|
Не могу найти требования по оформлению выпускной контрольной работы по курсу профессиональной переподготовки "Менеджмент предприятия" |
Опубликован: 16.12.2009 | Доступ: свободный | Студентов: 2577 / 434 | Оценка: 4.26 / 4.23 | Длительность: 33:53:00
Темы: Экономика, Менеджмент
Специальности: Руководитель, Экономист
Лекция 5:
Многомерный статистический анализ
Подходящая замена переменных во многих случаях позволяет перейти к линейной зависимости. Например, если
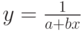
то замена 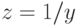 приводит к линейной зависимости
приводит к линейной зависимости 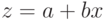 . Если
. Если 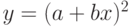 , то замена
, то замена 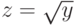 приводит к линейной зависимости
приводит к линейной зависимости 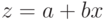 .
.
Основной показатель качества регрессионной модели. Одни и те же данные можно обрабатывать различными способами. Показателем отклонений данных от модели служит остаточная сумма квадратов  . Чем этот показатель меньше, тем приближение лучше, значит, и модель лучше описывает реальные данные. Однако это рассуждение годится только для моделей с одинаковым числом параметров. Ведь если добавляется новый параметр, по которому можно минимизировать, то и минимум, как правило, оказывается меньше.
. Чем этот показатель меньше, тем приближение лучше, значит, и модель лучше описывает реальные данные. Однако это рассуждение годится только для моделей с одинаковым числом параметров. Ведь если добавляется новый параметр, по которому можно минимизировать, то и минимум, как правило, оказывается меньше.
В качестве основного показателя качества регрессионной модели используют оценку остаточной дисперсии
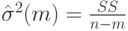
скорректированную на число m параметров, оцениваемых по наблюдаемым данным. В случае линейной прогностической модели, рассмотренной в первом пункте настоящей лекции, оценка остаточной дисперсии имеет вид
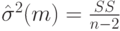
поскольку число оцениваемых параметров  .
.
Почему эта формула отличается от приведенной в первом пункте? Там в знаменателе  , а здесь -
, а здесь - 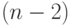 . Дело в том, что в первом пункте рассмотрена непараметрическая теория при большом объеме данных (при
. Дело в том, что в первом пункте рассмотрена непараметрическая теория при большом объеме данных (при 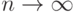 , а при безграничном возрастании разница между и сходит на нет.
, а при безграничном возрастании разница между и сходит на нет.
А вот при подборе вида модели знаменатель дроби, оценивающей остаточную дисперсию, приходится корректировать на число параметров. Если этого не делать, то придется заключить, что многочлен второй степени лучше соответствует данным, чем линейная функция, многочлен третьей степени лучше приближает исходные данные, чем многочлен второй степени, и т.д. В конце концов доходим до многочлена степени 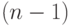 с
с 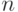 коэффициентами, который проходит через все заданные точки. Но его прогностические возможности, скорее всего, существенно меньше, чем у линейной функции. Излишнее усложнение эконометрических моделей вредно.
коэффициентами, который проходит через все заданные точки. Но его прогностические возможности, скорее всего, существенно меньше, чем у линейной функции. Излишнее усложнение эконометрических моделей вредно.
Типовое поведение скорректированной оценки остаточной дисперсии

в зависимости от параметра 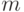 в случае расширяющейся системы эконометрических моделей выглядит так. Сначала наблюдаем заметное убывание. Затем оценка остаточной дисперсии колеблется около некоторой константы (теоретического значения дисперсии погрешности).
в случае расширяющейся системы эконометрических моделей выглядит так. Сначала наблюдаем заметное убывание. Затем оценка остаточной дисперсии колеблется около некоторой константы (теоретического значения дисперсии погрешности).
Поясним ситуацию на примере эконометрической модели в виде многочлена
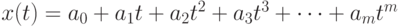
Пусть эта модель справедлива при 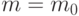 При
При 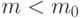 в скорректированной оценке остаточной дисперсии учитываются не только погрешности измерений, но и соответствующие (старшие) члены многочлена (предполагаем, что коэффициенты при них отличны от 0). При
в скорректированной оценке остаточной дисперсии учитываются не только погрешности измерений, но и соответствующие (старшие) члены многочлена (предполагаем, что коэффициенты при них отличны от 0). При  имеем
имеем
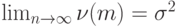
Следовательно, скорректированная оценка остаточной дисперсии будет колебаться около указанного предела. Поэтому в качестве оценки неизвестной эконометрику степени многочлена (полинома) можно использовать первый локальный минимум скорректированной оценки остаточной дисперсии, т.е.
