|
С помощью обобщенного алгоритма Евклида найдите числа х и у, удовлетворяющие уравнению 30х +12y = НОД(30,12). х=1, у=-2, НОД = 6. Где ошибка? |
Тульский государственный университет
Опубликован: 19.09.2011 | Доступ: свободный | Студентов: 8424 / 2885 | Оценка: 4.38 / 4.03 | Длительность: 18:45:00
Тема: Безопасность
Специальности: Специалист по безопасности
Лекция 3:
Простейшие методы шифрования с закрытым ключом
Методы замены
Методы шифрования заменой (подстановкой) основаны на том, что символы исходного текста, обычно разделенные на блоки и записанные в одном алфавите, заменяются одним или несколькими символами другого алфавита в соответствии с принятым правилом преобразования.
Одноалфавитная замена
Одним из важных подклассов методов замены являются одноалфавитные (или моноалфавитные) подстановки, в которых устанавливается однозначное соответствие между каждым знаком ai исходного алфавита сообщений A и соответствующим знаком ei зашифрованного текста E. Одноалфавитная подстановка иногда называется также простой заменой, так как является самым простым шифром замены.
Примером одноалфавитной замены является шифр Цезаря, рассмотренный ранее. В рассмотренном в "Основные понятия криптографии" примере первая строка является исходным алфавитом, вторая (с циклическим сдвигом на k влево) – вектором замен.
В общем случае при одноалфавитной подстановке происходит однозначная замена исходных символов их эквивалентами из вектора замен (или таблицы замен). При таком методе шифрования ключом является используемая таблица замен.
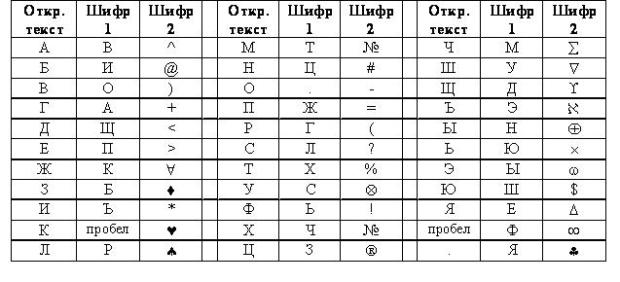
Подстановка может быть задана с помощью таблицы, например, как показано на рис. 2.3.
В таблице на рис. 2.3 на самом деле объединены сразу две таблицы. Одна (шифр 1) определяет замену русских букв исходного текста на другие русские буквы, а вторая (шифр 2) – замену букв на специальные символы. Исходным алфавитом для обоих шифров будут заглавные русские буквы (за исключением букв "Ё" и "Й"), пробел и точка.
Зашифрованное сообщение с использованием любого шифра моноалфавитной подстановки получается следующим образом. Берется очередной знак из исходного сообщения. Определяется его позиция в столбце "Откр. текст" таблицы замен. В зашифрованное сообщение вставляется шифрованный символ из этой же строки таблицы замен.
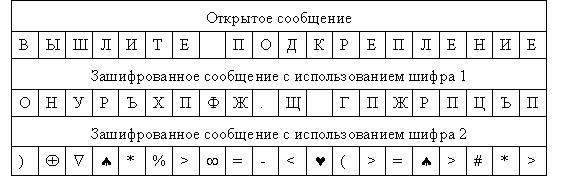
Попробуем зашифровать сообщение "ВЫШЛИТЕ ПОДКРЕПЛЕНИЕ" c использованием этих двух шифров ( рис. 2.4). Для этого берем первую букву исходного сообщения "В". В таблице на рис. 2.3 в столбце "Шифр 1" находим для буквы "В" заменяемый символ. Это будет буква "О". Записываем букву "О" под буквой "В". Затем рассматриваем второй символ исходного сообщения – букву "Ы". Находим эту букву в столбце "Откр. текст" и из столбца "Шифр 1" берем букву, стоящую на той же строке, что и буква "Ы". Таким образом получаем второй символ зашифрованного сообщения – букву "Н". Продолжая действовать аналогично, зашифровываем все исходное сообщение ( рис. 2.4).
Полученный таким образом текст имеет сравнительно низкий уровень защиты, так как исходный и зашифрованный тексты имеют одинаковые статистические закономерности. При этом не имеет значения, какие символы использованы для замены – перемешанные символы исходного алфавита или таинственно выглядящие знаки.
Зашифрованное сообщение может быть вскрыто путем так называемого частотного криптоанализа. Для этого могут быть использованы некоторые статистические данные языка, на котором написано сообщение.
Известно, что в текстах на русском языке наиболее часто встречаются символы О, И. Немного реже встречаются буквы Е, А. Из согласных самые частые символы Т, Н, Р, С. В распоряжении криптоаналитиков имеются специальные таблицы частот встречаемости символов для текстов разных типов – научных, художественных и т.д.
