
|
Подскажите, пожалуйста, планируете ли вы возобновление программ высшего образования? Если да, есть ли какие-то примерные сроки? Спасибо! |
Опубликован: 20.12.2010 | Доступ: свободный | Студентов: 2427 / 173 | Оценка: 4.27 / 3.91 | Длительность: 39:39:00
ISBN: 978-5-9963-0353-3
Тема: Базы данных
Специальности: Администратор баз данных
Лекция 11:
Проектирование и разработка процесса ETL
Аннотация: В настоящей лекции рассматриваются общие принципы организации процесса извлечения, преобразования и загрузки данных (Extract, Transform, Load — ETL) для ХД, приводится классификация систем – источников данных, обсуждаются некоторые методы извлечения данных. Рассмотрена в общих чертах методика проектирования ETL-процессов с использованием CASE-инструментов.
Ключевые слова: ETL, элементы ETL-процесса, диаграмма движения данных, диаграмма преобразования данных, диаграммы управления потоком преобразования данных, извлечение данных, преобразование данных, загрузка данных, производительность, extraction, transformation, БД, периодичность, ПО, метаданные, качество данных, контроль, место, управление данными, Data, очистка данных, area, Размещение, запись, MPP, бюджет проекта, планирование ETL-процесса, многомерная модель, механизм триггеров, EBCDIC, преобразование форматов данных, денормализация, секция таблицы, информация, интеллектуальный анализ данных, EII, enterprise, information, чтение данных, CASE, model, ILM, data transformation, control flow, replication server, data input
Цель лекции
Изучив материал настоящей лекции, вы будете знать:
- что такое процесс ETL;
- место процесса ETL в архитектуре системы бизнес аналитики на основе хранилищ данных;
- что такое реализация ETL-процесса с использованием промежуточной области;
- что такое реализация ETL-процесса без использования промежуточной области;
- основные элементы ETL-процесса ;
и научитесь:
- строить диаграммы движения данных, диаграммы преобразования данных, диаграммы управления потоком преобразования данных ;
- выполнять общее планирование реализации ETL-процесса;
- проектировать ETL-процессы.
Литература: [3], [14], [33], [ [ 32 ] 32], [51].
Введение
Для того чтобы заставить ХД заработать, необходимо не просто обеспечить взаимодействие многих источников данных – важно тщательно спланировать это взаимодействие. Поэтому процессы извлечения, преобразования и загрузки данных играют важную роль в создании и эксплуатации ХД.
Чтобы процесс преобразования данных протекал без сбоев, необходимо обеспечить наличие необходимой документации и метаданных. Процесс извлечения данных влияет на производительность других систем, поэтому его следует рассматривать в аспекте управления изменениями и конфигурацией систем – источников данных.
Под аббревиатурой ETL (extraction, transformation, loading — извлечение, преобразование и загрузка данных ) понимается составной процесс переноса данных одного приложения или автоматизированной информационной системы в другие.
Процесс ETL реализуется путем либо разработки приложения ETL, либо создания комплекса встроенных программных процедур, либо использования ETL-инструментария. Приложения ETL извлекают информацию из исходных БД источников, преобразуют ее в формат, поддерживаемый БД назначения, а затем загружают в эту БД преобразованные данные.
Цель любого ETL-приложения состоит в том, чтобы своевременно доставить данные из внешних систем в систему, с которой работают пользователи. Как правило, ETL-приложения используются при переносе данных внешних источников в ХД систем бизнес-аналитики. Поэтому организация процесса ETL является составной частью проекта разработки практически любого ХД.
