
|
Добрый день! Подскажите пожалуйста как и когда получить диплом, после сдичи и оплаты????? |
Инспектор
Вы можете этот курс.
Опубликован: 10.10.2007 | Уровень: специалист | Доступ: платный
Лекция 5:
Подписные листы (LISTSERV) и поисковые системы
Теперь рассмотрим коэффициенты Сi функции G(x) с использованием следующей терминологии:
| Релевантные документы | Нерелевантные документы | Общее количество документов | |
|---|---|---|---|
| xi=1 | r | n-R | n |
| xi=0 | R-r | N-n-R-r | N-n |
| Всего | R | N-R | N |
N — полное число документов в системе
R — число релевантных документов
r — число релевантных документов, выданных в ответ на запрос
n — полное число документов, выданных в ответ на запрос
Таблица приводит результаты запроса, направленного системе поиска. Представленная таблица должна существовать для каждого из индексных терминов.
Если мы обладаем всей информацией о релевантных и нерелевантных документах в коллекции, то применимы следующие оценки:
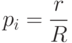
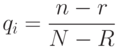
Тогда функция g(x) может быть переписана в виде
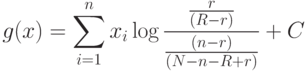
Коэффициент при xi показывает, до какой степени можно провести дискриминацию по i -тому термину в рассматриваемой коллекции документов. В действительности N может рассматриваться как полное количество документов не только во всей коллекции, но и в некотором ее подмножестве.
Все приведенные формулы были выведены при условии, что индексные термины являются статистически независимыми. В общем случае это, конечно, не так. В теории вероятностного поиска моделируется зависимость между различными индексными формулами, в связи с чем вид функции G(x) несколько меняется.
Многие системы поиска информации основаны на словарях и тезаурусах для корректировки запросов и представления индексируемых документов, чтобы увеличить шансы найти необходимый документ. На практике, большинство словарей составляется вручную. Словари создаются с помощью одного из двух основных способов:
- связываются слова, описывающие одну и ту же тему;
- связываются слова, описывающие похожие темы.
В первом случае связываются слова, являющиеся взаимозаменяемыми, то есть, в словарях и тезаурусах они принадлежат одному и тому же классу. Иначе говоря, можно выбрать по одному слову из каждого класса, и совокупность выбранных слов может быть использована для создания контролируемого словаря. Выбирая слова из созданного контролируемого словаря, можно проводить индексацию документов или формировать поисковые запросы.
Во втором случае для создания тезауруса используются семантические связи между словами для построения, например, иерархической структуры связей. Создание такого типа словарей является достаточно сложным и трудоемким процессом.
Однако были предложены способы и для автоматического создания словарей. В то время как созданные вручную словари опираются на семантику (т.е. распознают синонимы, являются более обширными, используют более тонкие взаимосвязи), автоматически созданные тезаурусы, в основном, базируются на синтаксическом и статистическом анализе. Но, так как использование синтаксиса не приводит к серьезному увеличению эффективности работы систем, то значительно большее внимание уделяется статистическим методам.
Основное допущение, используемое для автоматического создания классов ключевых слов, заключается в следующем: если ключевые слова a и b могут быть взаимозаменяемы в том смысле, что мы готовы принять документ, содержащий ключевое слово b вместо ключевого слова a и наоборот, то данное обстоятельство верно из-за того, что слова a и b имеют одинаковое значение или ссылаются на одинаковые темы.
Основываясь на описанном принципе, нетрудно видеть, что создание классификации слов может быть автоматизировано. Можно определить два основных приближения для использования классификации ключевых слов:
- производить замену каждого из ключевых слов, встречающегося в представлении документа или запроса, названием класса, которому оно принадлежит;
- заменять каждое из встреченных ключевых слов всеми словами, входящими в класс, которому принадлежит рассматриваемое ключевое слово.
Для простейшей поисковой стратегии, использующей только что описанные дескрипторы, независимо от того, являются ли они ключевыми словами или названиями классов, созданных на основе группы ключевых слов, "расширенное" представление документов и запросов с помощью любого из вышеописанных способов может существенно повысить число соответствий между документами и запросами и, следовательно, увеличить значение параметра recall. Правда, последнее обстоятельство не является определяющим, так как значение имеет только совокупность параметров (recall, precision), а одно лишь увеличение параметра recall может привести только к увеличению объема выдаваемых в ответ на запрос различных документов.
В отчетах об экспериментальных работах по использованию автоматической классификации ключевых слов, проведенных ранее Спарком Джонсом, сообщается, что использование автоматической классификации приводит к увеличению эффективности работы системы по сравнению с системой, использующей неклассифицированные ключевые слова.
Работа Минкера и др. не подтвердила выводы Спарка Джонса и фактически показала, что в некоторых случаях применение классификации ключевых слов приводит к существенному ухудшению работы системы в целом. Д. Сальтон в своем отзыве о работе Минкера определил, что целесообразность использования классификации ключевых слов для улучшения эффективности работы поисковых систем еще полностью не определена и является объектом дальнейших экспериментальных исследований. Действительно, при работе в Интернет с поисковыми системами, построенными на классификации ключевых слов, (такими, как lycos и excite ), заметно существенное увеличение документов, не представляющих собой ничего общего с запросом, но, тем не менее, имеющих довольно высокий ранг и, следовательно, по мнению поисковой системы, наиболее точно соответствующих заданному запросу.
Для дальнейшего увеличения эффективности системы используется так называемая кластеризация документов.
Существуют две основные области применения методов классификации в системах поиска и локализации информации. Это — кластеризация (классификация) ключевых слов и кластеризация документов.
Под кластеризацией документов понимается создание таких групп документов, что документы, принадлежащие одной группе, оказываются, в некоторой степени, связанными друг с другом. Другими словами, документы принадлежат одной группе потому, что ожидается, что эти документы будут находиться вместе в результате обработки запроса. Логическая организация документов достигается, в основном, двумя следующими способами.
Первый — путем непосредственной классификации документов, и второй — посредством промежуточного вычисления некоторой величины соответствия между различными документами.
Было теоретически доказано, что первый метод является очень сложным для практической реализации, так что любые экспериментальные результаты не могут считаться достаточно надежными. Второй способ классификации заслуживает подробного внимания и, по сути, может считаться единственным реальным подходом к решению проблемы.
На практике почти невозможно сопоставить каждый из документов каждому из запросов из-за слишком больших затрат машинного времени на проведение таких операций. Было предложено много различных способов для уменьшения количества необходимых для выполнения запроса операций сравнения. Наиболее многообещающей была идея использовать группы взаимосвязанных документов, применяя процедуры автоматического определения соответствия документов. Проводя сравнения запроса всего лишь с одним документом, являющимся представителем группы (заранее определенным), и таким образом определяя группу документов, в которой и происходит дальнейший поиск, мы существенно уменьшаем затрачиваемое на обработку запроса машинное время.
Реальный прорыв в совершенствовании систем поиска может дать создание программ, способных осуществлять анализ контекста. Этот анализ можно выполнять автоматически или в диалоговом режиме (клиенту задаются вопросы, которые позволяют уточнить контекст запроса).
Илья Сидоркин
Наталья Шульга
|
Курс "информационная безопасность" . Можно ли на него записаться на ПЕРЕПОДГОТОВКУ по данному курсу? Выдается ли диплом в бумажном варианте и высылается ли он по почте? |