
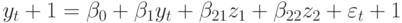
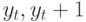
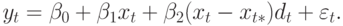
|
В дисциплине "Основы эконометрики" тест 6 дается по теме 7. |
Инспектор
Вы можете этот курс.
Опубликован: 10.09.2016 | Уровень: для всех | Доступ: платный
Лекция 3:
Множественная регрессия
3.11. Линейные регрессионные модели с фиктивными переменными
Выше мы исходили из того, что объясняющие переменные модели могут принимать любые значения в некотором интервале данных. Будем называть их количественными переменными. Однако может возникнуть необходимость включить в модель качественный фактор, принимающий два или несколько фиксированных значений-уровней.
Например, можно предположить, что уровень зарплаты в регионе зависит от уровня образования или пола. Или, проводя количественный прогноз урожайности, включить в уравнение результаты проведенного на предыдущем этапе качественного прогноза (спад, подъем урожая). В моделях, связанных с торговлей и маркетингом, при расчете объемов продаж товара часто фигурирует фактор сезонности (зима, весна, лето, осень). В принципе можно строить отдельные модели для каждого уровня качественного признака, а затем изучать различия между ними. Однако есть подход, позволяющий использовать одно регрессионное уравнение, но с дополнительными фиктивными (структурными, манекенными) переменными.
Часто используют модели с бинарными переменными, принимающими два значения: 0 и 1. Конечно, можно вводить и переменные, принимающие несколько значений, но в этом случае возникают проблемы с интерпретацией коэффициентов модели. Поэтому если есть переменная, принимающая 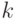 значений, то ее заменяют
значений, то ее заменяют  -й бинарной переменной. Например, если предварительный качественный прогноз урожая может быть сформулирован трояко: 1) спад; 2) практически останется на прежнем уровне; 3) подъем, то в модель вводится две бинарные переменные:
-й бинарной переменной. Например, если предварительный качественный прогноз урожая может быть сформулирован трояко: 1) спад; 2) практически останется на прежнем уровне; 3) подъем, то в модель вводится две бинарные переменные:
Исходя из этого строим модель вида
где
Принимая модель (3.43), мы предполагаем, что средняя сила влияния 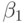 урожая текущего года на урожай будущего года одинакова для всех трех случаев прогноза, а переменные
урожая текущего года на урожай будущего года одинакова для всех трех случаев прогноза, а переменные 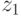 и
и 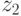 отражают особенности агрометеоситуации в неблагоприятные и благоприятные годы для данной сельскохозяйственной культуры.
отражают особенности агрометеоситуации в неблагоприятные и благоприятные годы для данной сельскохозяйственной культуры.
Фиктивные переменные позволяют строить модели для исследования структурных изменений. При этом мы получаем кусочно-линейные модели.
Пусть  - зависимая переменная, например урожайность сельскохозяйственной культуры,
- зависимая переменная, например урожайность сельскохозяйственной культуры, 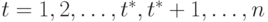 - период наблюдения. Предположим, исследователь считает, что с начала 90-х гг. в сельском хозяйстве произошли структурные изменения и линия регрессии будет отличаться от той, что была при
- период наблюдения. Предположим, исследователь считает, что с начала 90-х гг. в сельском хозяйстве произошли структурные изменения и линия регрессии будет отличаться от той, что была при 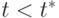 . Чтобы оценить такую модель, введем бинарную переменную
. Чтобы оценить такую модель, введем бинарную переменную 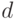 , полагая, что
, полагая, что 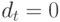 при
при 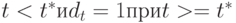 . Пусть
. Пусть 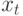 - некоторая объясняющая переменная, например фондовооруженность отрасли.
- некоторая объясняющая переменная, например фондовооруженность отрасли.
Запишем следующее регрессионное уравнение:
Линия регрессии (3.44) имеет коэффициент наклона при  при
при 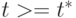 . Отметим, что разрыва при
. Отметим, что разрыва при 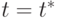 не происходит. Оценка значимости коэффициента
не происходит. Оценка значимости коэффициента 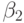 означает проверку нулевой гипотезы
означает проверку нулевой гипотезы 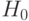 (структурных изменений в сельском хозяйстве не произошло).
(структурных изменений в сельском хозяйстве не произошло).
