|
Не могу найти требования по оформлению выпускной контрольной работы по курсу профессиональной переподготовки "Менеджмент предприятия" |
Опубликован: 16.12.2009 | Доступ: свободный | Студентов: 2594 / 445 | Оценка: 4.26 / 4.23 | Длительность: 33:53:00
Темы: Экономика, Менеджмент
Специальности: Руководитель, Экономист
Лекция 5:
Многомерный статистический анализ
Проблема остановки возникает не только при построении диагностических классов. Она принципиально важна, в частности, и при оценивании параметров вероятностных распределений методом максимального правдоподобия. Обычно не представляет большого труда выписать систему уравнений максимального правдоподобия и предложить решать ее каким-либо численным методом. Однако когда остановиться, сколько итераций сделать, какая точность оценивания будет при этом достигнута? Общий ответ, видимо, невозможно найти, но обычно нет ответа и для конкретных семейств распределения вероятностей. Именно поэтому мы нет оснований рекомендовать решать системы уравнений максимального правдоподобия, вместо них целесообразно использовать т.н. одношаговые оценки (подробнее см. об этих оценках работу [12]). Эти оценки задаются конечными формулами, но асимптотически столь же хороши (на профессиональном языке - эффективны), как и оценки максимального правдоподобия.
О сравнении алгоритмов диагностики по результатам обработки реальных данных. Перейдем к этапу применения диагностических правил, когда классы, к одному из которых нужно отнести вновь поступающий объект, уже выделены.
В прикладных эконометрических исследованиях применяют различные методы дискриминантного анализа, основанные на вероятностно-статистических моделях, а также с ними не связанные, т.е. эвристические, использующие детерминированные методы анализа данных. Независимо от "происхождения", каждый подобный алгоритм должен быть исследован как на параметрических и непараметрических вероятностно-статистических моделях порождения данных, так и на различных массивах реальных данных. Цель исследования - выбор наилучшего алгоритма в определенной области применения, включение его в стандартные программные продукты, методические материалы, учебные программы и пособия. Но для этого надо уметь сравнивать алгоритмы по качеству. Как это делать?
Часто используют такой показатель качества алгоритма диагностики, как "вероятность правильной классификации" (при обработке конкретных данных - "частота правильной классификации"). Чуть ниже мы покажем, что этот показатель качества некорректен, а потому пользоваться им не рекомендуется. Целесообразно применять другой показатель качества алгоритма диагностики - оценку специального вида т.н. "расстояния Махаланобиса" между классами. Изложение проведем на примере разработки программного продукта для специалистов по диагностике материалов. Прообразом является диалоговая система "АРМ материаловеда", разработанная Институтом высоких статистических технологий и эконометрики для ВНИИ эластомерных материалов.
При построении информационно-исследовательской системы диагностики материалов (ИИСДМ) возникает задача сравнения прогностических правил "по силе". Прогностическое правило - это алгоритм, позволяющий по характеристикам материала прогнозировать его свойства. Если прогноз дихотомичен ("есть" или "нет"), то правило является алгоритмом диагностики, при котором материал относится к одному из двух классов. Ясно, что случай нескольких классов может быть сведен к конечной последовательности выбора между двумя классами.
Прогностические правила могут быть извлечены из научно-технической литературы и практики. Каждое из них обычно формулируется в терминах небольшого числа признаков, но наборы признаков сильно меняются от правила к правилу. Поскольку в ИИСДМ должно фиксироваться лишь ограниченное число признаков, то возникает проблема их отбора. Естественно отбирать лишь те их них, которые входят в наборы, дающие наиболее "надежные" прогнозы. Для придания точного смысла термину "надежный" необходимо иметь способ сравнения алгоритмов диагностики по прогностической "силе".
Результаты обработки реальных данных с помощью некоторого алгоритма диагностики в рассматриваемом случае двух классов описываются долями: правильной диагностики в первом классе  ; правильной диагностики во втором классе
; правильной диагностики во втором классе 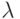 ; долями классов в объединенной совокупности
; долями классов в объединенной совокупности 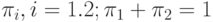
Величины 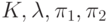 определяются ретроспективно.
определяются ретроспективно.
Нередко как показатель качества алгоритма диагностики (прогностической "силы") используют долю правильной диагностики
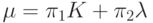
Однако показатель  определяется, в частности, через характеристики
определяется, в частности, через характеристики 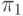 и?
и? 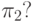 ? частично заданные исследователем (например, на них влияет тактика отбора образцов для изучения). В аналогичной медицинской задаче величина оказалась больше для тривиального прогноза (у всех больных течение заболевания будет благоприятно), чем для использованного в работе [13] группы под руководством академика АН СССР И.М. Гельфанда алгоритма выделения больных с прогнозируемым тяжелым течением заболевания, применение которого с медицинской точки зрения вполне оправдано. Другими словами, по доле правильной классификации алгоритм академика И.М. Гельфанда оказался хуже тривиального - объявить всех больных легкими, не требующими специального наблюдения. Этот вывод нелеп. И причина появления нелепости понятна. Хотя доля тяжелых больных невелика, но смертельные исходы сосредоточены именно в этой группе больных. Поэтому целесообразна гипердиагностика - рациональнее часть легких больных объявить тяжелыми, чем сделать ошибку в противоположную сторону. Применение теории статистических решений в рассматриваемой постановке вряд ли возможно, поскольку оценить количественно потери от смерти больного нельзя по этическим соображениям. Поэтому, на наш взгляд, долю правильной диагностики нецелесообразно использовать как показатель качества алгоритма диагностики.
