| Россия, Звенигород |
Инспектор
Вы можете этот курс.
Опубликован: 10.12.2007 | Уровень: специалист | Доступ: платный
Лекция 16:
Объекты XPCOM
16.3. Передача данных
В этом разделе описывается универсальная инфраструктура, используемая для чтения, записи и передачи содержимого в приложениях платформы Mozilla. В этом разделе также рассматривается обработка фактов RDF, в то время как анализ документов XML обсуждается в разделе "Web-скрипты".
16.3.1. Обработка содержимого: основные концепции
Одна из важнейших функций прикладной части Mozilla – обработка содержимого Web-документов и других данных. Для этого инфраструктура платформы должна обеспечивать получение данных из внешних источников, а также передачу данных между различными составляющими платформы. В основе этой инфраструктуры лежит целый ряд концепций, относящихся к обработке и передаче содержимого и других данных.
В "События" "События" описаны слушатели, наблюдатели и источники событий. Эти инструменты ориентированы на работу с событиями и могут использоваться лишь для передачи очень небольших фрагментов данных. Их возможностей недостаточно для построения систем работы с содержимым, хотя слушатели и наблюдатели могли бы быть полезным дополнением для таких систем. Однако система обработки и передачи содержимого должна быть рассчитана на работу с целыми документами.
Основные концепции, лежащие в основе инфраструктуры Mozilla для работы с содержимым, – файлы, папки, потоки данных, сеансы, каналы, транспорты, а также источники и приемники данных.
Такие понятия, как файл и каталог (папка) широко используются практически во всех операционных системах. Работа с ними описана в разделе "Общие приемы и методы программирования".
Поток данных1Потоки данных (stream), о которых идет речь в этом разделе, следует отличать от потоков вычислений (thread). является самым низким уровнем передачи данных платформы Mozilla. Поток работает на уровне последовательностей байтов, октетов или символов, подобно потокам ввода-вывода C++ и Java или командных оболочек UNIX и DOS. В потоки можно записывать данные или читать из них в зависимости от источника и приемника данных. Mozilla также поддерживает потоки Unicode, в которых элементарной единицей данных является двухбайтный символ Unicode, а не однобайтный символ "расширенной таблицы ASCII", как в обычных потоках данных.
Сеанс представляет собой набор конфигурационной информации о выполняемом процессе, задании или деятельности. Такая конфигурационная информация используется, прежде всего, самим процессом. Однако при этом сеанс не является самим процессом, хотя его можно рассматривать в качестве контроллера последнего.
Примером сеанса может служить передача файла по FTP. Доменное имя FTP-сервера, имя пользователя, пароль, а также сокеты, через которые установлено соединение, представляют собой часть информации сеанса FTP. При этом фактическая передача данных выполняется другим модулем или компонентом, в то время как объект сеанса лишь хранит необходимую информацию. Понятие сеанса имеет смысл и за пределами сетевого взаимодействия – так, в Mozilla специальный объект сеанса соответствует перетаскиванию при помощи мыши. Такие объекты используются для решения различных задач платформы Mozilla.
Канал передачи данных2Channel, в отличие от канала как средства взаимодействия между процессами (pipe). представляет собой элемент архитектуры платформы, который выполняет фактическую передачу данных. В Mozilla каналы используются, как правило, для получения документов, имеющих URL. Иногда каналы предоставляют дополнительную функциональность, но их основное назначение просто – обеспечить передачу данных от какого-либо источника, например от удаленного Web-сервера. При этом может выполняться физическая передача данных из одного места в другое или "логическая" передача – преобразование данных из одной формы в другую. При этом канал управляет процессом передачи, в то время как непосредственное чтение и запись, как правило, выполняются на уровне потока данных.
Транспорт представляет собой элемент платформы, отвечающий за сетевое взаимодействие с использованием одного или нескольких протоколов. Так, если канал обеспечивает передачу данных на высоком уровне (получение документа, имеющего указанный URL), то на уровне транспорта реализована поддержка конкретных протоколов, например SMTP или TCP/IP.
Источники и приемники рассматриваются в следующем разделе.
16.3.1.1. Источники и приемники
Концепция источников и приемников занимает важное место в архитектуре Mozilla. Обычно они используются для обработки XML- документов. Источники и приемники образуют один из самых высоких уровней обработки информации в составе платформы и, как правило, выполняют преобразования, зависящие от типа содержимого.
Источники и приемники (стоки) представляют собой универсальную концепцию, широко используемую в науке и инженерном деле. Многие разработчики впервые встречаются с ними, знакомясь с диаграммами потоков данных. На этих диаграммах, как для обычной кухонной раковины, подразумевается, что поток данных (воды) начинается у источника и заканчивается у приемника (стока). Это, однако, вопрос точки зрения, и, в зависимости от вашего места в этой схеме, ее можно "вывернуть наизнанку".
Действительно, если раковина существует и работает, вода вытекает из крана (источник) и попадает в сток (приемник). Однако ситуация меняется, если раковины не существует, и вам самим нужно доставить воду из крана в сточное отверстие, находящееся на некотором расстоянии. Первое, что вам нужно сделать, – набрать воду из-под крана в какую-то промежуточную емкость. При этом емкость оказывается приемником. В конце концов, вам понадобится вылить воду в сточное отверстие, и в этом случае та же емкость окажется источником. Таким образом, в этом примере последовательность приемника и источника перевернута.
