чтобы программа создавала машинный код, выполняющий бинарный поиск в таблице размером N при наименьшем возможном количестве машинных инструкций на одно сравнение.
12.44. Пусть a[i] == 10*i для значений i в интервале от 1 до N. Сколько позиций в таблице просматриваются интерполяционным поиском при неудачном поиске значения 2k - 1?
12.45. Найдите значения N, для которых интерполяционный поиск в таблице символов размером N выполняется в 1, 2 и 10 раз быстрее бинарного поиска, при условии, что ключи случайны. Предскажите эти значения аналитически и проверьте их экспериментально.
Бактыгуль Асаинова
Александра Боброва
|
Я прошла все лекции на 100%. Но в https://www.intuit.ru/intuituser/study/diplomas ничего нет. Что делать? Как получить сертификат? |