? частично заданные исследователем (например, на них влияет тактика отбора образцов для изучения). В аналогичной медицинской задаче величина оказалась больше для тривиального прогноза (у всех больных течение заболевания будет благоприятно), чем для использованного в работе [13] группы под руководством академика АН СССР И.М. Гельфанда алгоритма выделения больных с прогнозируемым тяжелым течением заболевания, применение которого с медицинской точки зрения вполне оправдано. Другими словами, по доле правильной классификации алгоритм академика И.М. Гельфанда оказался хуже тривиального - объявить всех больных легкими, не требующими специального наблюдения. Этот вывод нелеп. И причина появления нелепости понятна. Хотя доля тяжелых больных невелика, но смертельные исходы сосредоточены именно в этой группе больных. Поэтому целесообразна гипердиагностика - рациональнее часть легких больных объявить тяжелыми, чем сделать ошибку в противоположную сторону. Применение теории статистических решений в рассматриваемой постановке вряд ли возможно, поскольку оценить количественно потери от смерти больного нельзя по этическим соображениям. Поэтому, на наш взгляд, долю правильной диагностики нецелесообразно использовать как показатель качества алгоритма диагностики.
Применение теории статистических решений требует знания потерь от ошибочной диагностики, а в большинстве научно-технических и экономических задач определить потери, как уже отмечалось, сложно. В частности, из-за необходимости оценивать человеческую жизнь в денежных единицах. По этическим соображениям это, на наш взгляд, недопустимо. Сказанное не означает отрицания пользы страхования, но, очевидно, страховые выплаты следует рассматривать лишь как способ первоначального смягчения потерь от утраты близких.
Для выявления информативного набора признаков целесообразно использовать метод пересчета на модель линейного дискриминантного анализа, согласно которому статистической оценкой прогностической "силы" является
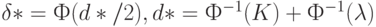
где 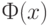 - функция стандартного нормального распределения вероятностей с математическим ожиданием 0 и дисперсией 1, а
- функция стандартного нормального распределения вероятностей с математическим ожиданием 0 и дисперсией 1, а 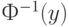 - обратная ей функция.
- обратная ей функция.
Если классы описываются выборками из многомерных нормальных совокупностей с одинаковыми матрицами ковариаций, а для классификации применяется классический линейный дискриминантный анализ Р.Фишера, то величина 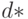 представляет собой состоятельную статистическую оценку так называемого расстояния Махаланобиса между рассматриваемыми двумя совокупностями (конкретный вид этого расстояния сейчас не имеет значения), независимо от порогового значения, определяющего конкретное решающее правило. В общем случае показатель
представляет собой состоятельную статистическую оценку так называемого расстояния Махаланобиса между рассматриваемыми двумя совокупностями (конкретный вид этого расстояния сейчас не имеет значения), независимо от порогового значения, определяющего конкретное решающее правило. В общем случае показатель 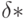 вводится как эвристический.
вводится как эвристический.
Пусть алгоритм классификации применяется к совокупности, состоящей из 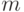 объектов первого класса и
объектов первого класса и  объектов второго класса.
объектов второго класса.
Теорема 2. Пусть 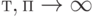 . Тогда для всех
. Тогда для всех 
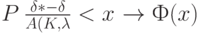
где 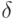 - истинная "прогностическая сила" алгоритма диагностики; - ее эмпирическая оценка,
- истинная "прогностическая сила" алгоритма диагностики; - ее эмпирическая оценка,
![A^2(K, \lambda)= \frac{1}{4} \left{ \left[\frac{\varphi (d*/2)}{ \varphi (Ф^{-1}(K))}\right]^2 \frac{K(1-K)}{m}+\left[\frac{\varphi (d*/2}{\varphi (Ф^{-1}(\lambda))}\right]^2 \frac{\lambda (1-\lambda)}{n} \right}](/sites/default/files/tex_cache/cd578361e029695281ab0557a29a673b.png)
 ) - плотность стандартного нормального распределения вероятностей с математическим ожиданием 0 и дисперсией 1.
) - плотность стандартного нормального распределения вероятностей с математическим ожиданием 0 и дисперсией 1.
С помощью теоремы 2 по и обычным образом определяют доверительные границы для "прогностической силы" .
