
|
Вы уверены, что строка верна? config vlan v2 add untagged 9-16 Как в таком случае пользователи v2 получат доступ к разделяемым ресурсам? По-моему, должно быть config vlan v2 add untagged 9-24 |
Московский государственный технический университет им. Н.Э. Баумана
Опубликован: 25.06.2013 | Доступ: свободный | Студентов: 4237 / 1048 | Длительность: 18:32:00
Тема: Сетевые технологии
Специальности: Архитектор программного обеспечения
Лекция 1:
Основы коммутации
Архитектура на основе коммутационной матрицы
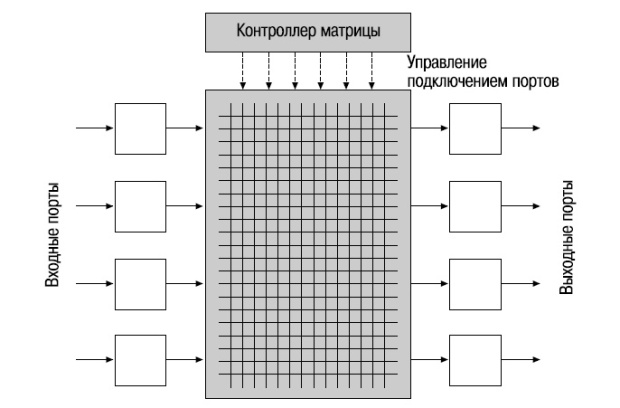
Параллельно с появлением архитектуры с разделяемой памятью (в середине 1990-х годов) была разработана архитектура на основе коммутационной матрицы (Crossbar architecture). Эта архитектура используется для построения коммутаторов различных типов.
Существует множество вариаций архитектуры этого типа. Базовая архитектура на основе коммутационной матрицы N х N непосредственно соединяет N входных портов с N выходными портами в виде матрицы. В местах пересечения проводников, соединяющих входы и выходы, находятся коммутирующие устройства, которыми управляет специальный контроллер. В каждый момент времени, анализируя адресную информацию, контроллер сообщает коммутирующим устройствам, какой выход должен быть подключен к какому входу. В том случае, если два входящих пакета от разных портов-источников будут переданы на один и тот же выходной порт, он будет заблокирован. Существуют различные подходы к решению этой проблемы: повышение производительности матрицы по сравнению с производительностью входных портов или использование буферов памяти и арбитров.
Несмотря на простой дизайн, одной из фундаментальных проблем архитектуры на основе коммутационной матрицы остается ее масштабируемость. При увеличении количества входов и выходов усложняется схемотехника матрицы и в особенности контроллера. Поэтому для построения многопортовых коммутационных матриц используется другой подход, который заключается в том, что простые коммутационные матрицы связываются между собой, образуя одну большую коммутационную матрицу.
Можно выделить два типа коммутаторов на основе коммутационной матрицы:
- коммутаторы на основе коммутационной матрицы с буферизацией (buffered crossbar);
- коммутаторы на основе коммутационной матрицы с арбитражем (arbitrated crossbar).
Коммутаторы на основе коммутационной матрицы с буферизацией
В коммутаторах на основе коммутационной матрицы с буферизацией буферы расположены на трех основных стадиях: на входе и выходе и непосредственно на коммутационной матрице. Благодаря наличию очередей на трех стадиях эта архитектура позволяет избежать сложностей, связанных с реализацией механизма централизованного арбитража. На выходе каждой из стадий осуществляется управление очередями с помощью одного из алгоритмов диспетчеризации.
Несмотря на то, что эта архитектура является простейшей архитектурой коммутаторов, из-за независимости стадий для нее существуют сложности с реализацией качества обслуживания (QoS) в пределах коммутатора.
Коммутаторы на основе коммутационной матрицы с арбитражем
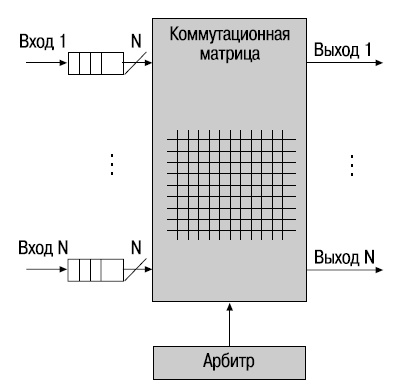
Эта архитектура характеризуется наличием безбуферных коммутирующих элементов и арбитра, который управляет передачей трафика между входами и выходами матрицы. Отсутствие буферов у коммутирующих элементов компенсируется наличием буферов входных и выходных портов. Обычно разработчики используют один из трех методов буферизации: выходные буферы, входные буферы, комбинированные входные и выходные буферы.
В коммутаторах с входными очередями (Input-Queued Switch) память каждого входного порта организована в виде очереди типа FIFO (First Input First Output — "первым пришел, первым ушел"), которая используется для буферизации пакетов перед началом процесса коммутации. Одной из проблем этого типа коммутационной матрицы является блокировка первым в очереди (Head-Of-Line blocking, HOL). Она возникает в том случае, когда коммутатор пытается одновременно передать пакеты из нескольких входных очередей на один выходной порт. При этом пакеты, находящиеся в начале этих очередей, блокируют все остальные пакеты, находящиеся за ними. Для принятия решения о том, какой пакет и из какой очереди может получить доступ к матрице, используется арбитр. Перед передачей пакета входные порты направляют арбитру запросы на подключение к разделяемому ресурсу (в данном случае — пути матрицы) и получают от него право на подключение.
