
|
Прошел экстерном экзамен по курсу перепордготовки "Информационная безопасность". Хочу получить диплом, но не вижу где оплатить? Ну и соответственно , как с получением бумажного документа? |
Инспектор
Вы можете этот курс.
Опубликован: 10.10.2007 | Уровень: специалист | Доступ: платный
Лекция 5:
Подписные листы (LISTSERV) и поисковые системы
Современные поисковые системы
Развитие Интернет начиналось как средство общения и удаленного доступа (электронная почта, telnet, FTP). Но постепенно эта сеть превратилась в средство массовой информации, отличающееся тем, что операторы сети и сами могут быть источниками информации, и определяют, в свою очередь, то, какую информацию они хотят получить.
Среди первых поисковых систем были archie, gopher и wais. Эти относительно простые системы казались тогда чудом. Но в процессе использования этих систем стали явными их малая мощность и определенные врожденные недостатки: ограниченность зоны поиска и отсутствие управления этим процессом. Поиск проводился по ограниченному списку серверов, и никогда не было известно, насколько исчерпывающую информацию получил клиент.
Первые WWW-системы работали в режиме меню (система Mosaic появилась несколько позже), и обход дерева поиска производился вручную. Структура гиперсвязей могла иметь циклические пути, как, например, на рис. 5.1. Число входящих и исходящих гиперсвязей для любого узла дерева может быть произвольным.
Гиперсвязь, помеченная буквой А, может явиться причиной образования цикла при обходе дерева. Исключить такие связи невозможно, так как они носят принципиальный смысловой характер. По этой причине любая автоматизированная программа обхода дерева связей должна учитывать такую возможность и предотвращать циклы обхода.
Задача непроста даже в случае поиска нужного текста в пределах одного достаточно большого по емкости диска, когда вы заранее не знаете или не помните, в каком субкаталоге или в каком файле содержится искомый текст. Для облегчения ручного поиска на серверах FTP в начале каждого субкаталога размещается индексный файл.
Для решения этой задачи в большинстве операционных систем имеются специальные утилиты (например, grep для UNIX). Но даже они требуют достаточно много времени, если, например, дисковое пространство лежит в пределах нескольких десятков гигабайт или более, а каталог весьма разветвлен. В полнотекстных базах данных для ускорения поиска используется индексация по совокупности слов, составляющих текст. Хотя индексация также является весьма времяемкой процедурой, но производить ее, как правило, приходится только один раз. Проблема здесь заключается в том, что объем индексного файла оказывается сравним (а в некоторых случаях превосходит) с исходным индексируемым файлом. Первоначально каждому документу ставился в соответствие индексный файл, в настоящее время индекс готовится для тематической группы документов или для поисковой системы в целом. Такая схема индексации экономит место в памяти и ускоряет поиск. Для документов очень большого размера может использоваться отдельный индекс, а в поисковой системе — иерархический набор индексов. Индексированием называетсяпроцесс перевода с естественного языка на информационно-поисковый. В частности, под индексированием понимается отнесение документа, в зависимости от содержимого, к определенной рубрике некоторой классификации. Индексирование можно свести к проблеме распознавания образов. Классификация определяет разбиение пространства предметных областей на непересекающиеся классы. Каждый класс характеризуется набором признаков и специфических для него терминов (ключевых слов), выражающих основные понятия и отношения между ними.
Слова в любом тексте в информационном отношении весьма неравнозначны. И дело не только в том, что текст содержит много вспомогательных элементов предлогов, местоимений или артиклей (например, в англоязычных текстах).
Для сокращения объема индексных регистров и ускорения самого процесса индексации вводятся так называемые стоп-листы. В эти стоп-листы вносятся слова, которые не несут смысловой нагрузки (например, предлоги или некоторые вводные слова).
Но при использовании стоп-листов необходима определенная осторожность. Например, занеся в стоп-лист, неопределенный артикль английского языка "а", можно заблокировать нахождение ссылки на "витамин А".
Немалое влияние оказывает изменяемость слов из-за склонения или спряжения. Последнее делает необходимым лингвистический разбор текста перед индексацией. Хорошо известно, что смысл слова может меняться в зависимости от контекста, и это также усложняет проблему поиска. Практически все современные информационные системы для создания и обновления индексных файлов используют специальные программные средства.
