|
приветствую создателей курса и благодарю за доступ к информации! понимаю, что это уже никто не исправит, но, возможно, будут следующие версии и было бы неплохо дать расшифровку сокращений имен регистров итд, дабы закрепить понимание их роли в общем процессе. |
Национальный исследовательский ядерный университет «МИФИ»
Опубликован: 03.03.2010 | Доступ: свободный | Студентов: 5486 / 1393 | Оценка: 4.35 / 3.96 | Длительность: 24:14:00
ISBN: 978-5-9963-0267-3
Тема: Аппаратное обеспечение
Специальности: Разработчик аппаратуры
Лекция 16:
Процессоры цифровой обработки сигналов
Предположим, что программа на Си пишется в 5 раз быстрее, чем на ассемблере, а получаемый в результате трансляции код работает примерно во столько же раз медленнее. Тогда в случае, когда некоторый участок программы объемом 20 % кода занимает 80 % времени выполнения программы, что бывает достаточно часто ("правило 80/20"), получим, что программирование этого фрагмента на ассемблере приведет к увеличению времени программирования на 80 %, но уменьшит время работы программы почти втрое (табл. 16.1).
Вот почему программы для процессоров, имеющих критичное значение времени работы, хотя в большинстве случаев и написаны на Си, но пестрят ассемблерными вставками.
К интересным особенностям DSP-ассемблеров можно отнести наличие двух форм записи многих команд - мнемонической и алгебраической. Мнемоническая форма аналогична записи команд для обычных микропроцессоров, например, ADD dst, src. Другая, алгебраическая форма в ассемблерах микропроцессоров других классов используется реже, в то время как на DSP-ассемблере упомянутая команда может быть записана в виде DSt= DSt+ src. Обычно ассемблеры DSP понимают обе формы записи, но, например, ассемблеры ADI и Lucent применяют только алгебраическую запись.
Спектр компаний, представленных на рынке DSP-процессоров, более широк, чем среди производителей универсальных микропроцессоров.
В настоящее время доминирующее положение на рынке ЦСП занимает фирма Texas Instruments. Среди остальных производителей этой продукции следует выделить фирмы Freescale Semiconductor (ранее подразделение Motorola), Analog Devices, Phillips Semiconductors и Agere Systems (Lucent MicroelecTRonic) (табл. 16.2). Следует отметить, что данный рынок является очень подвижным, что приводит к его постоянному перераспределению между компаниями и появлению на рынке новых игроков.
С ростом числа областей применения ЦОС и сложности алгоритмов обработки возрастают требования к сигнальным процессорам в плане повышения быстродействия и оснащенности интерфейсными и другими специализированными узлами. В настоящее время на рынке присутствует множество типов ЦСП, как универсальных, так и ориентированных на достаточно узкий круг задач. Естественно, ни один из процессоров не может быть оптимальным для всех приложений. Поэтому первая задача разработчика - выбор процессора, наиболее подходящего по производительности, цене, наличию определенной периферии, потребляемой мощности, простоте использования и другим критериям.
Например, для таких портативных устройств, как мобильные телефоны, портативные цифровые плееры, первостепенными являются стоимость, степень интеграции и потребляемая мощность, а максимальная производительность зачастую не нужна, так как обычно влечет за собой значительное повышение потребляемой мощности, не давая преимуществ при обработке относительно низкоскоростных аудиоданных. В то же время для гидроакустических или радиолокационных систем определяющими параметрами являются скорость работы, наличие высокоскоростных интерфейсов, а стоимость является второстепенным критерием.
Хотя большинство фирм выпускает широкую номенклатуру процессоров, которые могут быть использованы для различных применений, среди них наблюдается определенная специализация. Так, следует отметить предпочтительность процессоров Analog Devices для приложений, требующих выполнения больших объемов математических вычислений (таких как цифровая фильтрация сигнала, вычисление корреляционных функций и т. п.), поскольку их производительность на подобных задачах выше, чем у процессоров компаний Freescale и Texas INsTRuments. В то же время для задач, требующих выполнения интенсивного обмена с внешними устройствами (многопроцессорные системы, различного рода промышленные контроллеры), предпочтительнее использовать процессоры Texas INsTRuments, обладающие высокоскоростными интерфейсными подсистемами. Компания Freescale является лидером по объему производства относительно дешевых и достаточно производительных 16- и 24-разрядных сигнальных процессоров с фиксированной точкой.
Рассмотрим структуру и основные характеристики DSP-процессора на примере процессора цифровой обработки сигналов TMS320F2833x фирмы Texas INsTRuments.