Проектирование и разработка ETL-процесса является одной из самых важных задач проектировщика ХД. Для ХД процесс ETL имеет следующие свойства. Во-первых, объем данных, который выбирается из систем источников данных и помещается в ХД, как правило, бывает достаточно большим, до десятков Гб. Во-вторых, процесс ETL является необходимой составной частью эксплуатации ХД. Периодичность процесса ETL определяется не только потребностью пользователя в своевременных данных, но и размером загружаемой порции данных. По оценкам специалистов, ETL-процесс может занимать до 80% времени. В-третьих, на разных стадиях процесса ETL формируются метаданные ХД и обеспечивается качество данных. В-четвертых, во время процесса ETL может произойти потеря данных, поэтому необходимо обеспечивать контроль за поступлением данных в ХД. В-пятых, процесс ETL обладает свойством восстанавливаемости после сбоев без потери данных.
На рис. 15.1 показано место процесса ETL в архитектуре системы бизнес-аналитики на основе ХД.
Как видно из рисунка, на процесс ETL возложена вся работа по подготовке данных для доставки их в ХД, формирование и обновление метаданных ХД, а также управление данными, извлеченными в результате Data mining.
Таким образом, процесс ETL состоит из трех основных стадий.
- Извлечение данных На этой стадии отбираются и описываются данные внешних источников (начинают формироваться метаданные ХД), которые должны храниться в ХД (релевантные данные).
- Преобразование данных На этой стадии релевантные данные преобразуются в формат представления данных в ХД, правила преобразования сохраняются в метаданных ХД, формируются ключевые поля таблиц физической структуры ХД, выполняется очистка данных.
- Загрузка данных На этой стадии данные загружаются в ХД, выполняется построение агрегатов.
Подходы к реализации ETL-процесса
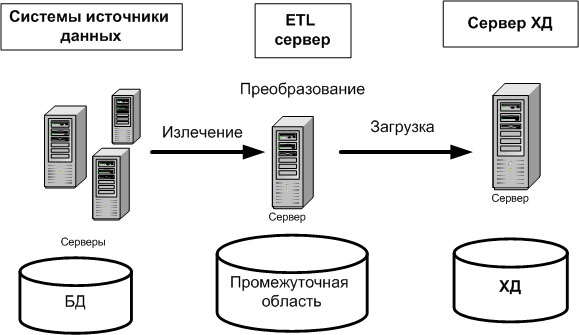
Существует несколько подходов к реализации процесса ETL. Общепринятый подход состоит в извлечении данных из систем источников, размещении их в промежуточной области дисковой памяти (Data Staging Area), выполнении в этой промежуточной области процедур преобразования и очистки данных, а затем загрузки данных в ХД, как показано на рис. 15.2.
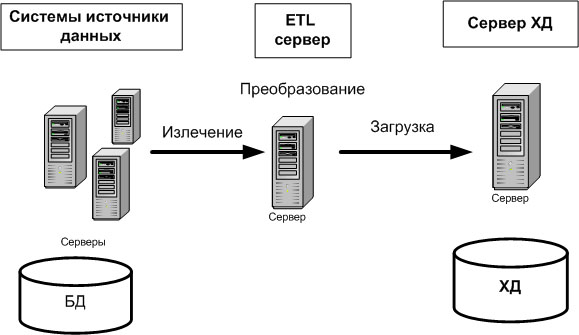
Размещение извлеченных данных в промежуточной области означает запись данных в БД или файлы дисковой подсистемы. Альтернативным подходом к реализации процесса ETL является выполнение преобразований в оперативной памяти ETL-сервера и непосредственную загрузку в ХД, как показано на рис. 15.3.
Преобразование данных в оперативной памяти выполняется быстрее, чем при размещении их предварительно на диске. Однако применение такого подхода лимитируется размером порции загружаемых данных. Если размер порции загружаемых данных достаточно большой, то необходимо использовать промежуточную область.
Иногда применяется еще один подход к реализации процесса ETL, когда преобразование данных выполняется на сервере ХД, в процессе их загрузки. Использование такого подхода определяется вычислительными возможностями сервера ХД. Обычно такой подход применяется для MPP серверов ХД.
В зависимости от того, кто извлекает данные из систем источников, реализация ETL-процесса может быть выполнена следующими способами.
- ETL-сервер периодически подключается к системам, источникам данных, опрашивает их, извлекает результаты выполнения запросов и размещает их у себя для дальнейшей обработки.
