
|
Здравствуйие! Я хочу пройти курс Введение в принципы функционирования и применения современных мультиядерных архитектур (на примере Intel Xeon Phi), в презентации самостоятельной работы №1 указаны логин и пароль для доступ на кластер и выполнения самостоятельных работ, но войти по такой паре логин-пароль не получается. Как предполагается выполнение самосоятельных работ в этом курсе? |
Нижегородский государственный университет им. Н.И.Лобачевского
Опубликован: 30.05.2014 | Доступ: свободный | Студентов: 304 / 36 | Длительность: 11:26:00
Специальности: Программист, Системный архитектор
Самостоятельная работа 3: Оптимизация вычислений в задаче о разложении чисел на простые сомножители. Векторизация и балансировка нагрузки
Распределение вычислений с использованием динамического планировщика
Попробуем сбалансировать нагрузку. Для этого воспользуемся дополнительными возможностями директивы #pragma omp parallel for – изменим планировщик со статического на динамический. При динамическом планировании числа будут чередоваться между потоками. Если потока четыре, то первое число достанется первому потоку, второе – второму и т.д. Следующее число, которое получит первый поток, будет 5. Второй 6 и т.д. На рис. 8.9 показан пример распределения чисел при создании четырех потоков.
Ниже приведен код факторизации чисел с использованием динамического планирования.
void factorization()
{
#pragma omp parallel for schedule(dynamic)
for (int i = 1; i < NUM_NUMBERS; i++)
{
int number = i;
int idx = number;
for (int j = 2; j < idx; j++)
{
if (number == 1) break;
int r;
r = number % j;
if (r == 0)
{
number /= j;
divisors[idx].push_back(j);
j--;
}
}
}
}
Скомпилируем и выполним код. На рис. 8.10 представлен результат выполнения программы при использовании динамического планирования.

увеличить изображение
Рис. 8.10. Результат вычислений параллельного кода на MIC с применение статического планирования.
На рис. 8.11 приведен график сравнения времени выполнения параллельных алгоритмов со статическим и динамическим планированием.
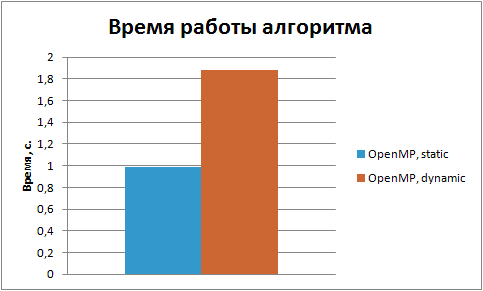
Рис. 8.11. График сравнения времени выполнения параллельных алгоритмов со статическим и динамическим планированием.
Как видно из графика время выполнения алгоритма замедлилось почти в два раза.
В чем причина подобного замедления?
Основная причина в методе распределения чисел. Все четные потоки получают четные числа. Потоков четное число. Как следствие четные ядра сопроцессора будут выполнять работы вдвое меньше. Взамен того, чтобы сбалансировать вычисления мы добились большего дисбаланса. Так как потоков много, дисбаланс при статическом планировании оказался менее ярко выраженным.
Svetlana Svetlana