
|
Здравствуйие! Я хочу пройти курс Введение в принципы функционирования и применения современных мультиядерных архитектур (на примере Intel Xeon Phi), в презентации самостоятельной работы №1 указаны логин и пароль для доступ на кластер и выполнения самостоятельных работ, но войти по такой паре логин-пароль не получается. Как предполагается выполнение самосоятельных работ в этом курсе? |
Нижегородский государственный университет им. Н.И.Лобачевского
Опубликован: 30.05.2014 | Доступ: свободный | Студентов: 304 / 36 | Длительность: 11:26:00
Специальности: Программист, Системный архитектор
Самостоятельная работа 3: Оптимизация вычислений в задаче о разложении чисел на простые сомножители. Векторизация и балансировка нагрузки
Параллельная реализация алгоритма
Для реализации параллельного алгоритма воспользуемся директивами OpenMP. Вначале произведем распараллеливание, используя статический планировщик. Затем, попробуем увеличить производительность за счет изменения планировщика.
Распределение вычислений с использованием статического планировщика
Простейший подход к распараллеливанию в задаче разложения чисел из диапазона от 1 до 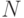 состоит в том, чтобы разделить множество факторизуемых чисел на равные части по числу потоков. На
рис.
8.6 показан пример распределения чисел при создании четырех потоков.
состоит в том, чтобы разделить множество факторизуемых чисел на равные части по числу потоков. На
рис.
8.6 показан пример распределения чисел при создании четырех потоков.
В случае применения директив OpenMP подобного распределения можно добиться, используя статический планировщик, используемый по умолчанию.
Модифицируем код факторизации с учетом выбранного способа распараллеливания.
void factorization()
{
#pragma omp parallel for
for (int i = 1; i < NUM_NUMBERS; i++)
{
int number = i;
int idx = number;
for (int j = 2; j < idx; j++)
{
if (number == 1) break;
int r;
r = number % j;
if (r == 0)
{
number /= j;
divisors[idx].push_back(j);
j--;
}
}
}
}
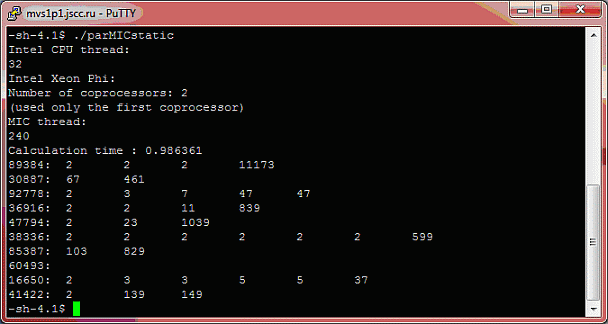
Скомпилируем и выполним код. На рис. 8.7 приведен результат вычислений параллельного кода исполненного на ускорителе Intel Xeon Phi с применение статического планирования.
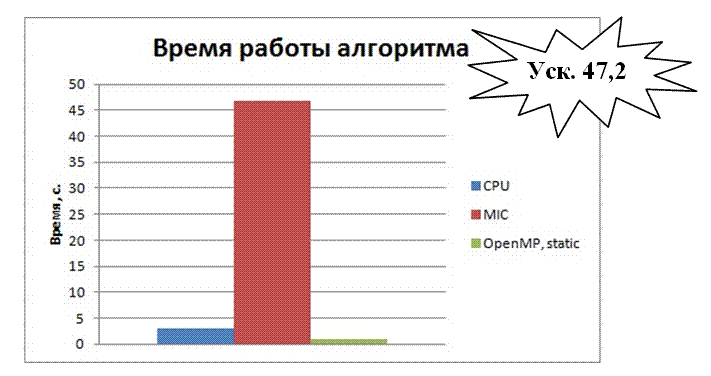
На рис. 8.8 представлен график демонстрирующий ускорение параллельной реализации алгоритма.
Ускорение алгоритма факторизации чисел относительно последовательной версии исполненных на Intel Xeon Phi составило 47,2 раза. Результат можно считать неплохим, но далеким от идеала. Шестьдесят ядер могли обеспечить гораздо лучшее ускорение.
Что помешало большему ускорению?
Ответ простой, вычисления сильно разбалансированы и большое время тратится на синхронизацию потоков. Фактор для чисел первых потоков можно найти гораздо быстрее, чем для последних чисел.
Svetlana Svetlana