В случае включения в модель нескольких качественных факторов необходимо следить за тем, чтобы включаемые факторы были линейно независимы, т.е. чтобы в информационной матрице 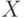 скалярные произведения столбцов, отвечающих за качественные переменные, были равны нулю.
скалярные произведения столбцов, отвечающих за качественные переменные, были равны нулю.
Рассмотрим пример использования фиктивной переменной для повышения качества прогнозов при использовании оперативной информации в период уборки урожая. Оперативные данные наблюдений за ходом уборки представлены в табл. 3.10.
| Год | Оперативные данные урожайности зерновых культур в РФ с указанием даты, ц/га | ||||||
| 1992 | 10 августа 23,8 | 31 августа 21,7 | 14 сентября 20,6 | 28 сентября 20 | 5 октября 19,9 | 12 октября 19,7 | 1 ноября 19,7 |
| 1993 | 9 августа 27,5 | 30 августа 22,8 | 13 сентября 21,4 | 27 сентября 20,4 | 4 октября 19,9 | 11 октября 19,4 | 1 ноября 18,9 |
| 1994 | 8 августа 23,4 | 29 августа 20,9 | 12 сентября 19,1 | 26 сентября 18 | 3 октября 17,5 | 10 октября 17,3 | 31 октября 17,3 |
| 1995 | 7 августа 14,8 | 28 августа 14,5 | 11 сентября 14,5 | 25 сентября 14,6 | 2 октября 14,6 | 9 октября 14,6 | 30 октября 14,6 |
| 1996 | 12 августа 17,5 | 2 сентября 16,7 | 16 сентября 16,6 | 30 сентября 16,5 | 7 октября 16,4 | 14 октября 16,3 | 4 ноября 16,4 |
| 1997 | 11 августа 22,1 | 1 сентября 20,1 | 15 сентября 19,7 | 29 сентября 19,5 | 6 октября 19,4 | 13 октября 19,4 | 3 ноября 19,5 |
| 1998 | 10 августа 16,5 | 31 августа 14,2 | 14 сентября 13,9 | 28 сентября 14 | 6 октября 14 | 12 октября 14,1 | 2 ноября 14,3 |
| 1999 | 9 августа 219,4 | 30 августа 15,7 | 13 сентября 15,1 | 27 сентября 14,9 | 4 октября 15,2 | 11 октября 15,3 | 1 ноября 15,2 |
Прогноз знака колебаний урожайности был составлен по методу "ЗОНТ" на основе данных прошлых лет. Рассмотрим некоторые результаты по построению регрессионных зависимостей для прогноза зерновых в целом по России (табл. 3.11).
Пусть 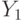 - данные урожайности зерновых культур в целом на 12 сентября;
- данные урожайности зерновых культур в целом на 12 сентября;  - бункерная урожайность на 14-15 октября;
- бункерная урожайность на 14-15 октября; 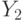 - фиктивная переменная, принимающая значение 1 при прогнозируемом подъеме и значение -1 при прогнозируемом спаде урожайности в текущем году.
- фиктивная переменная, принимающая значение 1 при прогнозируемом подъеме и значение -1 при прогнозируемом спаде урожайности в текущем году.
Модель без учета глобального прогноза
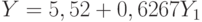
| |||
| Сумма квадратов, объясняемая уравнением регрессии, равна 32,357. Сумма квадратов остатков равна 4,092. Общая сумма квадратов составляет 36,45 | |||
| Год | Исходные данные урожайности | Расчетные значения | Остатки |
| 1992 | 19,7 | 19,12 | 0,56 |
| 1993 | 19,4 | 19,81 | -0,41 |
| 1994 | 17,3 | 18,63 | -1,32 |
| 1995 | 14,6 | 14,62 | -0,02 |
| 1996 | 16,3 | 15,99 | 0,3 |
| 1997 | 19,4 | 18,12 | 1,28 |
| 1998 | 14,1 | 14,43 | -0,32 |
| 1999 | 15,3 | 15,37 | -0,07 |
Сумма модулей ошибок равна 4,29.
Средняя абсолютная ошибка равна 0,53.
