|
Здравствуйте. А уточните, пожалуйста, по какой причине стоимость изменилась? Была стоимость в 1 рубль, стала в 9900 рублей. |
Спонсор: Microsoft
Вы можете этот курс.
Опубликован: 25.05.2011 | Доступ: свободный | Студентов: 6101 / 2293 | Оценка: 4.19 / 3.94 | Длительность: 12:28:00
Тема: Сетевые технологии
Специальности: Программист, Архитектор программного обеспечения
Лекция 7:
Azure Services Platform
Azure Table Services
Windows Azure Table - структурированное хранилище, которе поддерживает высокомасштабируемые таблицы в облаке, которые могут содержать миллиарды сущностей и терабайты данных. По мере увеличения трафика, система будет эффективно масштабироваться, автоматически подключая тысячи серверов. Структурированное хранилище реализовано в виде таблиц (Tables), в которых располагаются сущности (Entities), содержащие ряд именованных свойств (Properties). Вот некоторые из основных характеристик Windows Azure Table:
- Поддержка LINQ, ADO .NET Data Services и REST.
- Контроль типов во время компиляции при использовании клиентской библиотеки ADO .NET Data Services.
- Богатый набор типов данных для значений свойств.
- Поддержка неограниченного количества таблиц и сущностей без ограничения размеров таблиц.
- Поддержка целостности для каждой сущности.
- Нежесткая блокировка при обновлениях и удалениях.
- Для запросов, выполнение которых требует длительного периода времени, или запросов, прерванных по завершению времени ожидания, возвращаются частичные результаты и маркер продолжения
Рассмотрим модель данных таблицы Windows Azure Table:
- Учетная запись хранилища (Storage Account) – для доступа к Windows Azure Storage приложение должно использовать действительную учетную запись. Новую учетную запись можно создать через веб-интерфейс портала Windows Azure. Как только учетная запись создана, пользователь получает 256-разрядный секретный ключ, который впоследствии используется для аутентификации запросов этого пользователя к системе хранения. В частности, с помощью этого секретного ключа создается подпись HMAC SHA256 для запроса. Эта подпись передается с каждым запросом данного пользователя для обеспечения аутентификации. Имя учетной записи входит в состав имени хоста в URL. Для доступа к таблицам используется следующий формат имени хоста: <имяУчетнойЗаписи>.table.core.windows.net.
- Таблица (Table) – содержит набор сущностей. Область действия имен таблиц ограничена учетной записью. Приложение может создавать множество таблиц в рамках учетной записи хранилища.
- Сущность (строка) (Entity (Row)) – Сущности (сущность является аналогом "строки") – это основные элементы данных, хранящиеся в таблице. Сущность включает набор свойств. В каждой таблице имеется два свойства, которые образуют уникальный ключ для сущности.
- Свойство (столбец) (Property (Column)) – Представляет отдельное значение сущности. Имена свойств чувствительны к регистру. Для значений свойств поддерживается богатый набор типов.
- Ключ секции (PartitionKey) – Первое свойство ключа каждой таблицы. Эта система использует данный ключ для автоматического распределения сущностей таблицы по множеству узлов хранения.
- Ключ строки (RowKey) – Второе свойство ключа таблицы. Это уникальный ID сущности в рамках секции. PartitionKey в сочетании с RowKey уникально идентифицирует сущность в таблице.
- Временная метка (Timestamp) – Каждая сущность имеет версию, сохраняемую системой.
- Секция (Partition) – Набор сущностей в таблице с одинаковым значением ключа секции.
- Порядок сортировки (Sort Order) – Для CTP-версии предоставляется всего один индекс, в котором все сущности сортированы по PartitionKey и затем по RowKey. Это означает, что запросы с указанием этих ключей будут более эффективными, и все возвращаемые результаты будут сортированы по PartitionKey
Таблица имеет гибкую схему. Windows Azure Table отслеживает имя и типизированное значение каждого свойства каждой сущности. Приложение может моделировать фиксированную схему на стороне клиента, обеспечивая одинаковый набор свойств для всех создаваемых сущностей.
Рассмотрим некоторые дополнительные сведения о сущностях:
- Сущность может иметь до 255 свойств, включая обязательные системные свойства: PartitionKey, RowKey и Timestamp. Имена всех остальных свойств сущностей определяются приложением.
- Свойства PartitionKey и RowKey строкового типа.