Существующие поисковые системы успешно работают с HTML-документами, с обычными ASCII-текстами и новостями usenet. Трудности возникают для текстов Winword и даже для текстов Postscript. Связано это с тем, что такие тексты содержат большое количество управляющих символов и слов. Трудно (практически невозможно) осуществлять поиск для текстов, которые представлены в графической форме, здесь следует ждать успеха от широкого внедрения MPEG-7. К сожалению, к числу графических объектов очень часто относятся и математические формулы, которые в HTML имеют формат рисунков (это уже недостаток самого языка). Так что можно без преувеличения сказать, что в этой крайне важной области, уже имеющей немалые успехи, мы все же находимся лишь в начале пути. Ведь море информации, уже загруженной в Интернет, требует эффективных средств навигации. От того, что информации в сети много, мало толку, если мы не можем быстро найти то, что нужно. И в этом, я полагаю, убедились многие читатели, получив на свой запрос список из нескольких тысяч документов. Практически это эквивалентно списку нулевой длины, так как заказчик в обоих случая не получает того, что хотел.
Встроенная в язык HTML метка <meta> создана для предоставления информации о содержании документа для поисковых роботов, браузеров и других приложений. Структура метки: <meta http-equiv=response content=description name=description URL=url>. Параметр http-equiv=response ставит в соответствие элементу заголовок HTTP ответа. Значение параметра http-equiv интерпретируется приложением, обрабатывающим HTML документ. Значение параметра content определяется значением, содержащимся в http-equiv.
Современная поисковая система содержит в себе несколько подсистем.
- Web-агенты. Осуществляют поиск серверов, извлекают оттуда документы и передают их системе обработки.
- Система обработки. Индексирует полученные документы, используя синтаксический разбор и стоп-листы (где, помимо прочего, содержатся все стандартные операторы и атрибуты HTML).
- Система поиска. Воспринимает запрос от системы обслуживания, осуществляет поиск в индексных файлах, формирует список найденных ссылок на документы.
- Система обслуживания. Принимает запросы поиска от клиентов, преобразует их, направляет системе поиска, работающей с индексными файлами, возвращает результат поиска клиенту. Система в некоторых случаях может осуществлять поиск в пределах списка найденных ссылок на основе уточняющего запроса клиента (например, recall в системе altavista). Задание системе обслуживания передается WEB-клиентом в виде строки, присоединенной к URL, например, http://altavista.com/cgibin/query?pg=q&what=web&fmt=/&q=plug+%26+play, где в поле поиска было записано plug & play)
Следует иметь в виду, что работа web-агентов и системы поиска напрямую не связана друг с другом. WEB-агенты (роботы) работают постоянно, вне зависимости от поступающих запросов. Их задача — выявление новых информационных серверов, новых документов или новых версий уже существующих документов. Под документом здесь подразумевается HTML-, текстовый или nntp-документ. WEB-агенты имеют некоторый базовый список зарегистрированных серверов, с которых начинается просмотр. Этот список постоянно расширяется за счет анализа гиперссылок. При просмотре документов очередного сервера выявляются URL и по ним производится дополнительный поиск. Таким образом, WEB-агенты осуществляют обход дерева гиперссылок. Каждый новый или обновленный документ передается системе обработки. Роботы могут в качестве побочного продукта выявлять разорванные гиперсвязи, способствовать построению зеркальных серверов.
Обычно работа роботов приветствуется, ведь благодаря им сервер может обрести новых клиентов, ради которых он и создавался. Но при определенных обстоятельствах может возникнуть желание ограничить неконтролируемый доступ роботов к серверам узла. Одной из причин может быть постоянное обновление информации каких-то серверов, другой причиной может стать то, что для доставки документов используются скрипты CGI. Динамические вариации документа могут привести к бесконечному разрастанию индекса. Для управления роботами имеются разные возможности. Можно закрыть определенные каталоги или серверы с помощью специальной фильтрации по IP-адресам, можно потребовать идентификации с помощью имени и пароля, можно, наконец, спрятать часть сети за Firewall. Но существует другой, достаточно гибкий способ управления поведением роботов. Этот метод предполагает, что робот следует некоторым неформальным правилам поведения. Большинство из этих правил важны для самого робота (например, обхождение так называемых "черных дыр", где он может застрять), часть имеет нейтральный характер (игнорирование каталогов, где лежит информация, имеющая исключительно локальный характер, или страниц, которые находятся в состоянии формирования), некоторые запреты призваны ограничить загрузку локального сервера.
