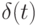 имеет вид
имеет вид|
Не могу найти требования по оформлению выпускной контрольной работы по курсу профессиональной переподготовки "Менеджмент предприятия" |
Опубликован: 16.12.2009 | Доступ: свободный | Студентов: 2618 / 462 | Оценка: 4.26 / 4.23 | Длительность: 33:53:00
Темы: Экономика, Менеджмент
Специальности: Руководитель, Экономист
Лекция 5:
Многомерный статистический анализ
Аннотация: В многомерном статистическом анализе выборка состоит из элементов многомерного пространства. Отсюда и название этого раздела эконометрических методов. Из многих задач многомерного статистического анализа рассмотрим две - восстановления зависимости и классификации.
Ключевые слова: переменная, переменные связи, метода наименьших квадратов, функция, ПО, производные, множитель, математическим ожиданием, нормальное распределение, статистическая гипотеза, остаточная сумма квадратов, статистика, погрешность, доверительная вероятность, Квантиль, значение, вероятностная модель, константы, разность, анализ, доказательство, доверительный интервал, дисперсия, тренд, алгоритм, индекс, линейное уравнение, регрессионный анализ, коэффициенты, производственная функция, свободными членами, таблица, параметр, минимум, многочлен, линейная функция, локальные минимумы, вероятность, регрессионными зависимостями, связь, коэффициент корреляции, приложение, вектор, представление, равенство, гипотеза, сходимость, выражение, ранг, шкала измерений, объект, бинарным отношением, множества, нечеткое множество, метрика, прикладная математика, распознавание, диагностика, сортировка, опыт, классификатор, разбиение, кластеризация, кластер, обучающая выборка, таксономия, кластерный анализ, отношение эквивалентности, статистический анализ, пункт, деление, определенность алгоритма, расстояние, дерево, предметной области, алгоритм k-средних, алгоритм ближайшего соседа, отрезок, устойчивость, дендрограмма, куча, математическая индукция, объединение, статистический критерий, статистические методы, метод статистических испытаний, структура данных, матрица, монотонно убывающей, правило проверки, центр кластера, вычисление, медиана, точность, АРМ, вывод, решающее правило, выборка
Оценивание линейной прогностической функции
Начнем с задачи точечного и доверительного оценивания линейной прогностической функции одной переменной.
Предполагается, что переменная x линейно зависит от переменной  , т.е.
, т.е.
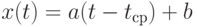
при некоторых значениях параметров 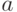 и
и 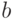 (величина
(величина 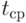 описана ниже). Это - теоретическая модель. А практически известны исходные данные - набор
описана ниже). Это - теоретическая модель. А практически известны исходные данные - набор  пар чисел
пар чисел 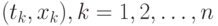 , где
, где 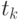 -- значения независимой переменной (например, времени), а
-- значения независимой переменной (например, времени), а 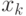 - значения зависимой переменной (например, индекса инфляции, курса доллара США, объема месячного производства или размера дневной выручки торговой точки). Предполагается, что переменные связаны зависимостью
- значения зависимой переменной (например, индекса инфляции, курса доллара США, объема месячного производства или размера дневной выручки торговой точки). Предполагается, что переменные связаны зависимостью
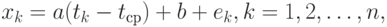
где и - параметры, неизвестные статистику и подлежащие оцениванию, а 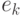 - погрешности, искажающие зависимость. Среднее арифметическое моментов времени
- погрешности, искажающие зависимость. Среднее арифметическое моментов времени
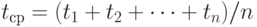
введено в модель для облегчения дальнейших выкладок.
Обычно оценивают параметры и линейной зависимости методом наименьших квадратов. Затем восстановленную зависимость используют для точечного и интервального прогнозирования.