- Свойство Timestamp является доступным только для чтения обслуживаемым системой свойством, которое должно рассматриваться как непрозрачное свойство.
- Отсутствие фиксированной схемы – Windows Azure Table не сохраняет никакой схемы, поэтому все свойства хранятся как пары <имя, типизированное значение>. Это означает, что свойства сущностей одной таблицы могут сильно отличаться. В таблице даже может быть две сущности, свойства которых имеют одинаковые имена, но разные типы значений.
- Суммарный объем всех данных сущности не может превышать 1 МБ. Сюда входит размер имен свойств, а также размер значений свойств или их типов, включая и два обязательных свойства ключей (PartitionKey и RowKey).
- Поддерживаются типы Binary, Bool, DateTime, Double, GUID, Int, Int64, String. Ограничения представлены в таблице ниже.
| Тип свойства | Описание |
|---|---|
| Binary | Массив байтов размером до 64 КБ. |
| Bool | Булево значение. |
| DateTime | 64-разрядное значение, представляющее время в формате UTC. Поддерживаемый диапазон значений: от 1/1/1600 до 12/31/9999. |
| Double | 64-разрядное значение с плавающей точкой. |
| GUID | 128-разрядный глобально уникальный идентификатор. |
| Int | 32-разрядное целое значение. |
| Int64 | 64-разрядное целое значение. |
| String | 16-разрядное UTF-кодированное значение. Размер строковых значений может быть до 64 КБ. |
Windows Azure Table обеспечивает возможность масштабирования таблиц до тысяч узлов хранения через распределение сущностей в таблице. При распределении сущностей желательно обеспечить, чтобы сущности, входящие в одно множество, располагались в одном узле хранения. Приложение формирует эти множества соответственно значениям свойства PartitionKey сущностей.
Приложениям должна быть известна рабочая нагрузка каждой отдельно взятой секции. Для обеспечения желаемых результатов тестирование должно моделировать максимальную рабочую нагрузку.
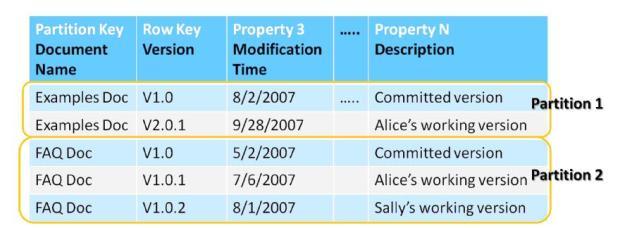
На рисунке выше представлена таблица, содержащая множество версий документов. Каждая сущность данной таблицы соответствует определенной версии определенного документа. В этом примере ключом секции таблицы является имя документа, и ключом строки – номер версии. Имя документа и версия уникально идентифицируют каждую сущность таблицы. В данном примере секцию образуют все версии одного документа.
Хорошая масштабируемость системы хранения достигается за счет распределения секций по множеству узлов хранения.
Система отслеживает характер использования секций и автоматически равномерно распределяет эти секции по всем узлам хранения. Это позволяет системе и приложению масштабироваться соответственно количеству запросов к таблице. То есть если некоторые секции запрашиваются больше других, система автоматически разнесет их на несколько узлов хранения, таким образом, распределяя трафик между множеством серверов. Однако секция, т.е. все сущности, имеющие одинаковый ключ секции, будут обслуживаться как один узел. Но даже несмотря на это, объем данных в рамках секции не ограничен емкостью хранилища одного узла хранения.
Сущности одной секции хранятся вместе. Это обеспечивает наиболее эффективную обработку запросов к секции. Более того, в этом случае приложение может использовать все преимущества эффективного кэширования и других оптимизаций производительности, обеспечиваемых расположением данных в секции.
В примере выше секцию образуют все версии одного документа. Таким образом, для извлечения всех версий данного документа необходимо выполнить доступ всего к одной секции. Чтобы получить все версии документов, измененные до 5/30/2007, придется запрашивать несколько секций, что будет не так эффективно и более ресурсоемко, поскольку по запросу должны будут проверяться все секции, которые к тому же могут располагаться на разных узлах хранения.
Выбор ключа секции важен с точки зрения обеспечения эффективного масштабирования приложения. При этом необходимо найти компромисс между размещением сущностей в одной секции, что обеспечивает большую эффективность запросов, и масштабируемостью таблицы, поскольку, чем больше секций в таблице, тем проще для Windows Azure Table распределить нагрузку между множеством серверов.