Криптоаналитик внимательно изучает полученную криптограмму, подсчитывая при этом, какие символы сколько раз встретились. Вначале наиболее часто встречаемые знаки зашифрованного сообщения заменяются, например, буквами О. Далее производится попытка определить места для букв И, Е, А. Затем подставляются наиболее часто встречаемые согласные. На каждом этапе оценивается возможность "сочетания" тех или иных букв. Например, в русских словах трудно найти четыре подряд гласные буквы, слова в русском языке не начинаются с буквы Ы и т.д. На самом деле для каждого естественного языка (русского, английского и т.д.) существует множество закономерностей, которые помогают раскрыть специалисту зашифрованные противником сообщения.
Возможность однозначного криптоанализа напрямую зависит от длины перехваченного сообщения. Посмотрим, с чем это связано. Пусть, например, в руки криптоаналитиков попало зашифрованное с помощью некоторого шифра одноалфавитной замены сообщение:
ТНФЖ.ИПЩЪРЪ
Это сообщение состоит из 11 символов. Пусть известно, что эти символы составляют целое сообщение, а не фрагмент более крупного текста. В этом случае наше зашифрованное сообщение состоит из одного или нескольких целых слов. В зашифрованном сообщении символ Ъ встречается 2 раза. Предположим, что в открытом тексте на месте зашифрованного знака Ъ стоит гласная О, А, И или Е. Подставим на место Ъ эти буквы и оценим возможность дальнейшего криптоанализа таблица 2.1
| Зашифрованное сообщение | ||||||||||
| Т | Н | Ф | Ж | . | И | П | Щ | Ъ | Р | Ъ |
| После замены Ъ на О | ||||||||||
| О | О | |||||||||
| После замены Ъ на А | ||||||||||
| А | А | |||||||||
| После замены Ъ на И | ||||||||||
| И | И | |||||||||
| После замены Ъ на Е | ||||||||||
| Е | Е | |||||||||
Все приведенные варианты замены могут встретиться на практике. Попробуем подобрать какие-нибудь варианты сообщений, учитывая, что в криптограмме остальные символы встречаются по одному разу ( таблица 2.2).
| Зашифрованное сообщение | ||||||||||
| Т | Н | Ф | Ж | . | И | П | Щ | Ъ | Р | Ъ |
| Варианты подобранных дешифрованных сообщений | ||||||||||
| Ж | Д | И | С | У | М | Р | А | К | А | |
| Д | Ж | О | Н | А | У | Б | И | Л | И | |
| В | С | Е | Х | П | О | Б | И | Л | И | |
| М | Ы | П | О | Б | Е | Д | И | Л | И | |
Кроме представленных на таблица 2.2 сообщений можно подобрать еще большое количество подходящих фраз. Таким образом, если нам ничего не известно заранее о содержании перехваченного сообщения малой длины, дешифровать его однозначно не получится.
Если же в руки криптоаналитиков попадает достаточно длинное сообщение, зашифрованное методом простой замены, его обычно удается успешно дешифровать. На помощь специалистам по вскрытию криптограмм приходят статистические закономерности языка. Чем длиннее зашифрованное сообщение, тем больше вероятность его однозначного дешифрования.
В "Алгоритм криптографического преобразования данных ГОСТ 28147-89" будут более подробно рассмотрены вопросы теоретической стойкости криптосистем, а также принципы построения идеальных криптосистем.
Интересно, что если попытаться замаскировать статистические характеристики открытого текста, то задача вскрытия шифра простой замены значительно усложнится. Например, с этой целью можно перед шифрованием "сжимать" открытый текст с использованием компьютерных программ-архиваторов.
С усложнением правил замены увеличивается надежность шифрования. Можно заменять не отдельные символы, а, например, двухбуквенные сочетания – биграммы. Таблица замен для такого шифра может выглядеть, как на таблица 2.3.
| Откр. текст | Зашифр. текст | Откр. текст | Зашифр. текст |
|---|---|---|---|
| аа | кх | бб | пш |
| аб | пу | бв | вь |
| ав | жа | ... | ... |
| ... | ... | яэ | сы |
| ая | ис | яю | ек |
| ба | цу | яя | рт |
Оценим размер такой таблицы замен. Если исходный алфавит содержит N символов, то вектор замен для биграммного шифра должен содержать N2 пар "откр. текст – зашифр. текст". Таблицу замен для такого шифра можно также записать и в другом виде: заголовки столбцов соответствуют первой букве биграммы, а заголовки строк – второй, причем ячейки таблицы заполнены заменяющими символами. В такой таблице будет N строк и N столбцов ( таблица 2.4).
| а | б | ... | я | |
|---|---|---|---|---|
| а | кх | цу | ... | ... |
| б | пу | пш | ... | ... |
| в | жа | вь | ... | ... |
| ... | ... | ... | ... | ... |
| ю | ... | ... | ... | ек |
| я | ис | ... | ... | рт |
Возможны варианты использования триграммного или вообще n-граммного шифра. Такие шифры обладают более высокой криптостойкостью, но они сложнее для реализации и требуют гораздо большего количества ключевой информации (большой объем таблицы замен). В целом, все n-граммные шифры могут быть вскрыты с помощью частотного криптоанализа, только используется статистика встречаемости не отдельных символов, а сочетаний из n символов.