Как известно, метод наименьших квадратов был разработан великим немецким математиком К. Гауссом в 1794 г. Согласно этому методу для расчета наилучшей функции, приближающей линейным образом зависимость  от , следует рассмотреть функцию двух переменных
от , следует рассмотреть функцию двух переменных
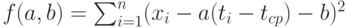
Оценки метода наименьших квадратов - это такие значения 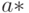 и
и 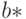 , при которых функция
, при которых функция 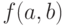 достигает минимума по всем значениям аргументов. Чтобы найти эти оценки, надо вычислить частные производные от функции по аргументам и , приравнять
достигает минимума по всем значениям аргументов. Чтобы найти эти оценки, надо вычислить частные производные от функции по аргументам и , приравнять
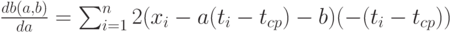
их 0, затем из полученных уравнений найти оценки: Имеем:
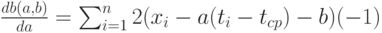
Преобразуем правые части полученных соотношений. Вынесем за знак суммы общие множители 2 и (-1). Затем рассмотрим слагаемые. Раскроем скобки в первом выражении, получим, что каждое слагаемое разбивается на три. Во втором выражении также каждое слагаемое есть сумма трех. Значит, каждая из сумм разбивается на три суммы. Имеем:
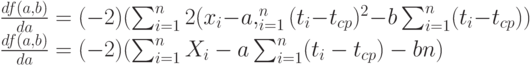
Приравняем частные производные 0. Тогда в полученных уравнениях можно сократить множитель (-2). Поскольку
 |
( 1) |
уравнения приобретают вид
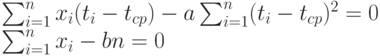
Следовательно, оценки метода наименьших квадратов имеют вид
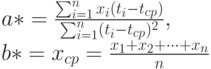 |
( 2) |
В силу соотношения (1) оценку 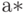 можно записать в более симметричном
можно записать в более симметричном
 |
( 3) |
виде:
Эту оценку нетрудно преобразовать и к виду
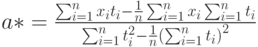 |
( 4) |
Следовательно, восстановленная функция, с помощью которой можно прогнозировать и интерполировать, имеет вид
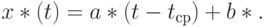
Обратим внимание на то, что использование в последней формуле ничуть не ограничивает ее общность. Сравним с моделью вида
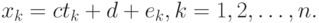
Ясно, что

Аналогичным образом связаны оценки параметров:

Для получения оценок параметров и прогностической формулы нет необходимости обращаться к какой-либо вероятностной модели. Однако для того, чтобы изучать погрешности оценок параметров и восстановленной функции, т.е. строить доверительные интервалы для 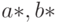 и
и  , подобная модель необходима.
, подобная модель необходима.
Непараметрическая вероятностная модель. Пусть значения независимой переменной детерминированы, а погрешности 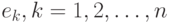 , - независимые одинаково распределенные случайные величины с нулевым математическим ожиданием и дисперсией
, - независимые одинаково распределенные случайные величины с нулевым математическим ожиданием и дисперсией 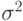 неизвестной статистику.
неизвестной статистику.
В дальнейшем неоднократно будем использовать Центральную Предельную Теорему (ЦПТ) теории вероятностей для величин (с весами), поэтому для выполнения ее условий необходимо предположить, например, что погрешности , финитны или имеют конечный третий абсолютный момент. Однако заострять внимание на этих внутриматематических "условиях регулярности" нет необходимости.
Асимптотические распределения оценок параметров. Из формулы (2) следует, что
 |
( 5) |
Согласно ЦПТ оценка имеет асимптотически нормальное распределение с математическим ожиданием и дисперсией 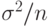 оценка которой приводится ниже.
оценка которой приводится ниже.
Из формул (2) и (5) вытекает, что
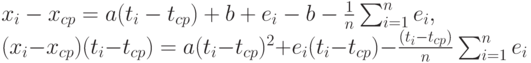
Последнее слагаемое во втором соотношении при суммировании по i обращается в 0, поэтому из формул (2-4) следует, что
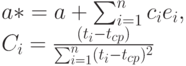 |
( 6) |
Формула (6) показывает, что оценка является асимптотически нормальной с математическим ожиданием и дисперсией
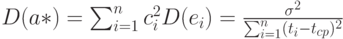
Отметим, что многомерная нормальность имеет быть, когда каждое слагаемое в формуле (6) мало сравнительно со всей суммой, т.е.

Из формул (5) и (6) и исходных предположений о погрешностях вытекает также несмещенность оценок параметров.
Несмещенность и асимптотическая нормальность оценок метода наименьших квадратов позволяют легко указывать для них асимптотические доверительные границы (аналогично границам в предыдущей лекции) и проверять статистические гипотезы, например, о равенстве определенным значениям, прежде всего 0. Предоставляем читателю возможность выписать формулы для расчета доверительных границ и сформулировать правила проверки упомянутых гипотез.
