|
Здравствуйте прошла курсы на тему Алгоритмы С++. Но не пришел сертификат и не доступен.Где и как можно его скаачат? |
Опубликован: 05.01.2015 | Доступ: свободный | Студентов: 2187 / 0 | Длительность: 63:16:00
Специальности: Программист, Системный архитектор, Тестировщик, Архитектор программного обеспечения
Лекция 12:
Таблицы символов и деревья бинарного поиска
Программа 12.16. Удаление узла с заданным ключом из BST-дерева
В данной реализации операции удалить выполняется удаление из BST-дерева первого найденного узла с ключом v. Проходя сверху вниз, программа выполняет рекурсивные вызовы для соответствующего поддерева до тех пор, пока удаляемый узел не окажется в корне. Потом этот узел заменяется результатом объединения двух его поддеревьев: наименьший узел в правом поддереве становится корнем, а в его левую ссылку заносится указатель на левое поддерево.
private:
link joinLR(link a, link b)
{ if (b == 0) return a;
partR(b, 0); b->l = a;
return b;
}
void removeR(link& h, Key v)
{ if (h == 0) return;
Key w = h->item.key();
if (v < w) removeR(h->l, v);
if (w < v) removeR(h->r, v);
if (v == w)
{ link t = h; h = joinLR(h->l, h->r);
delete t; }
}
public:
void remove(Item x)
{ removeR(head, x.key()); }
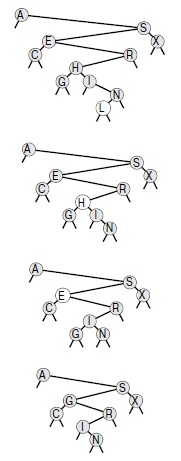
Если все ключи одного BST-дерева меньше ключей второго, то для объединения этих деревьев ко второму дереву применяется операция разбить, чтобы переместить наименьший элемент этого дерева в корень. После этого левое поддерево корня второго дерева должно быть пустым (иначе в нем располагался бы элемент, меньший элемента в корне), и задачу можно завершить, заменив эту ссылку указателем на первое дерево. На рис. 12.19 показан пример дерева и последовательность удалений, иллюстрирующих некоторые из возможных ситуаций.
Здесь показан результат удаления узлов с ключами L, H и E из BST-дерева, показанного на верхнем рисунке. Вначале L просто удаляется, поскольку он расположен внизу. Затем H заменяется его правым дочерним узлом I, поскольку левый дочерний узел I пуст. И, наконец, E заменяется своим потомком G.
Этот подход асимметричен и в одном отношении произволен: почему в качестве корня нового дерева используется наименьший ключ второго дерева, а не наибольший ключ первого дерева? Другими словами, почему удаляемый узел заменяется следующим узлом в поперечном обходе дерева, а не предыдущим? Возможны и другие подходы. Например, если у удаляемого узла левая ссылка пуста, почему бы просто не сделать новым корнем его правый дочерний узел, а не узел с наименьшим ключом в правом поддереве? Было предложено много аналогичных модификаций базовой процедуры удаления. К сожалению, всем им присущ один и тот же недостаток: после удаления дерево перестает быть случайным, даже если оно было случайным до этого. Кроме того, было показано, что если дерево подвергается большому количеству случайных пар операций удаления-вставки, то программа 12.16 склонна оставлять дерево слегка несбалансированным (средняя высота пропорциональна 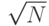 ) (см. упражнение 12.84).
) (см. упражнение 12.84).
Эти различия могут быть не заметны в реальных приложениях, если только N не очень велико. Тем не менее, такое сочетание не очень элегантного алгоритма с неудовлетворительными характеристиками производительности не радует. В "Сбалансированные деревья" будут рассмотрены два различных способа исправления этой ситуации.
Для алгоритмов поиска типична ситуация, когда для удаления требуются более сложные реализации, чем для поиска. Значения ключей играют важную роль в формировании структуры, поэтому удаление ключа может быть сопряжено со сложными исправлениями. Одна из возможных альтернатив - использование " ленивой " стратегии удаления, оставляющей удаленные узлы в структуре данных, но помечающей их как " удаленные " , которые будут игнорироваться при поиске.
В реализации поиска в программе 12.8 эту стратегию можно реализовать, не выполняя проверку на равенство для таких узлов. Необходимо обеспечить, чтобы большое количество помеченных узлов не привело к непомерным затратам времени или памяти, хотя если удаления выполняются не слишком часто, эти дополнительные затраты могут не играть особой роли. Помеченные узлы можно использовать в будущих вставках, когда это удобно (например, это легко сделать для узлов в нижней части дерева). Или же можно периодически перестраивать всю структуру данных, отбрасывая помеченные узлы.
Подобные соображения применимы не только к таблицам символов, но и к любой структуре данных, сопряженной со вставками и удалениями.