- Триггеры систем источников данных отслеживают изменения в данных и размещают измененные данные в отдельных таблицах, которые затем экспортируются на ETL-сервер.
- Специально разработанное приложение в системах источниках данных периодически опрашивает их и экспортирует данные на ETL-сервер.
- Используются log-журналы БД систем источников, которые содержат все транзакции изменения данных. Измененные данные извлекаются из log-журналов и сохраняются на сервере системы источника данных для последующего импорта в ETL-сервер.
В зависимости от того, где выполняется процесс извлечения данных из систем источников, реализация ETL-процесса может быть выполнена следующими способами.
- ETL-процесс выполняется на выделенном ETL-сервере, который располагается между системами источниками данных и сервером ХД. В этом случае процесс ETL не использует вычислительных ресурсов сервера ХД и серверов систем источников данных.
- ETL-процесс выполняется на сервере ХД. В этом случае сервер ХД должен иметь достаточное дисковое пространство для выполнения ETL-процесса, использование ресурсов сервера не должно сильно влиять на производительность запросов пользователей к ХД.
- ETL-процесс выполняется на серверах систем источников данных для ХД. В этом случае изменения в данных сразу же отражаются в ХД. Такой подход используется при разработке ХД реального времени.
Таким образом, при проектировании процесса ETL проектировщик ХД должен на основе анализа требований к функционированию ХД совместно с руководителем ИТ-проекта выбрать программно-аппаратное решение для реализации ETL-процесса, а именно – точно определить, где и каким способом будет выполняться ETL-процесс. На это решение может сильно повлиять бюджет проекта. Например, может быть недостаточно финансовых средств, чтобы реализовать процесс ETL на выделенном сервере.
Разработка ETL-процесса
Как правило, при конструировании процесса ETL для ХД придерживаются следующей последовательности действий.
- Планирование ETL-процесса, которое включает в себя разработку диаграммы потоков данных от систем-источников, определение преобразований, метода генерации ключей и последовательности операций для каждой таблицы назначения.
- Конструирование процесса заполнения таблиц измерений, которое включает в себя разработку и верификацию процесса заполнения статических таблиц измерений, разработку и верификацию механизмов изменения для каждой таблицы измерений.
- Конструирование процесса заполнения таблиц фактов, которое включает в себя разработку и верификацию процесса первоначального заполнения и периодического дополнения таблиц фактов, построение агрегатов и разработку процедур автоматизации процесса ETL.
Планирование ETL-процесса
Процесс преобразования данных играет весьма важную роль в достижении успеха реализации проекта ХД, поэтому он должен быть хорошо спланирован. Разработка плана носит интерактивный характер.
Сначала создается обобщенный план, в котором отражается перечень систем –источников данных и указываются планируемые целевые области данных (данных, которые будут размещаться в ХД). Источник целевых данных определяется на основе сформулированных бизнес-требований к ХД. Как правило, источники данных существенно различаются: от БД и текстовых файлов до SMS-сообщений. Это обстоятельство может значительно усложнить задачу преобразования данных.
Назначение таких высокоуровневых описаний источников дает, с одной стороны, разработчикам представление и о создаваемой системе, и о существующих источниках данных, а с другой, руководству организации, — понимание сложности, связанной с процессами преобразования данных.
К составлению обобщенного плана лучше всего приступать, когда разработана многомерная модель ХД. Тогда для каждой таблицы многомерной схемы можно определить таблицы – источники данных.