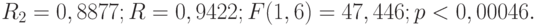 Критерий Стьюдента для свободного члена = 3,27; р = 0,017.Критерий Стьюдента для коэффициента при Критерий Стьюдента для свободного члена = 3,27; р = 0,017.Критерий Стьюдента для коэффициента при 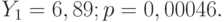
| |||
Так выглядит регрессионная модель без учета глобального прогноза для оперативного прогноза урожайности зерновых в России по данным на 12-14 сентября (см. табл. 3.11).
Теперь перейдем к уравнению, использующему глобальный прогноз урожайности зерновых в России (табл. 3.12).
Модель c учетом глобального прогноза
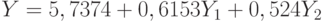
| |||
| Сумма квадратов, объясняемая уравнением регрессии, равна 34,54. Сумма квадратов остатков равна 1,9. Общая сумма квадратов составляет 36,45 | |||
| Год | Исходные данные урожайности | Расчетные значения | Остатки |
| 1992 | 19,7 | 19,61 | 0,09 |
| 1993 | 19,4 | 19,24 | 0,16 |
| 1994 | 17,3 | 18,07 | -0,77 |
| 1995 | 14,6 | 14,13 | 0,47 |
| 1996 | 16,3 | 16,53 | 0,24 |
| 1997 | 19,4 | 18,62 | 0,77 |
| 1998 | 14,1 | 13,95 | 0,15 |
| 1999 | 15,3 | 15,92 | -0,62 |
Сумма модулей ошибок равна 3,27.
Средняя абсолютная ошибка равна 0,41.  Критерий Стьюдента для свободного члена равен 4,523; р = 0,0063. Критерий Стьюдента для коэффициента при Критерий Стьюдента для свободного члена равен 4,523; р = 0,0063. Критерий Стьюдента для коэффициента при 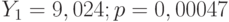 . Критерий Стьюдента для коэффициента при . Критерий Стьюдента для коэффициента при 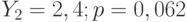
| |||
Результаты расчетов по последней модели, по нашему мнению, практически не могут быть улучшены, так как средняя абсолютная ошибка находится в пределах ошибки сбора данных. Уравнение полностью адекватно исходным данным.
Таковы модели, где фиктивные переменные являются объясняющими переменными, т.е. факторами. Однако может возникнуть необходимость строить модели, в которых качественный признак играет роль результирующей переменной. Подобные задачи возникают при обработке данных социологических опросов, прогнозировании подъемов и спадов (например, урожайностей сельскохозяйственных культур). Кроме того, если результирующий признак является некоторой вероятностью (например, вероятностью наступления некоторого события), то результирующая переменная должна принимать значения хотя и в непрерывном, но в ограниченном отрезком [0; 1] диапазоне значений. Для оценки параметров таких моделей применяются методы логистической регрессии, Logit-, Probit-, Tobit-анализа.
Например, логистическая регрессия используется, когда зависимая переменная - дихотомия, т.е. может принимать только два значения, например 0 и 1. При этом независимые переменные могут быть непрерывными или категориальными переменными.
Пусть зависимая переменная принимает значение 1 при появлении некоторого события и 0, если событие не появилось. При каждом наблюдаемом фиксированном наборе факторов вычисляется
и 0, если событие не появилось. При каждом наблюдаемом фиксированном наборе факторов вычисляется 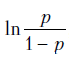 , где
, где 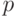 - число появлений единиц, а 1 - - число появлений нулей в наблюдениях.
- число появлений единиц, а 1 - - число появлений нулей в наблюдениях.
Логистическая регрессия имеет много аналогий с обычной МНК-регрессией, хотя для оценки коэффициентов регрессии используется метод максимального правдоподобия, а не метод наименьших квадратов. В отличие от МНК-регрессии логистическая регрессия оценивает нелинейную связь между независимыми переменными и зависимой. При этом не возникает проблем гетероскедастичности, а требования менее строгие. Успех логистической регрессии может быть оценен по таблице числа правильных и неправильных классификаций дихотомической, зависимой переменной. Для проверки адекватности модели можно использовать критерии согласия, например критерий 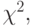 а проверку значимости коэффициентов можно проводить обычным способом.
а проверку значимости коэффициентов можно проводить обычным способом.