Для наиболее частых и критичных по времени ожидания запросов PartitionKey должен быть включен как часть выражения запроса. Запрос, в котором указан PartitionKey, будет намного эффективнее, поскольку в этом случае просматриваются сущности только одной секции. Если при выполнении запроса PartitionKey не указан, в поисках необходимых сущностей просматриваются все секции таблицы, что значительно снижает эффективность.
Далее представлены некоторые советы и рекомендации по выбору PartitionKey для таблицы:
- Прежде всего, выявите важные свойства таблицы. Это свойства, используемые в условиях запросов.
- Из этих важных свойств выберите потенциальные ключи.
- Из преобладающего запроса выберите свойства, используемые в условиях. Важно понять, какой запрос будет преобладающим для приложения.
- Это будет исходный набор свойств ключей.
- Расставьте свойства ключей в порядке их значимости в запросе.
- Проверьте, обеспечивают ли свойства ключей уникальную идентификацию сущности? Если нет, включите в набор ключей уникальный идентификатор.
- Если имеется только одно свойство ключа, используйте его в качестве PartitionKey.
- Если имеется только два свойства ключей, первое используйте как ParitionKey и второе – как RowKey.
- При наличии более двух свойств ключей можно попытаться распределить их в две группы: первая группа будет PartitionKey, и вторая – RowKey. При таком подходе приложение должно знать, что PartitionKey, например, состоит из двух ключей, разделенных "-".
Теперь, когда приложение имеет набор потенциальных ключей, необходимо убедиться, что выбранная схема секционирования является масштабируемой:
- Исходя из статистических данных интенсивности использования приложения, определите, не приведет ли секционирование по выбранному выше PartitionKey к созданию слишком загруженных секций, которые не смогут эффективно обслуживаться одним сервером? Проверить это можно, применив нагрузочное тестирование секции таблицы. Для этого в тестовой таблице создается секция соответственно выбранным ключам. Она подвергается пиковой нагрузке, полученной исходя из предполагаемых полезной нагрузки и запросов. Это позволяет проверить, может ли секция таблицы обеспечить необходимую производительность приложения.
- Если секция таблицы проходит нагрузочное тестирование, ключи выбраны правильно.
- Если секция таблицы не проходит нагрузочного тестирования, найдите ключ секции, который обеспечил бы более узкое подразделение сущностей. Это можно сделать через объединение выбранного ключа секции со следующим свойством ключа, или выбрав в качестве ключа секции другое важное свойство. Целью этой операции должно быть создание большего количества секций, чтобы не возникало одной слишком большой или слишком загруженной секции.
- Система спроектирована так, что обеспечивает необходимое масштабирование и обработку большого количества запросов. Но при чрезвычайно высокой интенсивности запросов ей приходится выполнять балансировку нагрузки, в результате чего некоторые из запросов могут завершаться ошибкой превышения времени ожидания. Сократить или устранить ошибки такого рода может снижение интенсивности запросов. Вообще говоря, такие ошибки возникают редко; однако если вы столкнулись с частыми или неожиданными ошибками превышения времени ожидания, свяжитесь с нами через сайт
MSDN, мы обсудим, как оптимизировать использование Windows Azure Table и предотвратить возникновение таких ошибок в вашем приложении.
Также можно проанализировать расширяемость выбранных ключей, особенно если на момент их выбора нет точных сведений о характеристиках пользовательского трафика. В этом случае важно выбирать ключи, которые можно легко расширять для обеспечения более тонкого секционирования. Далее в данном документе приводится подробный пример этого.
Для таблиц и сущностей поддерживаются следующие базовые операции:
- Создание таблицы или сущности.
- Извлечение таблицы или сущности с применением фильтров.
- Обновление сущности (но не таблицы).
- Удаление таблицы или сущности.
Для работы с таблицами в .NET-приложении можно просто использовать ADO.NET Data Services.
В следующей таблице приведен список предлагаемых API. Поскольку применение ADO.NET Data Services в итоге сводится к передаче REST-пакетов, приложения могут использовать REST напрямую. Кроме того, что REST обеспечивает возможность доступа к хранилищу посредством не-.NET языков, он также позволяет реализовывать более тонкое управление сериализацией/десериализацией сущностей, что пригодится при работе с такими сценариями, как наличие разных типов сущностей или более чем 255 свойств в таблице и т.д.