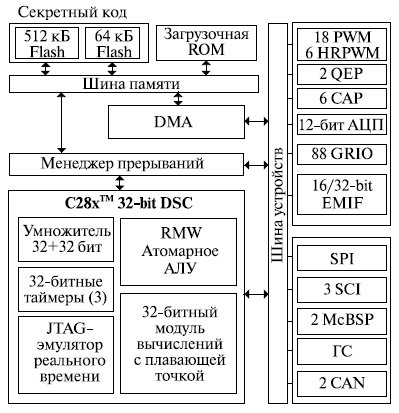
Семейство этих процессоров представляет собой 32-разрядные цифровые сигнальные процессоры, объединяющие в себе мощные и эффективные технологии цифровой обработки сигналов с богатым набором периферийных устройств и простотой использования. Данная платформа процессоров изначально создавалась для приложений управления электродвигателями и электроприводами. В процессе развития они приобрели более развитую периферию и мощное 32-разрядное ядро сигнального процессора, за счет чего область их применения значительно расширилась и в настоящее время включает в себя также те области, где ранее традиционно применялись мощные микроконтроллеры. В настоящее время семейство включает в себя модели TMS320F2832, TMS320F2833 и TMS320F2835, отличающиеся частотой синхронизации, емкостью внутренней памяти и некоторыми другими количественными параметрами. В дальнейшем описании мы будем опираться на характеристики ЦСП модели TMS320F2835, структура которого представлена на рис. 16.4.
Процессор содержит блок обработки чисел с плавающей точкой, аппаратный умножитель, позволяющий выполнять за один цикл операцию типа 32x32 бит MAC либо две операции типа 16x16 бит MAC, а также так называемое атомарное АЛУ, которое обеспечивает выполнение за 1 цикл таких операций, как чтение-модификация-запись по любому из адресов памяти, что позволяет значительно повысить производительность и эффективность кода.
В состав процессора входят разнообразные запоминающие устройства:
- однопортовое ОЗУ (SARAM) объемом 34К*16 слов; оно состоит из 8 блоков с организацией 4К 16-разрядных слов каждый и 2 блоков емкостью по 1К*16 байт, в которых может храниться таблица векторов прерываний;
- ПЗУ (в этом процессоре обозначается как OTP - one-time programmable): 1К*16 разрядов;
- модуль Flash-памяти емкостью 512 Кбайт, который позволяет разработчику многократно изменять программу в процессоре, в том числе и непосредственно в готовом изделии, что обеспечивает максимальную легкость и удобство обновления программных версий приборов. Flash-память разбита на секторы, что позволяет пользователю программировать лишь часть памяти, не осуществляя предварительного полного стирания. Однако следует отметить, что Flash-память работает медленнее, чем ядро процессора и его основная память (память программ и память данных), поэтому некоторые части кода, такие как функции прерываний, а также функции, критичные к скорости выполнения, не могут выполняться из Flash;
- загрузочная память Boot ROM объемом 8К слов по 16 разрядов.
Записанная здесь микропрограмма выполняется ядром процессора каждый раз при подаче питания на процессор, а также после сброса. Результатом ее выполнения является передача функций загрузки программы, которую ЦСП должен выполнить, определенному периферийному устройству, подключенному по интерфейсу SPI, I2C и т. п., либо внутренней или внешней Flash-памяти. Здесь же содержатся таблицы нормализованных значений математических функций, таких как синус, косинус, а также таблицы векторов прерываний.
Flash-память, ПЗУ и блоки L0-L7 ОЗУ защищены 128-разрядным секретным ключом.
Память имеет возможность расширения до 2М*16 слов посредством 16/32-разрядной шины EMIF.
Система команд для работы с числами в формате с плавающей точкой является функционально полной. Помимо обычных арифметических команд и команд конвертирования форматов (из формата с фиксированной в формат с плавающей точкой и обратно), система команд включает в себя также команды получения первого приближения обратного значения числа в формате с плавающей точкой и квадратного корня. Тем самым аппаратно обеспечивается высокая эффективность любых операций с плавающей точкой, включая деление. Компилятор Си/Си++ автоматически оптимизирует программу пользователя с учетом возможного параллельного выполнения команд, добавляя, как правило, не конфликтующие между собой команды загрузки операндов, которые понадобятся на следующих этапах вычислений (VLIW-подход). Эти аппаратные возможности поддерживаются компилятором Си/Си++. На аппаратном уровне поддерживаются как команды повторения отдельной инструкции, так и команды повторения блока кода.
Все процессоры семейства F2833x являются высокоинтегрированными устройствами и содержат:
-
последовательные интерфейсы, включающие:
- 2 сетевых порта CAN, позволяющие организовать две независимо работающие CAN-сети - для подключения внутренних интеллектуальных устройств и внешних, например, для связи с системами управления верхнего уровня;
- 3 порта асинхронного последовательного интерфейса SCI (UART), используемых для межпроцессорной или другой асинхронной связи в дуплексном и полудуплексном режимах;
- порт синхронного последовательного интерфейса (SPI);
- шину I2C;
- 2 буферированных последовательных порта McBSP;
- 88 последовательных портов ввода-вывода общего назначения (GPIO) с независимым тактированием и возможностью многоканальных режимов работы с поддержкой блочной передачи по каждому каналу;
- порт JTAG, позволяющий отлаживать систему в реальном времени;
- 12 -разрядный 16-канальный АЦП со временем преобразования сигнала 80 нс, что на сегодняшний день является лучшим результатом среди АЦП, встроенных в ЦСП;
- 6 контроллеров прямого доступа в память. Передача данных по каналу ПДП выполняется пакетами. Длина каждого пакета - не более 32 16-разрядных слов. Общее число пакетов в передаче - до 65535. По завершении передачи канал ПДП может генерировать запрос прерывания для новой инициализации контроллера ПДП.