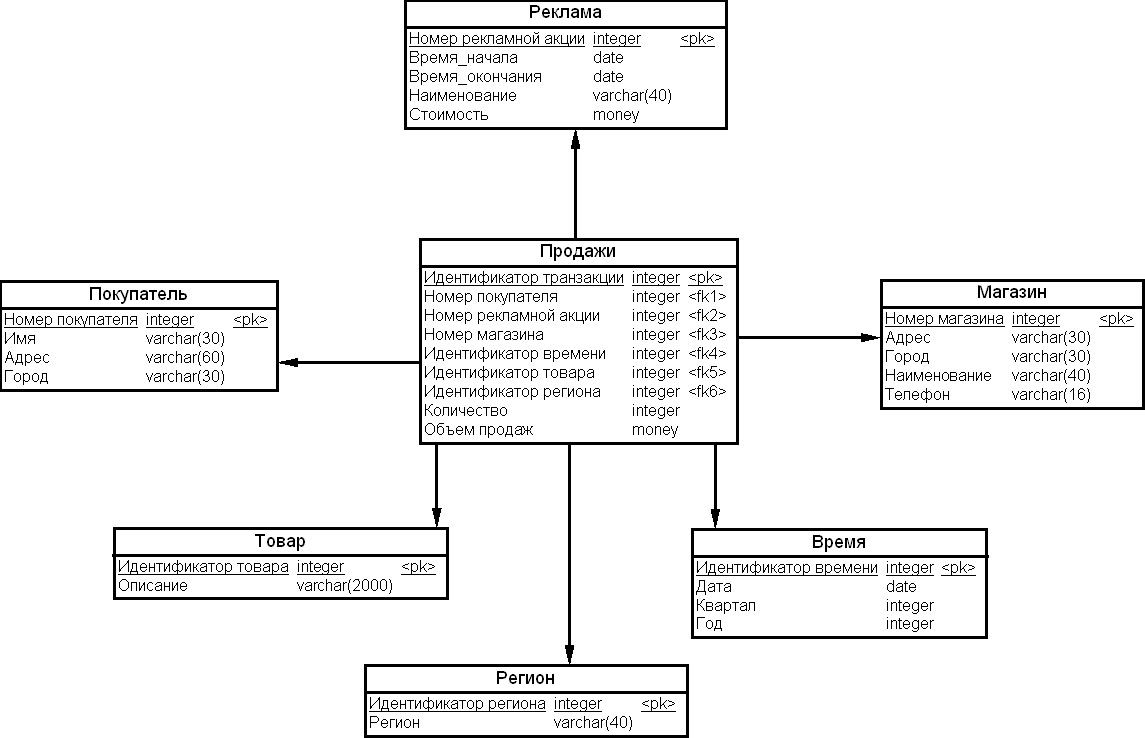
Рассмотрим пример многомерной схемы ХД системы поддержки принятия решений на рис. 15.4.
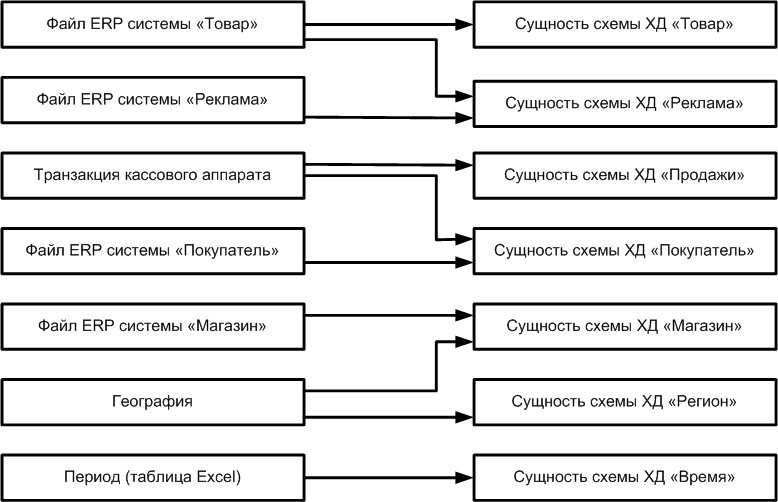
Связи между таблицами многомерной схемы ХД и таблицами – источниками данных можно указать с помощью стрелочек, как на диаграмме на рис. 15.5.
Каждую стрелочку на диаграмме следует пронумеровать и сопроводить комментарием, который должен служить напоминанием разработчикам о необходимости следить за целостностью ссылочных данных или других определенных бизнес-правилами особенностях обработки каждой таблицы источника.