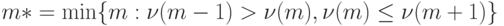
В работе [3] найдено предельное распределение этой оценки степени многочлена.
Теорема. При справедливости некоторых условий регулярности
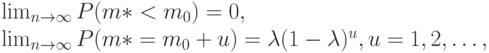
где
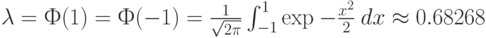
Таким образом, предельное распределение оценки  степени многочлена (полинома) является геометрическим. Это означает, в частности, что оценка не является состоятельной. При этом вероятность получить меньшее значение, чем истинное, исчезающе мала. Далее имеем:
степени многочлена (полинома) является геометрическим. Это означает, в частности, что оценка не является состоятельной. При этом вероятность получить меньшее значение, чем истинное, исчезающе мала. Далее имеем:
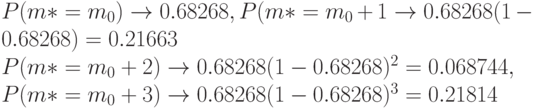
Разработаны и иные методы оценивания неизвестной степени многочлена, например, с помощью многократного применения процедуры проверки адекватности регрессионной зависимости с помощью статистики Фишера (см. работу [3]). Предельное поведение оценок - таково же, как в приведенной выше теореме, только значение параметра иное.
Линейный и непараметрические парные коэффициенты корреляции. Термин "корреляция" означает "связь". В эконометрике этот термин обычно используется в сочетании "коэффициенты корреляции".
Рассмотрим способы измерения связи между двумя случайными переменными. Пусть исходными данными является набор случайных векторов 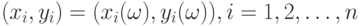 . Коэффициентом корреляции, более подробно, линейным парным коэффициентом корреляции К. Пирсона называется (см. приложение 1)
. Коэффициентом корреляции, более подробно, линейным парным коэффициентом корреляции К. Пирсона называется (см. приложение 1)

Если 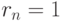 , то
, то 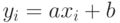 причем
причем 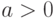 . Если же
. Если же 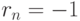 , то
, то 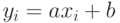 причем
причем 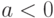 . Таким образом, близость коэффициента корреляции к 1 (по абсолютной величине) говорит о достаточно тесной линейной связи.
. Таким образом, близость коэффициента корреляции к 1 (по абсолютной величине) говорит о достаточно тесной линейной связи.
Коэффициенты корреляции типа 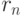 используются во многих алгоритмах многомерного статистического анализа эконометрических данных. В теоретических рассмотрениях часто считают, что случайный вектор имеет многомерное нормальное распределение. Распределения реальных данных, как правило, отличны от нормальных (см.
"Статистический анализ числовых величин (непараметрическая статистика)"
). Почему же распространено представление о многомерном нормальном распределении? Дело в том, что теория в этом случае проще. В частности, равенство 0 теоретического коэффициента корреляции (см. приложение 1) эквивалентно независимости случайных величин. Поэтому проверка независимости сводится к проверке статистической гипотезы о равенстве 0 теоретического коэффициента корреляции. Эта гипотеза принимается, если
используются во многих алгоритмах многомерного статистического анализа эконометрических данных. В теоретических рассмотрениях часто считают, что случайный вектор имеет многомерное нормальное распределение. Распределения реальных данных, как правило, отличны от нормальных (см.
"Статистический анализ числовых величин (непараметрическая статистика)"
). Почему же распространено представление о многомерном нормальном распределении? Дело в том, что теория в этом случае проще. В частности, равенство 0 теоретического коэффициента корреляции (см. приложение 1) эквивалентно независимости случайных величин. Поэтому проверка независимости сводится к проверке статистической гипотезы о равенстве 0 теоретического коэффициента корреляции. Эта гипотеза принимается, если 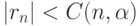 , где
, где 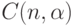 - некоторое граничное значение, зависящее от объема выборки n и уровня значимости
- некоторое граничное значение, зависящее от объема выборки n и уровня значимости  .
.