Когда "воспитанный" робот заходит в ЭВМ, он проверяет наличие в корневом каталоге файла robots.txt. Обнаружив его, робот копирует этот файл и следует изложенным в нем рекомендациям. Содержимое файла robots.txt в простейшем случае может выглядеть, например, следующим образом.
# robots.txt for http://store.in.ru user-agent: * # * соответствует любому имени робота disallow: /cgi-bin/ # не допускает робот в каталог cgi-bin disallow: /tmp/ # не следует индексировать временные файлы disallow: /private/ # не следует заходить в частные каталоги
Файл содержит обычный текст, который легко редактировать, после символа # следуют комментарии. Допускается две директивы. user-agent: — определяет имя робота, к которому обращены следующие далее инструкции; если не имеется в виду какой-то конкретный робот и инструкции должны выполняться всеми роботами, в поле параметра записывается символ *. disallow — указывает имя каталога, посещение которого роботу запрещено. Нужно учитывать, что не все роботы, как и люди, следуют правилам, и не слишком на это полагаться.
Автор исходного текста может заметно помочь поисковой системе, умело выбрав заголовок и подзаголовок, профессионально пользуясь терминологией и перечислив ключевые слова в подзаголовках. Исследования показали, что автор (а иногда и просто посторонний эксперт) справляется с этой задачей быстрее и лучше, чем вычислительная машина. Но такое пожелание вряд ли станет руководством к действию для всех без исключения авторов. Ведь многие из них, давая своему тексту образный заголовок, рассчитывают (и не без успеха) привлечь внимание читателей. Но машинные системы поиска не воспринимают (во всяком случае, пока) образного языка. Например, в одном лабораторном проекте, который был разработан для лексического разбора выражений, состоящих из существительных с определяющим прилагательным, и по своей теме связанных с компьютерной тематикой, система была не способна определить во фразе "иерархическая компьютерная архитектура" то, что прилагательное "иерархическая" относится к слову "архитектура", а не к "компьютерная" (Vickery & Vickery 1992; здесь подразумевается английский текст, где часто трудно отличить прилагательное от существительного). То есть, система была не способна отличать образное использование слова в выражении от его буквального значения.
В свою очередь, специалисты, занятые в области поисковых и информационных систем, способны заметно облегчить работу авторам, снабдив их необходимыми современными тезаурусами, где перечисляются нормативные значения базовых терминов в той или иной научно-технической области, а также устойчивых словосочетаний. Параллельно могут быть решены проблемы синонимов.
В настоящее время, несмотря на впечатляющий прогресс в области вычислительной техники, степень соответствия документа определенным критериям запроса надежнее всего может определить человек. Но темп появления электронных документов в сети достигает ошеломляющего уровня (частично это связано с преобразованием в электронную форму старых документов и книг методом сканирования). Написание рефератов для последующего их использования поисковыми системами — достаточно изнурительное занятие, требующее к тому же весьма высокой профессиональной подготовки. Именно по этой причине уже в течение некоторого времени предпринимаются попытки перепоручить этот процесс ЭВМ.
Для этого нужно выработать критерии оценки важности отдельных слов и фраз, составляющих текст. Оценку значимости предложений выработал Г.Лун. Он предложил оценивать предложения текста в соответствии с параметром:
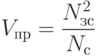
где Vпр — значимость предложения; Nзс — число значимых слов в предложении; а Nc — полное число слов в предложении. Используя этот критерий, из любого документа можно отобрать некоторое число предложений. Понятно, что они не будут составлять членораздельного текста. Нужно учитывать также, что "значимые слова" должны браться из тематического тезауруса или отбираться экспертом. По этой причине методика может лишь помочь человеку, а не заменить его (во всяком случае, на современном этапе развития вычислительной техники).
Автоматическая система выявления ключевых слов обычно использует статистический частотный анализ (методика В. Пурто). Пусть f — частота, с которой встречаются различные слова в тексте, а u — относительное значение полезности (важности).