Как проверить обоснованность пересчета на модель линейного дискриминантного анализа? Допустим, что классификация состоит в вычислении некоторого прогностического индекса  и сравнении его с заданным порогом
и сравнении его с заданным порогом  ; объект относят к первому классу, если
; объект относят к первому классу, если  , ко второму, если
, ко второму, если  . Возьмем два значения порога
. Возьмем два значения порога 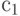 и
и 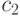 . Если пересчет на модель линейного дискриминантного анализа обоснован, то "прогностические силы" для обоих правил совпадают:
. Если пересчет на модель линейного дискриминантного анализа обоснован, то "прогностические силы" для обоих правил совпадают:  . Эту статистическую гипотезу можно проверить.
. Эту статистическую гипотезу можно проверить.
Пусть 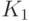 - доля объектов первого класса, для которых
- доля объектов первого класса, для которых  , а
, а 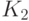 - доля объектов первого класса, для которых
- доля объектов первого класса, для которых 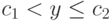 . Аналогично пусть
. Аналогично пусть 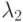 - доля объектов второго класса, для которых
- доля объектов второго класса, для которых 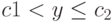 , а
, а 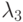 - доля объектов второго класса, для которых
- доля объектов второго класса, для которых 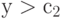 . Тогда можно рассчитать две оценки одного и того же расстояния Махаланобиса. Они имеют вид:
. Тогда можно рассчитать две оценки одного и того же расстояния Махаланобиса. Они имеют вид:
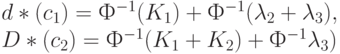
Теорема 3. Если истинные прогностические силы двух правил диагностики совпадают,  то при
то при 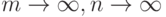 при всех
при всех

где
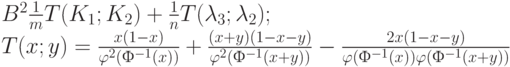
Из теоремы 3 вытекает метод проверки рассматриваемой гипотезы: при выполнении неравенства
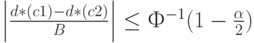
она принимается на уровне значимости, асимптотически равном  , в противном случае - отвергается.
, в противном случае - отвергается.
Подходы к построению прогностических правил. Для решения задач диагностики используют два подхода - параметрический и непараметрический. Первый из них обычно основан на использовании того или иного индекса и сравнения его с порогом. Индекс может быть построен по статистическим данным, например, как в уже упомянутом линейном дискриминантном анализе Фишера. Часто индекс представляет собой линейную функцию от характеристик, выбранных специалистами предметной области, коэффициенты которой подбирают эмпирически. Непараметрический подход связан с леммой Неймана-Пирсона в математической статистике и с теорией статистических решений. Он опирается на использование непараметрических оценок плотностей распределений вероятностей, описывающих диагностические классы.
Обсудим ситуацию подробнее. Математические методы диагностики, как и статистические методы в целом, делятся на параметрические и непараметрические. Первые основаны на предположении, что классы описываются распределениями из некоторых параметрических семейств. Обычно рассматривают многомерные нормальные распределения, при этом зачастую принимают гипотезу о том, что ковариационные матрицы для различных классов совпадают. Именно в таких предположениях сформулирован классический дискриминантный анализ Фишера. Как известно, обычно нет оснований считать, что наблюдения извлечены из нормального распределения.
Поэтому более корректными, чем параметрические, являются непараметрические методы диагностики. Исходная идея таких методов основана на лемме Неймана-Пирсона, входящей в стандартный курс математической статистики. Согласно этой лемме решение об отнесении вновь поступающего объекта (сигнала, наблюдения и др.) к одному из двух классов принимается на основе отношения плотностей 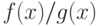 , где
, где 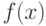 - плотность распределения, соответствующая первому классу, а
- плотность распределения, соответствующая первому классу, а 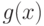 - плотность распределения, соответствующая второму классу. Если плотности распределения неизвестны, то применяют их непараметрические оценки, построенные по обучающим выборкам. Пусть обучающая выборка объектов из первого класса состоит из
- плотность распределения, соответствующая второму классу. Если плотности распределения неизвестны, то применяют их непараметрические оценки, построенные по обучающим выборкам. Пусть обучающая выборка объектов из первого класса состоит из 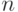 элементов, а обучающая выборка для второго класса - из
элементов, а обучающая выборка для второго класса - из 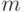 объектов. Тогда рассчитывают значения непараметрических оценок плотностей
объектов. Тогда рассчитывают значения непараметрических оценок плотностей  и
и 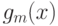 для первого и второго классов соответственно, а диагностическое решение принимают по их отношению. Таким образом, для решения задачи диагностики достаточно научиться строить непараметрические оценки плотности для выборок объектов произвольной природы.
для первого и второго классов соответственно, а диагностическое решение принимают по их отношению. Таким образом, для решения задачи диагностики достаточно научиться строить непараметрические оценки плотности для выборок объектов произвольной природы.
Методы построения непараметрических оценок плотности распределения вероятностей в пространствах произвольной природы рассмотрены в "Статистика нечисловых данных" .
Михаил Агапитов
Подобед Александр
|
Я нажал кнопку "начать курс" и почти его уже закончил, но для получения диплома на бумаге, нужно его же оплатить? Как оплатить? |