|
Здравствуйие! Я хочу пройти курс Введение в принципы функционирования и применения современных мультиядерных архитектур (на примере Intel Xeon Phi), в презентации самостоятельной работы №1 указаны логин и пароль для доступ на кластер и выполнения самостоятельных работ, но войти по такой паре логин-пароль не получается. Как предполагается выполнение самосоятельных работ в этом курсе? |
Нижегородский государственный университет им. Н.И.Лобачевского
Опубликован: 30.05.2014 | Доступ: свободный | Студентов: 304 / 36 | Длительность: 11:26:00
Специальности: Программист, Системный архитектор
Самостоятельная работа 3: Оптимизация вычислений в задаче о разложении чисел на простые сомножители. Векторизация и балансировка нагрузки
Гибридная параллельная схема реализации алгоритма
Последним шагом попробуем организовать схему вычислений одновременно на центральном процессоре и на сопроцессоре, что бы задействовать все имеющиеся ресурсы.
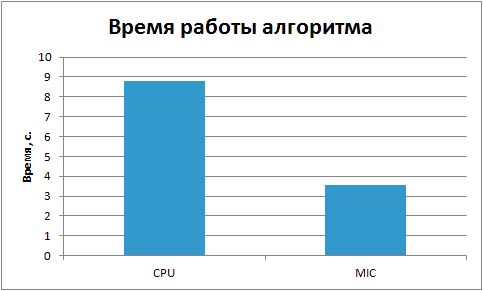
Так как времена стали слишком маленькие, чтобы была возможность сделать какие-то выводы, увеличим количество факторизуемых чисел в 10 раз и замерим время работы алгоритма. Ниже представлены времена работы алгоритмов на сопроцессоре и CPU.
Из графика видно, что соотношение времен сохранилось.
Директива #pragma offload target(mic:0) по умолчанию является синхронной. В данной директиве есть дополнительная опция позволяющая выполнить вычисления асинхронно. Для этого в директиве объявляется сигнал. Для синхронизации сигнал можно проверять и ожидать. Используя сигналы, осуществим статическое распределение нагрузки между процессором и сопроцессором. Для этого, в начале, отправим часть вычислений на Intel Xeon Phi в асинхронном режиме. Оставшуюся часть чисел факторизуем на центральном процессоре.
Модифицируем код основной функции следующим образом:
float *f1;
chunk = NUM_NUMBERS / 2;
time_s = omp_get_wtime( );
#pragma offload target(mic:0) signal(f1)
{
factorization(chunk, 1);
}
factorization(NUM_NUMBERS - chunk, chunk + 1);
#pragma offload target(mic:0) wait(f1)
{
end();
}
time_f = omp_get_wtime( );
Также изменим функцию факторизации для управления распределениями вычислений:
void factorization(int chunk, int start)
{
#pragma omp parallel for schedule(dynamic, 30)
for (int i = start; i < start + chunk; i++)
{
…
}
}
}
Функция end ничего не делает и используется как барьер синхронизации.
Код, связанный с выводом простых чисел, предлагается поправить самостоятельно.
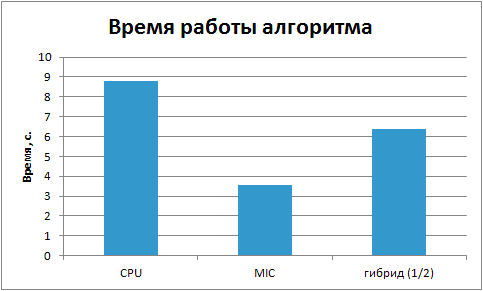
Попробуем запустить код. Ниже представлено сравнение времени вычислений.
Как видно из графика мы получили время вычислений среднее между временем сопроцессора и процессора.
С чем это связано?
Это связано с некорректным распределением нагрузки. Во-первых, время факторизации маленьких и больших чисел не одинаково. Во-вторых, процессор и сопроцессор обладают разной вычислительной производительностью. Попробуем сдвинуть границу. Первые 8/10 чисел отдадим сопроцессору, а оставшиеся вычислим на CPU.
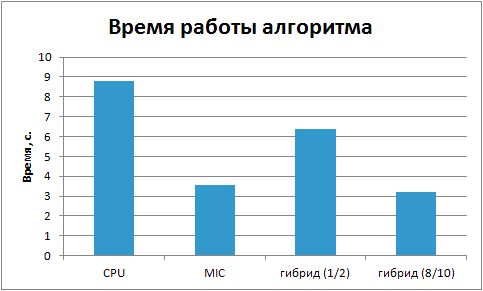
Ниже представлен график сравнения времени вычислений с новым распределением нагрузки.
Как видно из графика, сдвиг границы порций вычислений позволил улучшить время вычислений в целом. В качестве дополнительной задачи предлагается более точно найти границу порций разделения вычислений между процессором и сопроцессором.
Дополнительные задания
- Попробуйте путем изменения количества потоков OpenMP увеличить производительность параллельного алгоритма факторизации чисел. Учтите, что особенностью сопроцессора Intel Xeon Phi является то, что большая производительность может проявиться при наличии нескольких потоков OpenMP на ядро.
- Проверьте, можно ли повысить производительность алгоритма факторизации чисел при нечетном размере порции.
- Изучите, какие алгоритмические оптимизации можно выполнить, для повышения производительности кода.
- Рассмотрите, какие программные оптимизации можно выполнить еще с кодом для повышения производительности.
- Более точно подберите границу разделения порции вычислений для сопроцессора и процессора в гибридной схеме.
Svetlana Svetlana