Тогда зависимость f(u) апроксимируется формулой 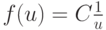 , то есть произведение частоты встречи слов и их полезности является константой. В теории автоматического анализа документов данная гипотеза используется для вывода следствия о существовании двух пороговых значений частот. Слова с частотой менее нижнего порога считаются слишком редкими, а с частотой, превосходящей верхний порог, — общими, не несущими смысловой нагрузки. Слова с частотой, находящейся посередине между данными порогами, в наибольшей степени характеризуют содержимое данного конкретного документа [Г. Лун; 2]. К сожалению, выбор порогов — процедура достаточно субъективная. Ключевые слова, выявляемые программно, ранжируются согласно частоте их использования. Замечено, что определенное значение имеет не только частота применения слова в конкретном документе, но и число документов, в которых это слово встречается.
В работах Спарка Джонса экспериментально показано, что если N — число документов и n — число документов, в которых встречается данный индексный термин (ключевое слово), то вычисление его веса по формуле:
, то есть произведение частоты встречи слов и их полезности является константой. В теории автоматического анализа документов данная гипотеза используется для вывода следствия о существовании двух пороговых значений частот. Слова с частотой менее нижнего порога считаются слишком редкими, а с частотой, превосходящей верхний порог, — общими, не несущими смысловой нагрузки. Слова с частотой, находящейся посередине между данными порогами, в наибольшей степени характеризуют содержимое данного конкретного документа [Г. Лун; 2]. К сожалению, выбор порогов — процедура достаточно субъективная. Ключевые слова, выявляемые программно, ранжируются согласно частоте их использования. Замечено, что определенное значение имеет не только частота применения слова в конкретном документе, но и число документов, в которых это слово встречается.
В работах Спарка Джонса экспериментально показано, что если N — число документов и n — число документов, в которых встречается данный индексный термин (ключевое слово), то вычисление его веса по формуле:
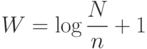
приводит к более эффективным результатам поиска, чем вообще без использования оценки значимости индексного термина.
Одним из известных путей облегчения процедуры поиска является группирование документов по определенной, достаточно узкой тематике в кластеры. В этом случае запрос с ключевым словом, фигурирующем в заголовке кластера, приведет к тому, что все документы кластера будут включены в список найденных. Кластерный метод наряду с очевидными преимуществами (прежде всего заметное ускорение поиска) имеет столь же явные недостатки. Документы, сгруппированные по одному признаку, могут быть случайно включены в перечень документов, отвечающих запросу, по той причине, что одно из ключевых слов кластера соответствует запросу. В результате в перечне найденных документов вы можете с удивлением обнаружить тексты, не имеющие никакого отношения к интересующей вас теме.
Некоторые поисковые системы предоставляют возможность поиска документов, где определенные ключевые слова находятся на определенном расстоянии друг от друга (proximity search).
Наиболее эффективным инструментом при поиске можно считать возможность использования в запросе булевых логических операторов AND, OR и NOT. Объединение ключевых слов с помощью логических операторов может сузить или расширить зону поиска.
Проблема соответствия ( релевантности ) документа определенному запросу совсем не проста.
Индексные файлы, содержащие информацию о WEB-сайтах, занимают около 200 Гигабайт дискового пространства (данные шестилетней давности), поиск по содержимому которых производится за время, меньшее одной секунды (на самом деле, реальный поиск осуществялется в объеме, более чем в десять раз меньшем).
Пример широко известной несколько лет назад поисковой системы alta vista, где задействовано большое число суперЭВМ, показывает, что дальнейшее движение по такому пути вряд ли можно считать разумным, хотя прогресс в вычислительной технике может и опровергнуть это утверждение. Тем не менее, даже в случае фантастических достижений в области создания еще более мощных ЭВМ, можно утверждать, что распределенные поисковые системы могут оказаться эффективнее. Во-первых, местный администратор быстрее может найти общий язык с авторами текстов, которые могут точнее выбрать набор ключевых слов. Во-вторых, распределенная система способна распараллелить обработку одного и того же информационного запроса. Распределенная система памяти и процессоров может, в конце концов, стать более адекватной потокам запросов к информации, содержащейся на том или ином сервере. Способствовать этому может также создание тематических серверов поиска, где концентрируется информация по относительно узкой области знаний. Для таких серверов возможен отбор документов экспертами, они же могут определить списки ключевых слов для многих документов. Здесь возможна автоматическая предварительная процедура фильтрации документов по наличию определенного набора ключевых слов. Способствует этому и существование тематических журналов (в том числе электронных), где сконцентрированы статьи по определенной тематике.
Евгений Виноградов
Илья Сидоркин
|
Добрый день! Подскажите пожалуйста как и когда получить диплом, после сдичи и оплаты????? |