В процессе передачи данных возможна их ортогональная перестановка для последующего ускорения обработки данных центральным процессором. Каналы работают в режиме либо циклически меняющихся, либо фиксированных приоритетов. В последнем случае процесс передачи данных по низкоприоритетным каналам может прерываться и возобновляться при завершении высокоприоритетной передачи;
- три 32-разрядных таймера;
- сторожевой таймер, предохраняющий систему от зависания;
- шесть 32-разрядных каналов захвата внешних событий ( enhanced capture - eCAP ), используемых в системах, где важно точное согласование во времени внешних событий, например, при измерении периода следования сигналов;
- два 32-разрядных модуля eQEP ( enhanced quadrature encoder pulse ), предназначенных для поддержки измерений скорости и частоты, детектирования заклинивания ротора и определения его положения, контроля неисправностей. Могут использоваться как дополнительные модули CAP;
- расширенный блок широтно-импульсной модуляции ( enhanced pulse-width modulator - EPWM ), обеспечивающий функционирование 18 каналов ШИМ, 6 из которых работают на повышенной частоте с разрешением 150 пс. Широкие возможности этого блока связаны с основными областями применения данного сигнального процессора: автомобильная промышленность, промышленная автоматика, измерительные приборы, преобразователи мощности.
Рассмотрим работу этого блока более подробно.
Каждый модуль ШИМ-генератора содержит базовый таймер, блок сравнения, конструктор выходных ШИМ-сигналов. Модуль имеет два выхода EPWMA и EPWMB, которые можно использовать либо независимо друг от друга, либо в паре.
Базовый таймер модуля работает в режимах нереверсивного и реверсивного счетчика. Период ШИМ задается в регистре периода, а начальное состояние счетчика аппаратно загружается из регистра фазового сдвига. Тем самым обеспечивается возможность формирования различными каналами ШИМ-сигналов, сдвинутых друг относительно друга на любой заданный угол.
Отличительной особенностью блока являются два независимых канала с регистрами задания двух уставок сравнения CMPA и CMPB. Конструктор ШИМ-сигналов для каждого из двух выходов позволяет по любому из пяти входных событий сгенерировать следующие выходные события: установить высокий или низкий уровень сигнала; переключить с высокого на низкий уровень или обратно; оставить состояние выхода неизменным. Чтобы сконструировать выходные периодические сигналы, разработчику нужно расставить на "опорной цифровой пиле" графические обозначения требуемых выходных событий и в соответствии с ними проинициализировать ШИМ-генератор. На рис. 16.5 в качестве примера показано формирование двух ШИМ-сигналов. Входные события по сравнению A вверх (CA  ) и вниз (CA
) и вниз (CA 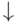 ) управляют фронтами первого ШИМ-сигнала, а по сравнению B вверх (CB ) и вниз (CВ ) - фронтами второго ШИМ-сигнала.
) управляют фронтами первого ШИМ-сигнала, а по сравнению B вверх (CB ) и вниз (CВ ) - фронтами второго ШИМ-сигнала.
Имеется возможность по нужному событию (например, "по периоду") генерировать запрос прерывания и в процедуре обслуживания этого прерывания изменять параметры ШИМ-сигналов (период, скважность).
Структура процессора обеспечивает быструю реакцию на прерывания и их обработку. Запросы прерываний генерируются как внешними устройствами, так и модулями самого процессора. Блок обработки внешних прерываний ( PerIPheral INTerrupt Expansion - PIE ) используется для проведения арбитража запросов прерываний от внешних устройств и поддерживает до 8 запросов внешних маскируемых прерываний, которые могут поступать по любой из 64 линий портов общего назначения GPIO0-GPIO63, а также запрос по внешнему входу XNMI. Каждое прерывание может быть настроено на срабатывание по высокому или низкому уровню сигнала и разрешено либо запрещено к обслуживанию. Блок обработки прерываний для каждого из внешних запросов содержит 16-разрядный счетчик, который может применяться для отметки количества прерываний данного типа.
В качестве источников внутренних прерываний выступают таймеры, каналы ПДП и другие модули процессора.
Каждое из прерываний имеет свой вектор прерываний, который может быть изменен. Приоритеты прерываний устанавливаются как на аппаратном, так и на программном уровнях.
Напряжение питания процессора составляет 1,9 В, а напряжение внешних портов 3,3 В.
В семействе процессоров 320F28х больше внимание уделяется снижению энергопотребления (до 0,05 мВт на 1 млн операций в секунду). Это достигается за счет отключения неактивных устройств и возможностью управления энергопотреблением со стороны пользователя (до 64 режимов энергопотребления).
Наличие модуля поддержки вычислений с плавающей запятой удорожает процессор, поэтому для разработчиков, работающих исключительно в формате с фиксированной точкой, предлагаются помимо процессоров серии 2833х точно такие же изделия, но без этого модуля: 28235, 28234, 28232.
Владислав Салангин