На этой стадии планирования необходимо зафиксировать все обнаруженные расхождения в определениях данных и схемах кодирования.
Детальное планирование ETL-процесса во многом зависит от использования выбранных ETL-инструментов. К настоящему времени разработано достаточно много таких инструментов как компаниями производителями комплексных решений в области ХД (IBM, Oracle, MicroSoft), так и сторонними производителями программного обеспечения (Sunopsis). Поэтому задача выбора подходящих ETL-инструментов должна быть решена до того, как приступать к детальному планированию.
Программное обеспечение этого класса предназначено для извлечения, приведения к общему формату, преобразованию, очистки и загрузки данных в хранилище. Существуют два подхода к написанию ETL-процедур: 1) их можно написать вручную; 2) можно воспользоваться специализированными средствами ETL.
Каждый из подходов имеет ряд преимуществ и недостатков, поэтому выбор того или иного метода реализации процедур ETL определяется требованиями к подсистеме загрузки данных в каждом конкретном случае. Выделим наиболее важные достоинства каждого из способов написания ETL-процедур.
Написание вручную:
- возможность использования широко распространенных парадигм программирования, например, объектно-ориентированного программирования;
- возможность применения многих существующих методик и программных средств, позволяющих автоматизировать процесс тестирования разрабатываемых процедур загрузки данных ;
- доступность человеческих ресурсов;
- возможность построения наиболее производительного решения с использованием при программировании всех преимуществ систем управления базами данных (СУБД), задействованных в проекте;
- возможность построения наиболее гибкого решения.
- упрощение процесса разработки, и, главное, процесса поддержания и модификации процедур ETL;
- ускорение процесса разработки системы, возможность использования готовых наработок, поставляемых вместе со средствами ETL;
- возможность использования встроенных систем управления метаданными, позволяющих синхронизовать метаданные между СУБД, средством ETL, а также инструментами визуализации данных;
- возможность автоматической документации написанных процедур;
- многие средства ETL предоставляют собой средства увеличения производительности подсистемы загрузки данных, которые включают в себя возможность распараллеливания вычислений на различных узлах системы, использование хеширования и многие другие.
Следует обратить внимание на выбор технологии для реализации процедур ETL, в случае если одной из систем-источников данных выступает ERP-система. Системы данного класса являются наиболее сложными, так как обладают очень запутанной моделью данных и зачастую содержат десятки тысяч таблиц. Для реализации процедур загрузки данных из ERP-систем в команду разработчиков должен быть включен специалист, хорошо знакомый с данной системой-источником, так как анализ подобного рода систем с нуля занимает слишком длительное время. Кроме того, большинство поставщиков средств ETL предоставляют коннекторы ко многим ERP-системам, позволяющим импортировать метаданные ERP-систем и работать с ними на более высоком уровне. Наличие коннекторов к ERP-системам предоставляет специализированным средствам ETL большое преимущество над написанием вручную процедур загрузки данных, в случае если в качестве источника данных выступает ERP-система.
После выполнения предварительного планирования приступают к детальному планированию.
Детализированные планы преобразования данных составляются для всех таблиц, участвующих в процессе преобразования.
В настоящей лекции мы не даем рекомендаций по формированию детального плана, поскольку в каждом конкретном случае детальное планирование выполняется руководителем проекта создания ХД и включает в себя учет различных факторов, связанных со спецификой предметной области ХД. Так, например, для банковских ХД, возможно, будет необходимо выполнить проверку корректности бухгалтерской базы по бизнесправилам (провести в процессе ETL подсчет остатков и оборотов по отдельным лицевым и/или балансовым счетам).
Владислав Нагорный
Лариса Парфенова
|
1) Можно ли экстерном получить второе высшее образование "Программная инженерия" ? 2) Трудоустраиваете ли Вы выпускников? 3) Можно ли с Вашим дипломом поступить в аспирантуру?
|