Асимптотическое распределение прогностической функции. Из формул (5) и (6) следует, что
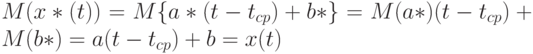
т.е. рассматриваемая оценка прогностической функции является несмещенной. Поэтому
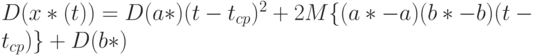
При этом, поскольку погрешности независимы в совокупности и 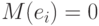 , то
, то
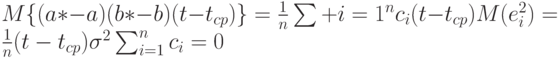
Таким образом,
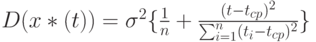
Итак, оценка  является несмещенной и асимптотически нормальной. Для ее практического использования необходимо уметь оценивать остаточную дисперсию
является несмещенной и асимптотически нормальной. Для ее практического использования необходимо уметь оценивать остаточную дисперсию 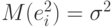
Оценивание остаточной дисперсии. В точках 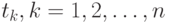 , имеются исходные значения зависимой переменной и восстановленные значения
, имеются исходные значения зависимой переменной и восстановленные значения 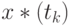 . Рассмотрим остаточную сумму квадратов
. Рассмотрим остаточную сумму квадратов

В соответствии с формулами (5) и (6)
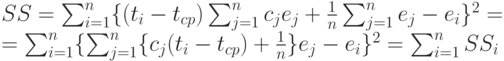
Найдем математическое ожидание каждого из слагаемых:
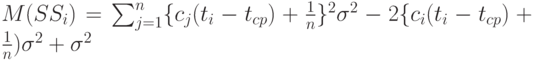
Из сделанных ранее предположений вытекает, что при 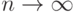 имеем
имеем 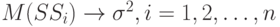 следовательно, по закону больших чисел статистика
следовательно, по закону больших чисел статистика  является состоятельной оценкой остаточной дисперсии .
является состоятельной оценкой остаточной дисперсии .
Получением состоятельной оценки остаточной дисперсии завершается последовательность задач, связанных с рассматриваемым простейшим вариантом метода наименьших квадратов. Не представляет труда выписывание верхней и нижней границ для прогностической функции:
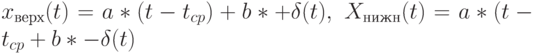
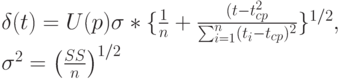
Здесь 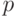 - доверительная вероятность,
- доверительная вероятность, 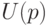 , как и в
"Статистический анализ числовых величин (непараметрическая статистика)"
- квантиль нормального распределения порядка
, как и в
"Статистический анализ числовых величин (непараметрическая статистика)"
- квантиль нормального распределения порядка 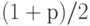 , т.е.
, т.е.
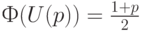
При 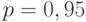 (наиболее применяемое значение) имеем
(наиболее применяемое значение) имеем  . Для других доверительных вероятностей соответствующие значения квантилей можно найти в статистических таблицах (см., например, наилучшее в этой сфере издание [1]).
. Для других доверительных вероятностей соответствующие значения квантилей можно найти в статистических таблицах (см., например, наилучшее в этой сфере издание [1]).
Сравнение параметрического и непараметрического подходов. Во многих литературных источниках рассматривается параметрическая вероятностная модель метода наименьших квадратов. В ней предполагается, что погрешности имеют нормальное распределение. Это предположение позволяет математически строго получить ряд выводов. Так, распределения статистик вычисляются точно, а не в асимптотике, соответственно вместо квантилей нормального распределения используются квантили распределения Стьюдента, а остаточная сумма квадратов  делится не на , а на
делится не на , а на 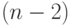 . Ясно, что при росте объема данных различия стираются.
. Ясно, что при росте объема данных различия стираются.
Рассмотренный выше непараметрический подход не использует нереалистическое предположение о нормальности погрешностей (см. начало "Статистический анализ числовых величин (непараметрическая статистика)" ).. Платой за это является асимптотический характер результатов. В случае простейшей модели метода наименьших квадратов оба подхода дают практически совпадающие рекомендации. Это не всегда так, не всегда два подхода бают близкие результаты. Напомним, что в задаче обнаружения выбросов методы, опирающиеся на нормальное распределение, нельзя считать обоснованными, и обнаружено это было с помощью непараметрического подхода (см. "Статистический анализ числовых величин (непараметрическая статистика)" ).
Общие принципы. Кратко сформулируем несколько общих принципов построения, описания и использования эконометрических методов анализа данных. Во-первых, должны быть четко сформулированы исходные предпосылки, т.е. полностью описана используемая вероятностно-статистическая модель. Во-вторых, не следует принимать предпосылки, которые редко выполняются на практике. В-третьих, алгоритмы расчетов должны быть корректны с точки зрения математико-статистической теории. В-четвертых, алгоритмы должны давать полезные для практики выводы.
Применительно к задаче восстановления зависимостей это означает, что целесообразно применять непараметрический подход, что и сделано выше. Однако предположение нормальности, хотя и очень сильно сужает возможности применения, с чисто математической точки зрения позволяет продвинуться дальше. Поэтому для первоначального изучения ситуации, так сказать, "в лабораторных условиях", нормальная модель может оказаться полезной.
Михаил Агапитов
Подобед Александр
|
Я нажал кнопку "начать курс" и почти его уже закончил, но для получения диплома на бумаге, нужно его же оплатить? Как оплатить? |