В завершение этой главы мы рассмотрим реализацию операции удалить с использованием дескрипторов и операции объединить для реализаций АТД таблицы символов, использующих BST-деревья. Мы предполагаем, что дескрипторы - это ссылки, и опускаем дальнейшие рассуждения на тему оформления, чтобы сосредоточиться на этих двух базовых алгоритмах.
Основная сложность в реализации функции для удаления узла с данным дескриптором (ссылкой) та же, что и для связных списков: необходимо изменить указатель в структуре, который указывает на удаляемый узел. Существует, по меньшей мере, четыре способа решения этой проблемы. Во-первых, в каждый узел дерева можно добавить третью ссылку, указывающую на его родителя. Недостаток этого метода заключается в том, что, как уже неоднократно отмечалось, поддерживать дополнительные ссылки весьма обременительно. Во-вторых, можно использовать ключ элемента для выполнения поиска в дереве, прекращая его после того, как найден соответствующий указатель. Недостаток этого подхода в том, что обычно узел находится в нижней части дерева, и, следовательно, этот подход требует лишнего прохода по дереву. В-третьих, можно воспользоваться ссылкой или указателем на указатель узла в качестве дескриптора. Этот метод работает в языках C++ и C, но не годится для многих других языков. В-четвертых, можно применить " ленивый " подход, как-то помечая удаленные узлы и периодически перестраивая структуру данных, как описано выше.
Последняя операция для АТД таблиц символов, которую мы рассмотрим - операция объединить. В реализации на основе BST-дерева она сводится к слиянию двух деревьев. Как объединить два дерева бинарного поиска в одно? Существуют различные алгоритмы для выполнения этой задачи, но каждому из них присущи определенные недостатки. Например, можно выполнить обход первого BST-дерева, вставляя каждый из его узлов во второе BST-дерево (этот алгоритм можно записать одной строкой: в параметра подпрограммы обхода первого BST-дерева нужно передавать функцию вставки во второе BST-дерево). Время выполнения подобного решения не линейно, поскольку для каждой вставки может требоваться линейное время. Другой вариант - обход обоих BST-деревьев, занесение всех элементов в массив, их объединение и затем построение нового BST-дерева. Эту операцию можно выполнить за линейное время, но для нее нужен потенциально большой массив.
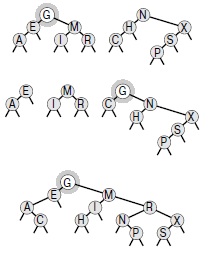
Программа 12.17 - компактная рекурсивная реализация операции объединить с линейным временем выполнения. Вначале мы вставляем корень первого BST-дерева во второе BST-дерево, используя метод вставки в корень. Эта операция дает два поддерева, ключи которых меньше этого корня, и два поддерева, ключи которых больше этого корня, поэтому требуемый результат получается (рекурсивным) объединением первой пары в левое поддерево корня, а второй пары - в правое поддерево корня (!). При каждом рекурсивном вызове каждый узел может оказаться корневым максимум один раз, поэтому общее время линейно. Пример работы этого алгоритма показан на рис. 12.20. Как и удаление, этот процесс асимметричен и может приводить к не очень сбалансированным деревьям, однако, как будет показано в "Сбалансированные деревья" , эта проблема легко устраняется рандомизацией. Обратите внимание, что в худшем случае количество сравнений, использованных для выполнения операции объединить, должно быть по крайней мере линейным; иначе можно было бы разработать алгоритм сортировки с менее чем NlgN сравнений, применяя такой подход, как восходящая сортировка слиянием (см. упражнение 12.88).
Программа 12.17. Объединение двух BST-деревьев
Если одно из BST-деревьев пустое, второе является результатом. Иначе два BST-дерева объединяются путем (произвольного) выбора корня первого дерева в качестве результирующего корня, вставки этого корня в корень второго дерева, а затем (рекурсивного) объединения пары левых поддеревьев и пары правых поддеревьев.
private:
link joinR(link a, link b)
{ if (b == 0) return a;
if (a == 0) return b;
insertT(b, a->item);
b->l = joinR(a->l, b->l);
b->r = joinR(a->r, b->r);
delete a; return b;
}
public:
void join(ST<Item, Key>& b)
{ head = joinR(head, b.head); }
В программу не включен код, необходимый для поддержки полей счетчиков в узлах BST-дерева во время выполнения операций объединить и удалить - он может понадобиться в приложениях, где требуется и операция выбрать (программа 12.14). Концептуально эта задача проста, однако требует определенных усилий. Один из стандартных способов ее выполнения - реализация небольшой вспомогательной процедуры, которая устанавливает значение поля счетчика в узле на единицу больше, чем сумма полей счетчиков в его дочерних узлах, а затем вызов этой процедуры для каждого узла, у которого изменены ссылки. В частности, это можно выполнить для обоих узлов в процедурах rotL и rotR из программы 12.12, что достаточно для преобразований в программах 12.13 и 12.15, поскольку они преобразуют деревья исключительно путем ротаций. Для функций joinLR и removeR в программе 12.16 и join в программе 12.17 достаточно вызвать процедуру обновления счетчика для возвращаемого узла непосредственно перед оператором return.