Если случайные вектора независимы и одинаково распределены, то выборочный коэффициент корреляции сходится к теоретическому при безграничном возрастании объема выборки:
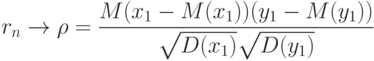
Более того, выборочный коэффициент корреляции является асимптотически нормальным. Это означает, что
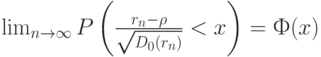
где 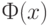 - функция стандартного нормального распределения с математическим ожиданием 0 и дисперсией 1, а
- функция стандартного нормального распределения с математическим ожиданием 0 и дисперсией 1, а 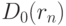 - асимптотическая дисперсия выборочного коэффициента корреляции. Она имеет довольно сложное выражение, приведенное в монографии [4, с.393]:
- асимптотическая дисперсия выборочного коэффициента корреляции. Она имеет довольно сложное выражение, приведенное в монографии [4, с.393]:
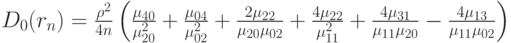
Здесь под  понимаются теоретические центральные моменты порядка
понимаются теоретические центральные моменты порядка 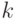 и , а именно,
и , а именно,
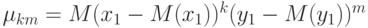
Для расчета непараметрического коэффициента ранговой корреляции Спирмена необходимо сделать следующее. Для каждого 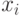 рассчитать его ранг
рассчитать его ранг 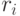 в вариационном ряду, построенном по выборке
в вариационном ряду, построенном по выборке 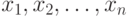 Для каждого
Для каждого  рассчитать его ранг
рассчитать его ранг  в вариационном ряду, построенном по выборке
в вариационном ряду, построенном по выборке 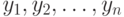 . Для набора из пар
. Для набора из пар 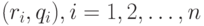 вычислить (линейный) коэффициент корреляции. Он называется коэффициентом ранговой корреляции, поскольку определяется через ранги. В качестве примера рассмотрим данные из табл.5.2(см. монографию [5]).
вычислить (линейный) коэффициент корреляции. Он называется коэффициентом ранговой корреляции, поскольку определяется через ранги. В качестве примера рассмотрим данные из табл.5.2(см. монографию [5]).
 |
1 | 2 | 3 | 4 | 5 |
|
5 | 10 | 15 | 20 | 25 |
|
6 | 7 | 30 | 81 | 300 |
|
1 | 2 | 3 | 4 | 5 |
|
1 | 2 | 3 | 4 | 5 |
Для данных табл.5.2 коэффициент линейной корреляции равен 0,83, непосредственной линейной связи нет. А вот коэффициент ранговой корреляции равен 1, поскольку увеличение одной переменной однозначно соответствует увеличению другой переменной. Во многих экономических задачах, например, при выборе инвестиционных проектов для осуществления, достаточно именно монотонной зависимости одной переменной от другой.
Поскольку суммы рангов и их квадратов нетрудно подсчитать, то коэффициент ранговой корреляции Спирмена равен
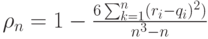
Отметим, что коэффициент ранговой корреляции Спирмена остается постоянным при любом строго возрастающем преобразовании шкалы измерения результатов наблюдений. Другими словами, он является адекватным в порядковой шкале (см. "Основы теории измерений" ), как и другие ранговые статистики (см. статистики Вилкоксона, Смирнова, типа омега-квадрат для проверки однородности независимых выборок в "Статистический анализ числовых величин (непараметрическая статистика)" и общее обсуждение в "Статистика нечисловых данных" ).
Широко используется также коэффициент ранговой корреляции Кендалла, коэффициент ранговой конкордации Кендалла и Б. Смита и др. Наиболее подробное обсуждение этой тематики содержится в монографии [6], необходимые для практических расчетов таблицы имеются в справочнике [1]. Дискуссия о выборе вида коэффициентов корреляции продолжается до настоящего времени [5].
Непараметрическая регрессия. Рассмотрим общее понятие регрессии как условного математического ожидания. Пусть случайный вектор 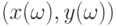 имеет плотность
имеет плотность 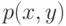 . Как известно из любого курса теории вероятностей, плотность условного распределения
. Как известно из любого курса теории вероятностей, плотность условного распределения 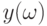 при условии
при условии 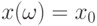 имеет вид
имеет вид

Условное математическое ожидание, т.е. регрессионная зависимость, имеет вид
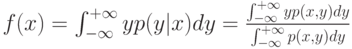
Таким образом, для нахождения оценок регрессионной зависимости достаточно найти оценки совместной плотности распределения вероятности 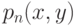 такие, что
такие, что
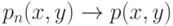
при Тогда непараметрическая оценка регрессионной зависимости
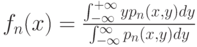
при будет состоятельной оценкой регрессии как условного математического ожидания
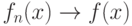
Общий подход к построению непараметрических оценок плотности распределения вероятностей развит в "Статистика нечисловых данных" ниже.
Михаил Агапитов
Подобед Александр
|
Я нажал кнопку "начать курс" и почти его уже закончил, но для получения диплома на бумаге, нужно его же оплатить? Как оплатить? |