Именно такая ситуация характерна для работы с Mozilla. Для того чтобы загрузить содержимое документа в память, используется объект-приемник. Затем это содержимое или его часть можно извлечь при помощи источника данных.
Независимо от того, в каком порядке используются приемник и источник в каждом конкретном случае, источник всегда является производителем, а приемник – потребителем. С точки зрения разработчика приложения, если содержимое документа еще не находится в памяти платформы Mozilla (например, документ хранится в файле на диске), сначала необходимо создать приемник, чтобы загрузить это содержимое. На следующем этапе создается источник, с помощью которого различные части приложения могут получить доступ к загруженному содержимому. В некоторых случаях документ загружается в память автоматически, и тогда разработчику приходится создавать только источник.
В этой схеме есть одна сложность – при работе с документами в них могут вноситься изменения. Как правило, приемники используются для первоначальной загрузки содержимого в память и, таким образом, обеспечивают лишь одностороннюю обработку данных. Это означает, что ответственность за управление изменениями в документе лежит на источнике. Таким образом, источники не только обеспечивают доступ к содержимому документа, но и часто способны изменять его.
Mozilla не предоставляет универсальных интерфейсов для работы с источниками и приемниками. Существуют лишь специализированные интерфейсы для работы с конкретными видами данных. Архитектура платформы позволяет нескольким приемникам или источникам одновременно работать с одним документом, находящимся в памяти.
16.3.1.2. Специализированные источники и приемники
Источники и приемники служат для обработки содержимого на высоком уровне. Источники и приемники, входящие в состав платформы Mozilla, предназначены для различных целей.
Источники данных используются для обработки содержимого RDF. Вместо того чтобы работать с документом на уровне отдельных тегов или объектов DOM, источники данных работают на уровне фактов RDF. Приемников данных RDF не существует. Источники данных широко используются в системе шаблонов XUL, причем как с источниками, так и с шаблонами можно работать из скриптов. Источники фактов (источники данных RDF) также позволяют добавлять, изменять и удалять факты, содержащиеся в документе RDF, загруженном в память. Некоторые источники данных Mozilla (так называемые внутренние источники данных ) получают свое содержимое непосредственно от платформы, а не из внешних документов RDF. Исходная информация для таких источников содержится во внутренних структурах данных платформы или, например, в файле закладок пользователя.
Синтаксический анализатор (parser) представляет собой разновидность приемника. Он получает поток содержимого, как правило, из какого-либо документа, и преобразует его в структуру данных. Примером может служить анализатор, который получает документ XML и создает на его основе дерево DOM. В состав Mozilla входят синтаксические анализаторы для всех известных платформе приложений XML.
Сериализатор (serializer) является источником, обратным синтаксическому анализатору. Он преобразует структуру данных в неструктурированный поток содержимого, чаще всего – в документ XML.
16.3.1.3. Архитектура обработки содержимого.
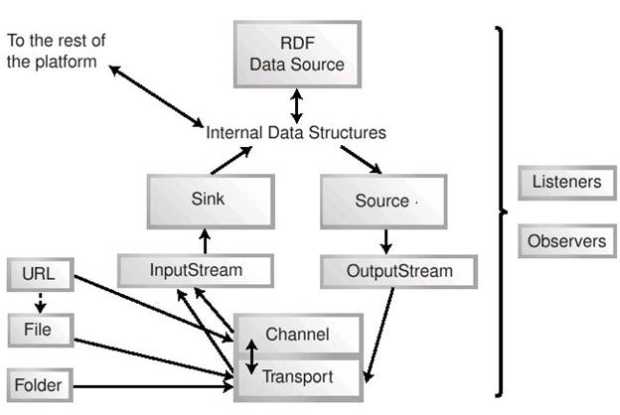
Различные инструменты обработки данных, описанные в этом разделе, можно неофициально рассматривать как систему уровней или слоев, хотя эта система организована не так строго, как, например, стек сетевых протоколов. Уровни обработки данных показаны на рис.16.1.
На рисунке приведена принципиальная схема, которая не является точным отображением объектной модели платформы, хотя и довольно близко соответствует некоторым отношениям между объектами. Мы видим, что каналы и транспорты тесно связаны между собой, однако не настолько тесно, чтобы их нельзя было использовать независимо друг от друга. Потоки ввода и вывода делают обрабатываемые данные или содержимое доступными для остальной платформы. Приемники и источники – синтаксические анализаторы, сериализаторы и другие средства преобразования – играют важную роль в общей системе обработки данных. Источники данных RDF занимают в системе особое место – они работают на очень высоком уровне и имеют дело с содержимым, которое уже разбито на факты. Все эти инструменты поддерживают работу с наблюдателями и слушателями. Файлы и URL используются для организации доступа к данным на низких уровнях обработки.
На схеме не показаны многочисленные интерфейсы, представляющие собой конкретные реализации изображенных элементов, а также конкретные способы взаимодействия с остальной платформой.