Здесь показан результат (внизу) объединения двух BST-деревьев (вверху). Вначале мы вставляем корень G первого дерева во второе дерево, используя вставку в корень (второй сверху рисунок). У нас остаются два поддерева, ключи которых меньше G, и два поддерева с ключами, большими G. Объединение обеих пар (рекурсивно) дает конечный результат (внизу).
Базовые операции найти, вставить и сортировать для BST-деревьев легко реализуются и быстро работают даже при малой случайности в последовательности операций, поэтому BST-деревья широко используются для динамических таблиц символов. Они допускают также простые рекурсивные решения для поддержки других операций, как было показано в этой главе на примере операций выбрать, удалить и объединить, и как еще будет показано на многочисленных примерах далее в этой книге.
Несмотря на всю полезность, существует два основных недостатка использования BST-деревьев в приложениях. Во-первых, они требуют существенного дополнительного объема памяти под ссылки. Часто ссылки и записи имеют практически одинаковые размеры (скажем, одно машинное слово) - если это так, реализация с использованием BST-дерева использует две трети выделенного для него объема памяти под ссылки и только одну треть под ключи. Этот эффект менее важен в приложениях с большими записями и более важен в средах, в которых указатели велики. Если же память играет первостепенную роль, лучше вместо BST-деревьев предпочесть один из методов хеширования с открытой адресацией, описанных в "Хеширование" .
Второй недостаток использования BST-деревьев - возможность того, что деревья могут стать плохо сбалансированными и в результате ухудшить производительность. В "Сбалансированные деревья" будут рассмотрены несколько подходов, гарантирующих хорошую производительность. При наличии достаточного объема памяти под ссылки эти алгоритмы делают BST-деревья весьма привлекательными в качестве основы для реализации АТД таблиц символов, поскольку обеспечивают гарантированно высокую производительность для большого набора полезных операций АТД.
Упражнения
12.78. Реализуйте нерекурсивную функцию выбрать для BST-дерева (см. программу 12.14).
12.79. Нарисуйте BST-дерево, образованное вставками элементов с ключами E A S Y Q U T I O N в первоначально пустое дерево и последующим удалением Q.
12.80. Нарисуйте BST-дерево, образованное вставками элементов с ключами E A S Y в первоначально пустое дерево, вставками элементов с ключами Q U E S T I O N в другое первоначально пустое дерево и последующего объединения результатов.
12.81. Реализуйте нерекурсивную функцию удалить для BST-дерева (см. программу 12.16).
12.82. Реализуйте версию операции удалить для BST-деревьев (программа 12.16), которая удаляет все узлы дерева с ключами, равными данному.
12.83. Измените реализации таблиц символов, основанные на BST-дереве, чтобы они поддерживали клиентские дескрипторы элементов (см. упражнение 12.7); добавьте реализации деструктора, конструктора копирования и перегруженной операции присваивания (см. упражнение 12.6); добавьте операции удалить и объединить; воспользуйтесь программой-драйвером из упражнения 12.22 для проверки полученных интерфейса и реализации АТД первого класса для таблицы символов.
12.84. Экспериментально определите увеличение высоты BST-дерева при выполнении длинной последовательности чередующихся случайных операций вставки и удаления в случайном дереве с N узлами, для N = 10, 100 и 1000, если для каждого значения N выполняется до N2 пар вставок-удалений.
12.85. Реализуйте версию функции remove (см. программу 12.16), которая принимает случайное решение, заменять ли удаляемый узел его узлом-предком или узлом-потомком в дереве. Проведите экспериментальное исследование этой версии, как описано в упражнении 12.84.
12.86. Реализуйте версию функции remove, которая использует рекурсивную функцию для перемещения удаляемого узла в нижнюю часть дерева при помощи ротации, подобно вставке в корень (программа 12.13). Нарисуйте дерево, образованное в результате удаления этой программой корня из полного дерева, содержащего 31 узел.
12.87. Экспериментально определите увеличение высоты BST-дерева при многократной вставке элемента из корня в дерево, образованное объединением поддеревьев корня в случайное дерево из N узлов, для N = 10, 100 и 1000.
12.88. Реализуйте версию восходящей сортировки слиянием, основанной на операции объединить. Начните с помещения ключей в N деревьев, состоящих из одного узла, затем объедините эти деревья в пары для получения N/2 деревьев из двух узлов, далее объедините их для получения N/4 деревьев из четырех узлов и т.д.
12.89. Реализуйте версию функции join (см. программу 12.17), которая принимает случайное решение, использовать ли корень первого или второго дерева в качестве корня результирующего дерева. Проведите экспериментальное исследование этой версии, как описано в упражнении 12.87.
Бактыгуль Асаинова
Александра Боброва
|
Я прошла все лекции на 100%. Но в https://www.intuit.ru/intuituser/study/diplomas ничего нет. Что делать? Как получить сертификат? |