Арбитр принимает решение о последовательности передачи пакетов из входных очередей на основе алгоритма диспетчеризации (scheduling algorithm).
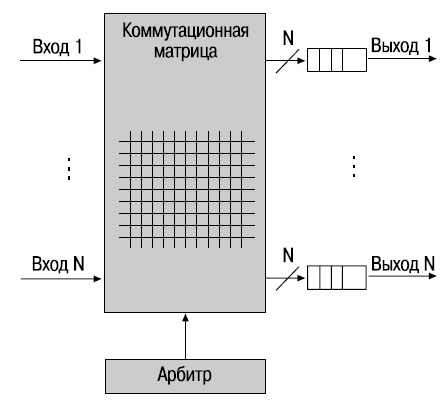
В коммутаторах с выходными очередями (output-queued switch) пакеты буферизируются только на выходных портах после завершения процесса коммутации. В этом случае удается избежать проблемы, связанной с блокированием очередей HOL. Коммутаторы этой архитектуры используют арбитр для управления временем, за которое пакеты коммутируются через матрицу. При правильно разработанном арбитре коммутаторы с выходными очередями могут обеспечивать качество обслуживания (QoS).
Следует отметить, что выходной буфер каждого порта требует большего объема памяти по сравнению с входным буфером. Это позволяет избежать блокирования на выходе, когда все входные порты пытаются подключиться к одному выходу. Еще одним важным фактором является скорость выполнения операции "запись" коммутируемых пакетов в выходную очередь. По этим двум причинам архитектура с выходными очередями должна быть реализована на высокоскоростных элементах, что делает ее очень дорогостоящей.
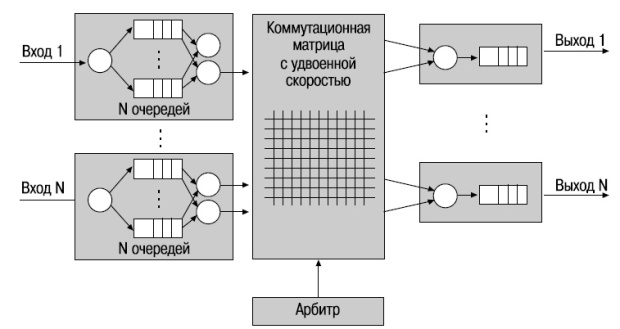
Коммутаторы с виртуальными очередями (Virtual Output Queues, VOQ) позволяют преодолеть проблему блокировки очередей HOL, не внося издержек по сравнению с коммутаторами с выходными очередями. В этой архитектуре память каждого входного порта организована в виде N (где N — количество выходных портов) логических очередей типа FIFO, по одной для каждого выходного порта. Эти очереди используются для буферизации пакетов, поступающих на входной порт и предназначенных для выходного порта j (j = 1,…N).
В том случае, если существует несколько виртуальных очередей, может возникнуть проблема, связанная с одновременным доступом к коммутационной матрице и блокировкой очередей. Для решения этой проблемы используется арбитр, который на основе алгоритма диспетчеризации выбирает пакеты из разных очередей.
В коммутаторах с комбинированными входными и выходными очередями (Combined Input and Output Queued, CIOQ) буферы памяти подключены как к входным, так и к выходным портам. Память каждого из входных портов организована в виде N виртуальных выходных очередей типа FIFO, по одной для каждого выходного порта. Каждый из N выходных портов также содержит очередь типа FIFO, которая используется для буферизации пакетов, ожидающих передачи через него. Система коммутации работает по принципу конвейера, каждая стадия которого называется временным слотом (time slot). В течение временного слота 1, который называется стадией прибытия, пакеты поступают на входные порты. Для передачи внутри коммутатора все пакеты сегментируются на ячейки фиксированного размера. Размер такой ячейки данных определяется производителем коммутатора. Каждая ячейка снабжается меткой с указанием размера, номера входного порта и порта назначения и помещается в виртуальную выходную очередь соответствующего выходного порта. Входные порты отправляют "запросы на подключение к выходам" централизованному арбитру, а все выходные порты отправляют ему "информацию о перегрузке" (переполнении выходных буферов).
Во временной слот 2, который называется стадией диспетчеризации, ячейки передаются из входных очередей в выходные. Последовательность передачи ячеек определяется централизованным арбитром с помощью алгоритма диспетчеризации. Для того чтобы выходные очереди быстро заполнялись пакетами из входных очередей (с целью уменьшения задержки передачи пакетов и обеспечения QoS), алгоритм диспетчеризации должен обеспечивать циклическое высокоскоростное сопоставление входных и выходных очередей. Это сопоставление используется для настройки управляемых переключателей матрицы перед передачей пакетов с входов на выходы.
Во временной слот 3, который называется стадией передачи, осуществляется сборка пакетов и их передача с выходных портов.
Сергей Некрасов
Антон Донсков
|
Есть ли какой-либо эмулятор DES-3200-28 т.к. читать то это читать, а практика оно лучше, а за неимением железки, которая для простого смертного все таки денег стоит, как то тоскливо.... |